如何构建你的第一个 AI 代理并将其部署到 Sevalla
Source: Dev.to
Just a few years ago, writing code that could talk, decide, or use external data felt hard.
如今,得益于新工具,开发者可以构建能够读取信息、进行推理并自行调用函数的智能代理。
One such platform that makes this easy is LangChain. With LangChain you can link language models, tools, and apps together, wrap your agent inside a FastAPI server, and push it to a cloud platform for deployment.
其中一个让这变得简单的平台是 LangChain。使用 LangChain,您可以将语言模型、工具和应用程序链接在一起,将代理封装在 FastAPI 服务器中,并将其推送到云平台进行部署。
This article will walk you through building your first AI agent. You will learn what LangChain is, how to build an agent, how to serve it through FastAPI, and how to deploy it on Sevalla.
本文将带您一步步构建第一个 AI 代理。您将了解 LangChain 是什么、如何构建代理、如何通过 FastAPI 提供服务,以及如何在 Sevalla 上部署它。
什么是 LangChain
LangChain 是一个用于处理大型语言模型的框架。它帮助你构建能够 思考、推理和行动 的应用。
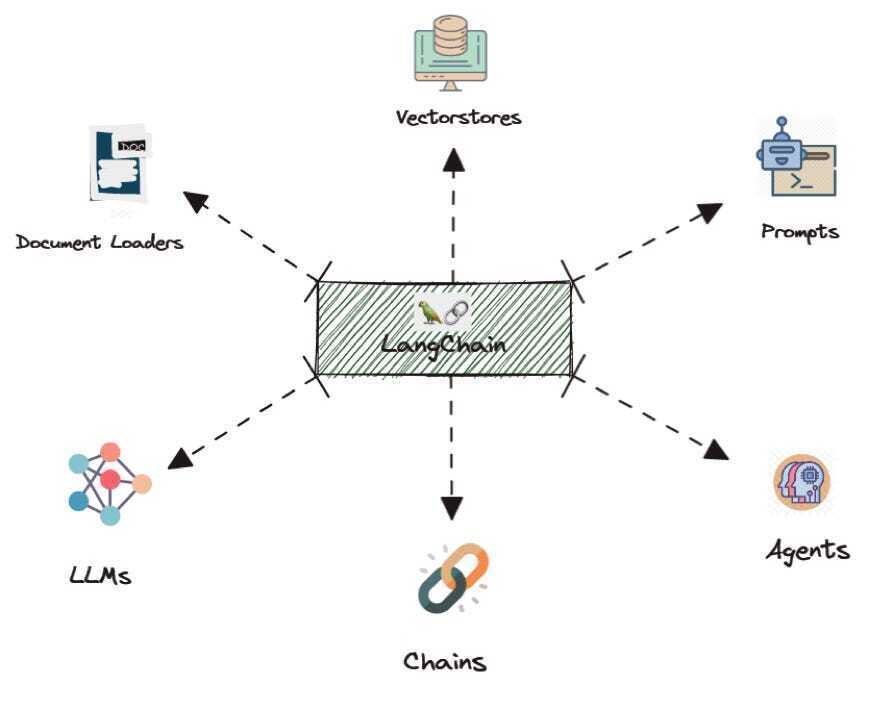
单独的模型只能给出文本回复,但 LangChain 让它能够做更多:调用函数、使用工具、连接数据库以及遵循工作流。
把 LangChain 想象成一座桥梁:
- 一侧: 语言模型。
- 另一侧: 你的工具、数据源和业务逻辑。
LangChain 告诉模型有哪些工具、何时使用它们以及如何回复。这使得它非常适合构建能够回答问题、自动化任务或处理复杂流程的代理。
- 灵活 – 支持多种 AI 模型。
- Python 为先 – 自然融入大多数数据科学和后端堆栈。
- 生产就绪 – 一旦你学会创建代理,就可以将该模式复用于更高级的用例。
我最近在此发布了详细的 LangChain 教程。
构建你的第一个 LangChain 代理
让我们创建一个简单的代理,它可以回答用户的问题,并在需要时 调用工具。我们将给它一个虚拟的天气工具,并询问某个城市的天气。
-
创建一个名为
.env的文件,并添加你的 OpenAI API 密钥(LangChain 会自动读取):OPENAI_API_KEY= -
编写代理代码:
from langchain.agents import create_agent from dotenv import load_dotenv # Load environment variables load_dotenv() # Define a tool that the LLM can call def get_weather(city: str) -> str: """Get weather for a given city.""" return f"It's always sunny in {city}!" # Create the agent agent = create_agent( model="gpt-4o", tools=[get_weather], system_prompt="You are a helpful assistant" ) # Invoke the agent result = agent.invoke( {"messages": [{"role": "user", "content": "What is the weather in San Francisco?"}]} ) print(result)
发生了什么?
create_agent在指定的模型上构建一个代理。get_weather是一个 工具——代理可以调用的 Python 函数。- 系统提示告诉代理它的角色。
agent.invoke发送用户消息;代理决定是否调用get_weather并返回回复。
即使这个例子非常简短,它也捕捉了核心概念:代理读取自然语言,决定使用哪个工具,调用该工具,然后作出回应。
使用 FastAPI 包装您的代理
现在我们将通过 HTTP 端点公开代理,以便其他服务能够与之交互。FastAPI 让这一步变得非常简单。
-
安装所需的包:
pip install fastapi uvicorn python-dotenv langchain -
创建
main.py:from fastapi import FastAPI from pydantic import BaseModel import uvicorn from langchain.agents import create_agent from dotenv import load_dotenv import os load_dotenv() # 定义工具 def get_weather(city: str) -> str: """获取指定城市的天气。""" return f"It's always sunny in {city}!" # 创建代理 agent = create_agent( model="gpt-4o", tools=[get_weather], system_prompt="You are a helpful assistant", ) app = FastAPI() class ChatRequest(BaseModel): message: str @app.get("/") def root(): return {"message": "Welcome to your first agent"} @app.post("/chat") def chat(request: ChatRequest): result = agent.invoke( {"messages": [{"role": "user", "content": request.message}]} ) # 响应格式可能会有所不同,请根据需要进行调整 reply = result["messages"][-1].content if "messages" in result else str(result) return {"reply": reply} def main(): port = int(os.getenv("PORT", 8000)) uvicorn.run(app, host="0.0.0.0", port=port) if __name__ == "__main__": main()
工作原理
GET /– 简单的健康检查。POST /chat– 接收 JSON{ "message": "你的问题?" },将其转发给 LangChain 代理,并返回代理的回复。
运行服务器:
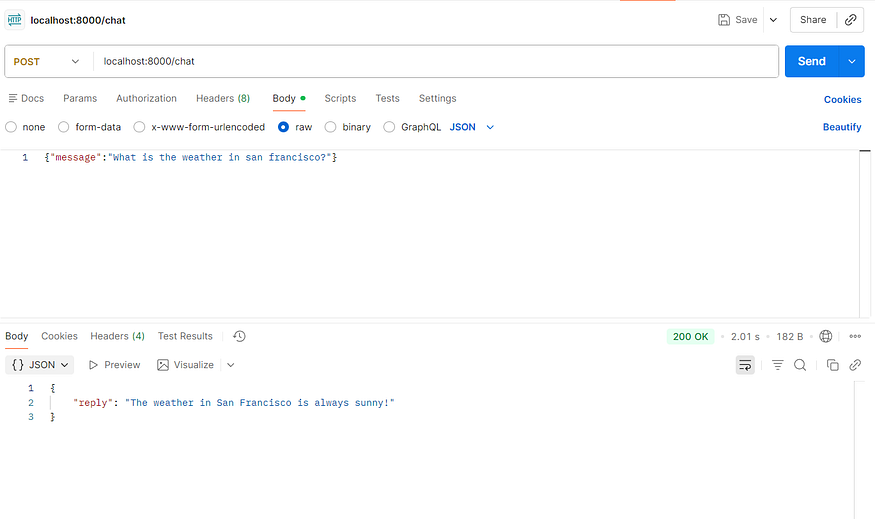
python main.py现在你可以使用 curl、Postman 等工具向 http://localhost:8000/chat 发送请求,获取可能调用自定义工具的 AI 生成答案。
后续步骤
- 用真实的 API 调用替换示例
get_weather函数。 - 添加更多工具(例如数据库查询、外部服务)。
- 将 FastAPI 应用部署到云平台,例如 Sevalla 或任何容器编排服务。
FastAPI 定义了 /chat 端点。当有人发送消息时,服务器调用我们的代理。代理像以前一样处理消息,FastAPI 返回干净的 JSON 回复。API 层将复杂性隐藏在一个简单的接口后面。
此时,你已经拥有一个可运行的代理服务器。你可以在本机上运行它,使用 Postman 或 cURL 调用,并检查响应。当一切正常后,就可以准备部署了。
部署到 Sevalla
您可以选择任何云服务提供商——AWS、DigitalOcean 等——来托管您的代理。在本示例中我们使用 Sevalla。
Sevalla 是一个面向开发者的 PaaS,提供应用托管、数据库、对象存储和静态站点托管。每个平台都会对云资源收费,但 Sevalla 提供 $50 的额度,因此本演示不会产生费用。
将项目推送到 GitHub
将代码库推送到 GitHub 并启用自动部署,这样任何新更改都会自动部署。您也可以 fork 原始仓库。
- 登录 Sevalla。
- 前往 Applications → Create new application 并关联您的 GitHub 仓库。
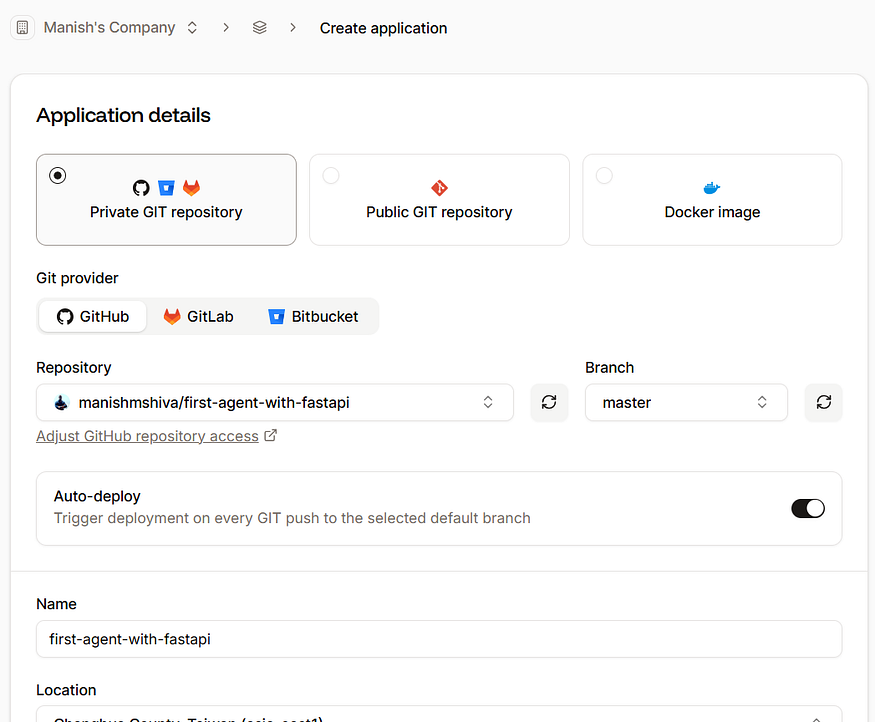
使用默认设置,点击 Create application。
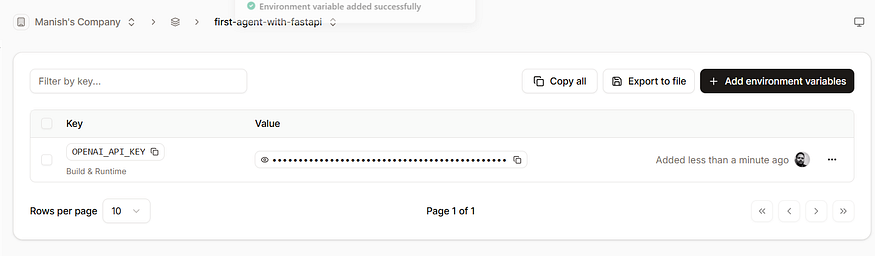
添加环境变量
应用创建完成后,前往 Environment variables 并添加您的 OpenAI 密钥:
| Variable | Value |
|---|---|
OPENAI_API_KEY | your‑openai‑api‑key |
部署
-
前往 Deployments → Deploy now。
部署大约需要 2–3 分钟。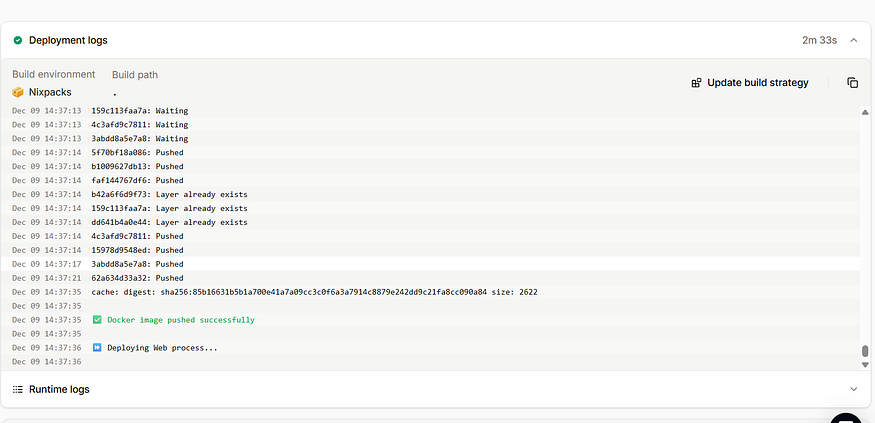
-
构建完成后,点击 Visit app。
您会看到服务运行在以sevalla.app结尾的 URL 上。将 Postman 或其他客户端中的localhost:8000替换为该 URL。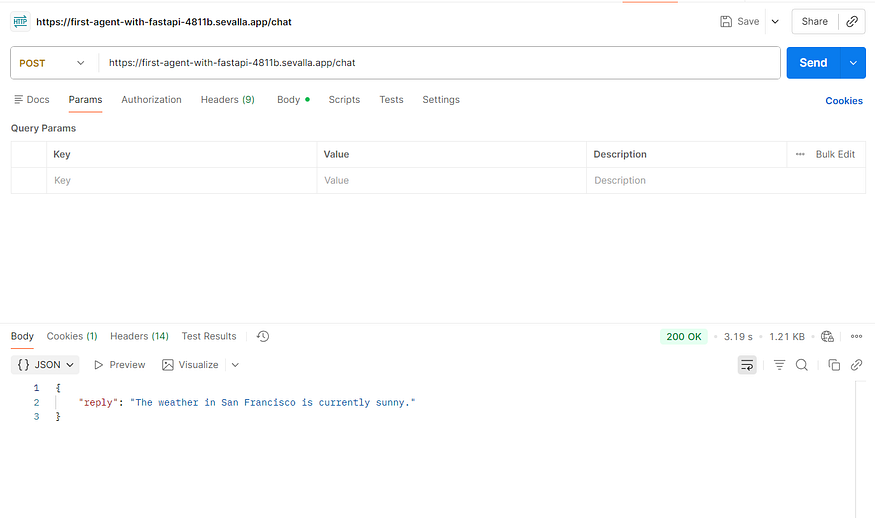
恭喜! 您的首个具备工具调用功能的 AI 代理已上线。您可以通过添加更多工具、推送更新到 GitHub 来扩展它,Sevalla 将自动重新部署。
结论
构建 AI 代理不再是专家专属的任务。使用 LangChain,只需几行代码即可创建能够响应用户并自主调用函数的推理工具。
将代理包装在 FastAPI 中,为其提供一个干净的 HTTP 接口,供应用和用户访问。最后,Sevalla 让将代理推向生产、监控以及快速迭代变得轻而易举。
这段从想法到部署服务的旅程,展示了现代 AI 开发的全貌。先从小处开始,探索工具,将其封装、部署,然后迭代、添加功能,并接入真实世界的服务。不久之后,你就会拥有一个在线的智能、活跃的代理。这就是当今 AI 热潮的力量。