Liferay Commerce 性能:我们如何将 SKU 导入规模扩展至 10 万以上(且未导致 JVM 崩溃)
Source: Dev.to
如果你为任何严肃的 B2B 客户实施过 Liferay Commerce 7.4,你一定深有体会。
开发阶段一切顺利。你用包含 500 条记录的 CSV 测试产品导入逻辑,速度快、响应灵敏,效果完美。随后进入 UAT(或更糟的生产环境)。客户交给你真实的主数据文件——5 万、10 万,甚至 25 万 SKU。你点击 Import,随后……一片寂静。
- 日志不再输出。
- CPU 占用飙升至 100%。
- UI 卡死。
- 最终出现令人恐惧的
java.lang.OutOfMemoryError或事务超时。
我们在 Nirvana Lab 已经见过这种情形不计其数。事实是,批量产品导入是企业电商中最被低估的性能挑战。
在本文中,我将跳过营销噱头,直接带你了解我们用于在 40 分钟内处理 10 万+ SKU 的高性能导入架构——稳定、可重复且不会崩溃。
“便利陷阱”:为何开箱即用的导入会失败
在修复之前,我们必须先弄清楚默认做法为何会出问题。
大多数开发者(包括我自己,在早期阶段)都会先编写一个简单的服务,遍历 CSV 并对每一行调用 CPDefinitionLocalService。
问题不在代码本身,而在 架构上下文。
1. 单体事务
默认情况下,Liferay 会尝试将整个请求包装在一个事务中。如果你有 50 k 条目,就相当于让数据库在回滚段中保留 50 k 条未提交的插入。
2. Hibernate 会话膨胀
Hibernate 喜欢缓存。随着遍历进行,每一个 CPDefinition 对象都会停留在 一级缓存(堆内存)中。由于事务尚未关闭,它们不会被垃圾回收。
3. 索引风暴
这是潜在的致命因素。每当你添加一个产品时,Indexer 就会启动,去更新 Elasticsearch/Solr。同步执行 100 000 次这种操作等同于性能自杀。
结果: 系统在小型目录下运行良好,但一旦达到企业规模就会崩溃。
修复方案:分块、异步和延迟
要让 高性能 B2B 目录 正常运行,我们拆除了默认的同步模型,改用我们称之为 “分块‑提交‑延迟” 的模式。
下面是我们为制造业客户部署的生产级架构。
架构(时序图)
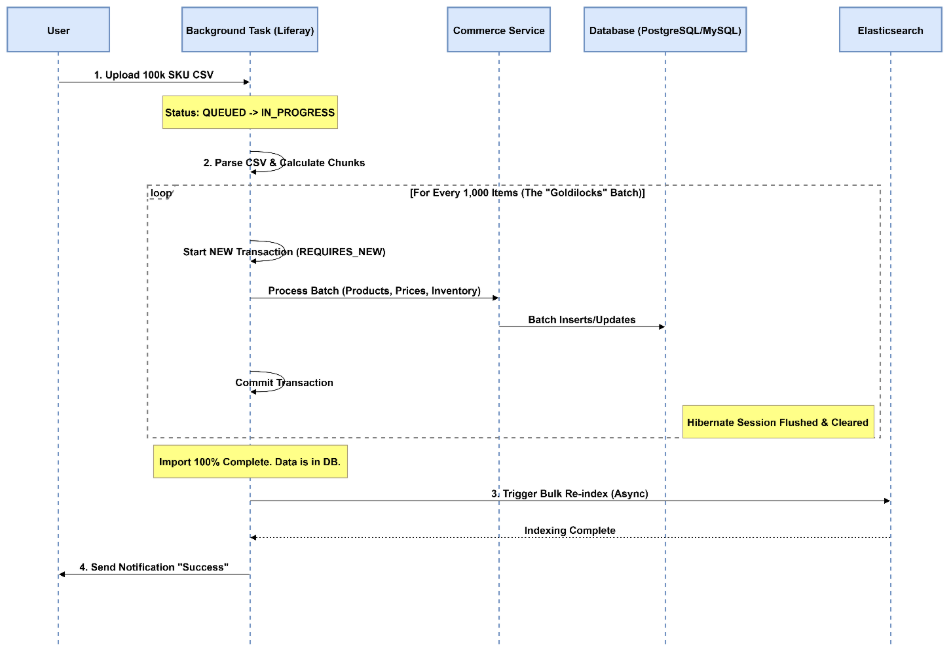
该图展示了流程。请注意我们如何将“巨型事务”拆分为小块,并将繁重的工作(索引)留到最后执行。
步骤实施指南
1. 摆脱请求线程
切勿在主 HTTP 线程上进行批量导入。如果浏览器断开或负载均衡器超时,导入会陷入僵尸状态。
我们使用 Liferay 的 BackgroundTaskExecutor 框架。它提供集群安全(如果某个节点挂掉,另一个节点会接管)以及内置的状态报告。
@Component(
property = "background.task.executor.class.name=com.nirvanalab.commerce.task.ProductImportTaskExecutor",
service = BackgroundTaskExecutor.class
)
public class ProductImportTaskExecutor extends BaseBackgroundTaskExecutor {
// Implementation logic here...
}2. “金发姑娘”分块策略
我们不会把整个列表一次性交给处理器,而是将其切片。
通过在 Liferay DXP 7.4 上的大量基准测试,我们发现 500 – 1 000 条商品的批次大小是最佳平衡点。
| 批量大小 | 效果 |
|---|---|
| ** 5 000** | Hibernate 脏检查的开销呈指数增长 |
// Background Task 中的“外层循环”
public void executeImport(List allRows) {
int batchSize = 1_000;
for (int i = 0; i batch = allRows.subList(i, end);
// 这里才是真正的魔法
_batchService.processBatchInNewTransaction(batch);
// 帮助垃圾回收器
batch.clear();
}
}注意: Batch Engine 是大规模导入的首选现代方案。
3. 事务隔离(秘密酱料)
每个批次必须 立即 提交到数据库。如果仅仅调用一个方法,它可能会继承父事务。使用 Propagation.REQUIRES_NEW 强制开启新物理事务。
@Transactional(propagation = Propagation.REQUIRES_NEW)
public void processBatchInNewTransaction(List batch) {
for (ProductRow row : batch) {
// 创建商品,设置价格,设置库存 …
}
// 方法退出时,数据库提交,Hibernate 刷新。
// 内存被释放。
}4. 延迟索引
如果你尝试逐个为 100 k 条商品建立索引,导入将耗时约 5 小时。
在导入过程中我们 禁用 自动重建索引的触发器(使用 IndexerWriterHelper,或在可用时将模型特定的索引设置为延迟/批处理模式)。数据会以“暗”状态写入数据库(不可搜索)。循环结束后,我们手动触发一次优化的批量重建索引。
// 仅在循环结束后运行此代码
Indexer indexer = IndexerRegistryUtil.getIndexer(CPDefinition.class);
indexer.reindex(new String[] { "companyId" }); // 示例 – 根据你的范围进行适配回顾
| 步骤 | 您需要做的事 |
|---|---|
| 1 | 将导入工作卸载到后台任务。 |
| 2 | 将 CSV 切分为每块 500‑1 000 行。 |
| 3 | 为每个块包装一个独立的 REQUIRES_NEW 事务。 |
| 4 | 禁用逐行索引;在所有块完成后执行批量重新索引。 |
通过遵循此 Chunk‑Commit‑Defer 模式,您可以可靠地将 数十万 SKU 导入 Liferay Commerce 7.4,而不会出现 OOM 错误、超时或 UI 卡死。
祝导入顺利!
etIndexer(CPDefinition.class);
indexer.reindex(CPDefinition.class.getName(), companyId);结果:前后对比
我们最近为一家大型汽车零部件分销商部署了此架构,使用 Liferay Commerce。差异显著,犹如天壤之别。

故障排除:实战经验
即使采用了此架构,我们仍然遇到了一些边缘情况。以下是两个需要注意的 陷阱:
-
死锁受害者
如果你尝试花哨地在并行线程中运行块,可能会在 CPInstance 或 Inventory 表上遭遇数据库死锁。**我们的建议:**坚持使用 单线程顺序块。速度已经足够,复杂性只会产生错误。
-
媒体陷阱
不要在同一事务中导入高分辨率产品图片和元数据。处理二进制文件会消耗堆内存。**我们的建议:**先执行 数据阶段(SKU、价格、库存),然后再单独进行 媒体阶段 来附加图片。
最后思考
扩展 Liferay Commerce 并不是通过投入更多硬件来解决问题,而是要尊重数据库和 JVM 的物理特性。
通过将单体拆分为多个块并控制事务边界,您可以将脆弱的导入过程转变为稳健的企业级数据管道。
在 Liferay 性能方面遇到困难?在 Nirvana Lab,我们专注于解决高规模制造和零售实施中“无法修复”的性能问题。