我如何在我们的数据中发现了1,370名欺诈者(并为公司节省了51,000美元)
Source: Dev.to – How I found 1,370 fraudsters hiding in our data and saved my company $51,000
请提供您希望翻译的完整文本(文章正文),我将把它翻译成简体中文并保持原有的 Markdown 格式、代码块和链接不变。谢谢!
第一个线索:当数字讲述故事
打开数据的感觉就像在观察两个截然不同的世界。
- 信用卡交易: 仅有 0.5 % 的案例出现欺诈——在一片绿色海洋中的微小红点。
- 电商平台: 接近 每三笔交易中就有一笔 是欺诈。
我记得当时在想,
“我们怎么还能继续经营?”
那时我制作了第一个可视化——并排的柱状图展示了鲜明的差异。直观地看到后,问题变得真实起来;它不再只是数字,而是一个亟待关注的模式。
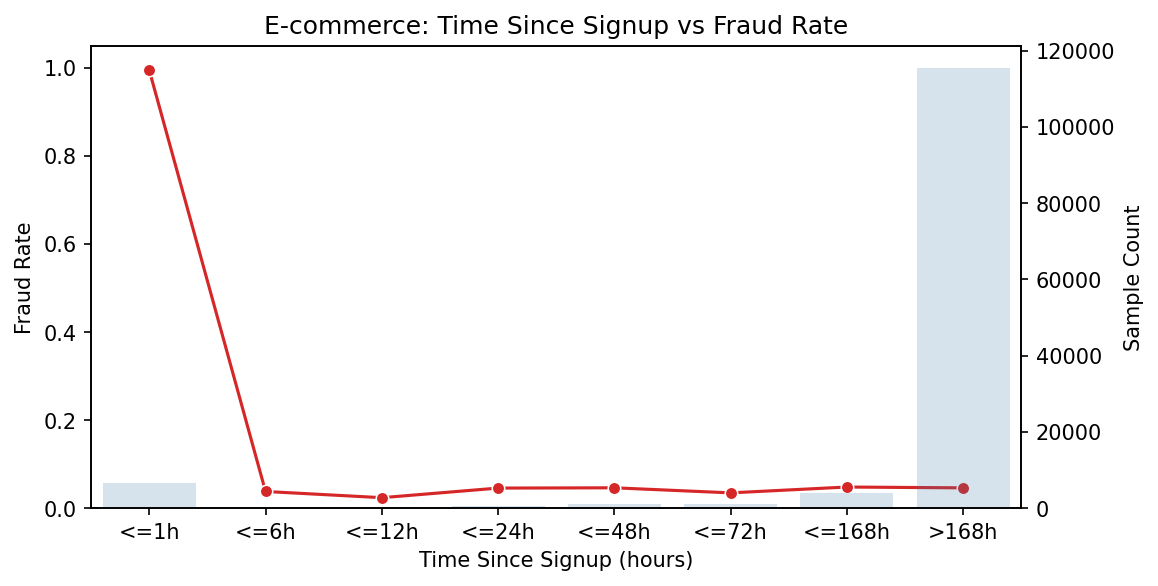
突破:1 小时规则
它起初只是一个直觉:“如果欺诈者行动很快会怎样?”
我创建了一个简单的计算:账户创建到首次购买之间的小时数。当我绘制出来时,我的咖啡已经凉了。
结果出现了——一开始就出现了巨大的峰值。第一小时内的交易拥有 99.5 % 的欺诈率——共 6 685 起“注册、盗窃、消失”的案例。
可视化图像看起来像一座山,峰顶被压到了最左侧。它如此清晰、如此显而易见。我们怎么会错过它?
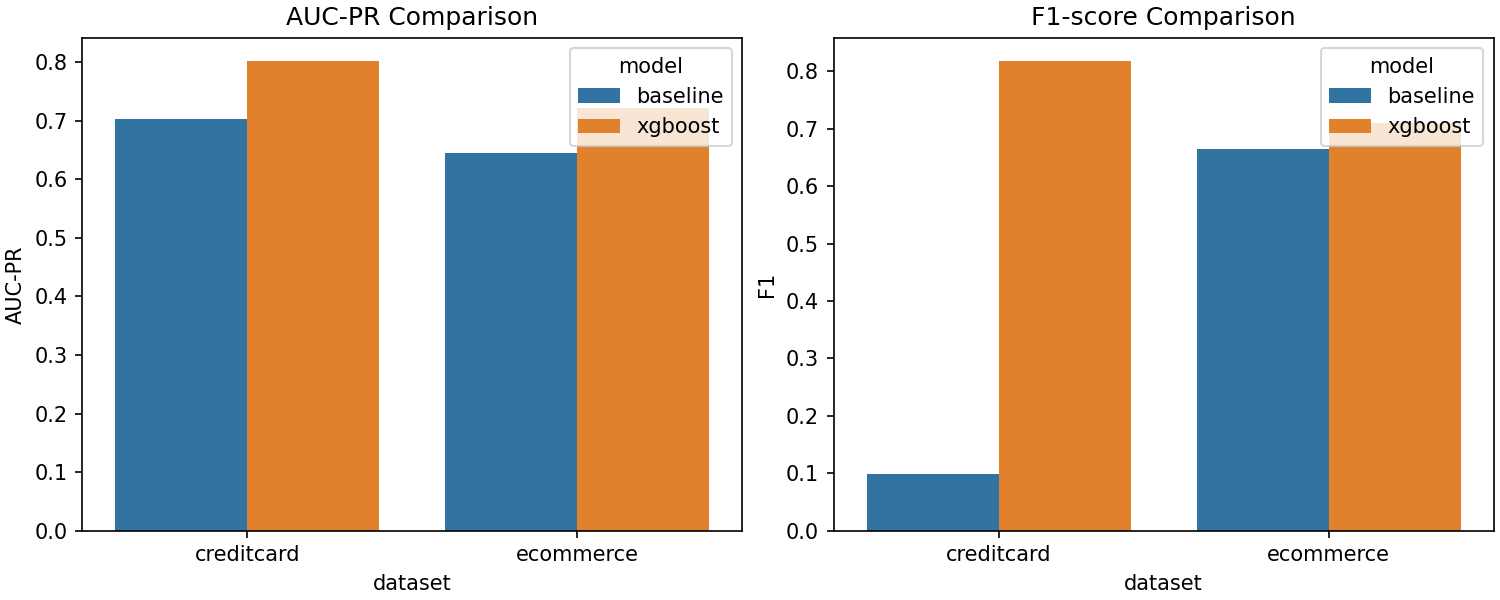
构建欺诈捕手
| 渠道 | 模型 | 原因 | 结果 |
|---|---|---|---|
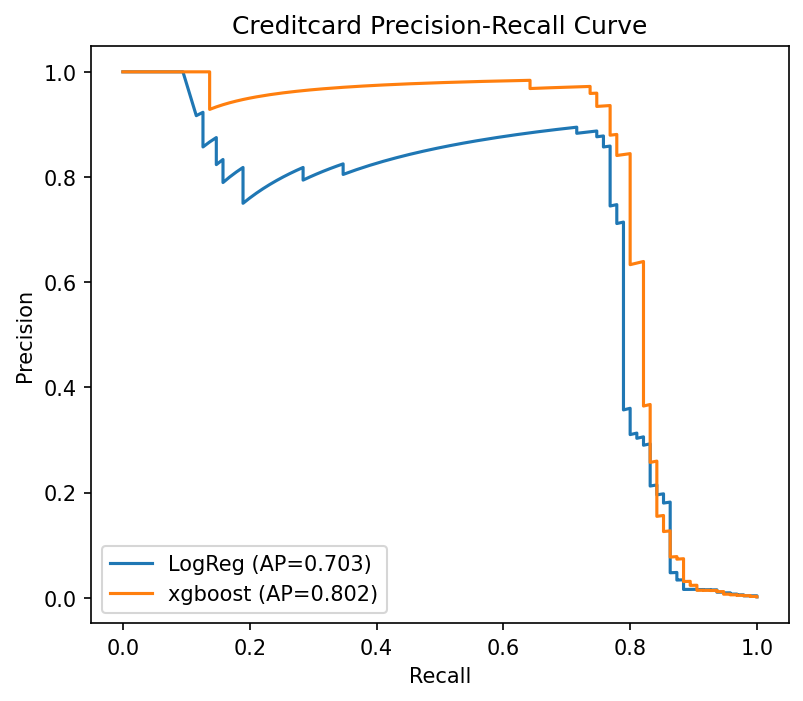
| 信用卡 | XGBoost | 强大的集成模型,能够学习复杂的交互关系 | 捕获 76 名欺诈者,误报 15 起 |
| 电子商务 | Logistic Regression | 高可解释性,适用于面向客户的决策 | 捕获 1 370 起欺诈(相较于可能的 1 409 起),并提供清晰解释 |
我的模型比较图表说明了这一点——不同的问题需要不同的工具。
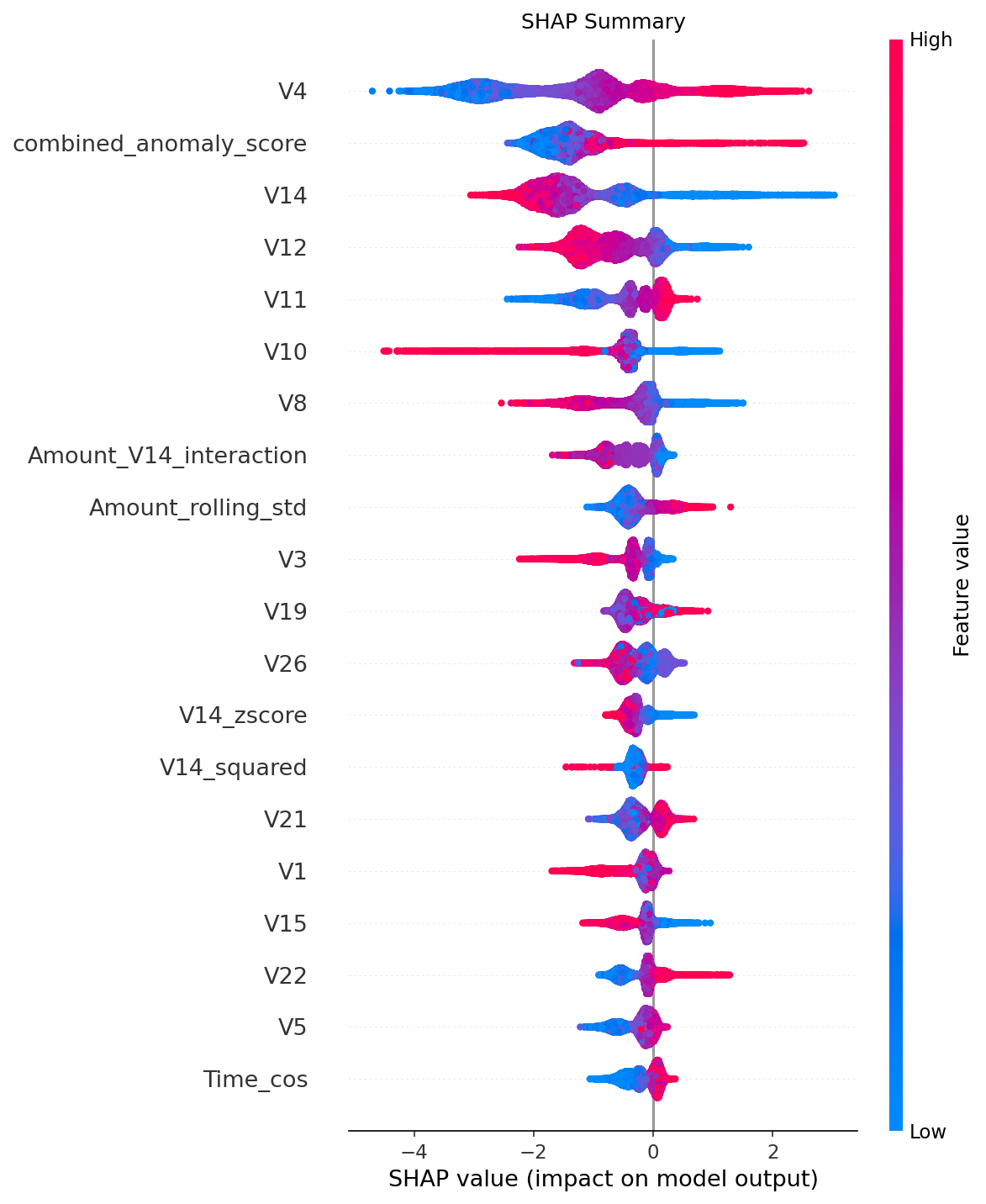
最吸引人的部分:问 “为什么?”
使用 SHAP 的感觉就像戴上了 X 光眼镜。突然之间,我能看到模型在想什么。
- 最重要的预测因子并不是我预料的那样。一个匿名的 V4 特征最为关键,其次是我们的自定义异常得分。
- 模型在我甚至没有关注的地方发现了模式。
真正的魔力在于具体案例。对一起被捕获的 $257 欺诈案件的 SHAP 力量图让我精准追溯原因——时间点、一个奇怪的 V14 值以及新账户。这不是魔法,而是我们可以解释的数学。
从洞察到行动:我们正在进行的三项变更
-
The 1‑Hour Checkpoint
从周一开始,任何在注册后一小时内完成的购买都会触发一次温和的额外验证步骤(例如,“嘿,请确认是您本人吗?”)。根据我们的数据,仅此一步就能阻止数千次欺诈尝试。 -
Smarter Geography
我们发现某些国家的欺诈率异常高(比如 Turkmenistan 达到 100 %)。我们不会采用一刀切的封锁,而是加入智能审查:合法客户顺利通过,欺诈者则遭遇阻拦。 -
Dynamic Decisions
我们的混淆矩阵显示需要采用不同的策略。- Credit‑card channel: 优先精确度 — 在标记前确保万无一失。
- E‑commerce channel: 优先召回率 — 捕获更多欺诈,同时保持可解释性。
业务影响(或:我如何证明我的薪资合理)
让我们谈谈数字
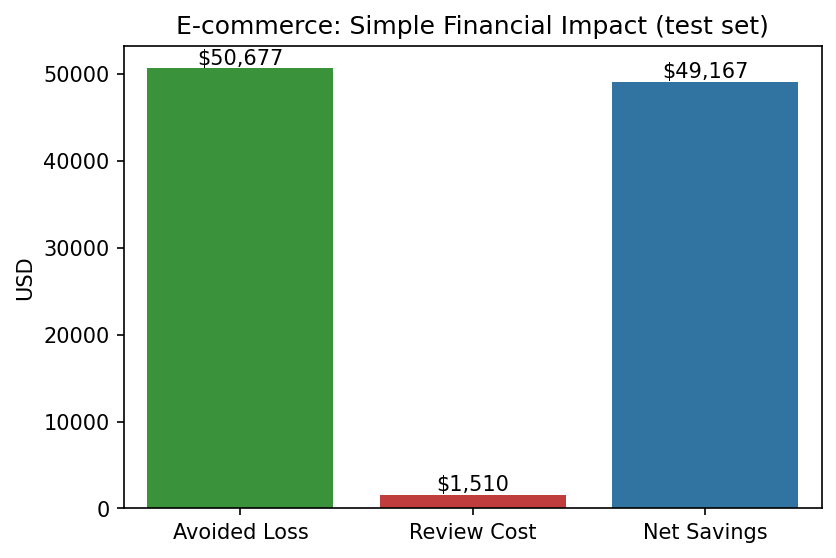
- 测试数据影响: 节省 $51,000
- 月度预测: $200,000+
- 年度潜力: 数百万
但这不仅仅是金钱——信任很重要。我们现在可以准确告诉客户他们的交易为何被标记,消除“系统说了算”的黑箱感受。
财务影响可视化在 10 秒 内向管理层阐明了我的论点。
我当时希望知道的事
- 简单胜过复杂 – 1 小时规则不需要机器学习来发现。
- 可解释性很重要 – 逻辑回归在电子商务中获胜,因为我们可以为其辩护。
- 欺诈者会适应 – 今日的模式会成为明日的历史。
重大的领悟
最有价值的洞见并不在于花哨的算法,而在于提出一个简单的问题:
“有人注册后会立刻发生什么?”
有时,最强大的数据科学就是提出显而易见的问题,并且有勇气相信答案,即使它们看起来过于简单而不真实。
想看看我们是怎么做到的吗?
代码、困难与庆祝全部在这里:
给你的问题: 你在数据中发现的最惊人的模式是什么?
本项目期间的咖啡消耗:47 杯 ☕
后悔:零