Agentforce 如何在每月 4610 亿次执行中使用受限 DSL 实现精准流程生成
Source: Salesforce Engineering
By Shipra Shreyasi, Aniket Kumar, Manas Agarwal, and Pragya Kumari
在我们的 Engineering Energizers 问答系列中,我们会聚焦推动 Salesforce 创新的工程人才。今天我们聚光灯对准 Shipra Shreyasi,她是一位软件工程架构师,负责领导团队提升 Agentforce 中自然语言到 Flow 的创建能力。该功能让用户仅通过简单的口述,就能生成可投入生产的 Flow 元数据,同时管理超过 461 0 亿次 的月度执行规模。
了解 Shipra 的团队如何通过将微调模型替换为受限的多层 DSL 框架来提升自然语言到 Flow 的精度,以及他们如何通过专门的约束和分阶段验证,在 63+ 种 Flow 类型(包括屏幕 Flow、UI 元素和独特操作)上保持可靠性。
您的团队在 Agentforce 中构建准确的自然语言到 Flow 生成方面的使命是什么?
该团队通过使用大语言模型将自然语言指令转换为 Flow 元数据,简化了创建、修改和理解自动化的方式。此过程使您能够直接在 Flow Builder 中部署业务逻辑,并期望每个自动化任务都能完全按照预期运行。
准确性仍然是核心关注点,因为 Flow 是关键的运营资产。由于未能准确反映意图的 Flow 可能会引入隐藏错误,团队将以下核心需求置于优先位置:
- 正确性
- 可调试性
- 可靠性
这种视角将 Flow 生成从单纯的文本任务转变为结构化的工程解决方案。通过应用显式约束和系统感知推理,团队帮助您以最小的人工投入构建复杂的自动化,并对最终结果充满信心。
Shipra 分享了她在 Salesforce 坚持下去的动力。
微调模型在自然语言到 Flow 生成中引入了哪些准确性和意图对齐约束?
微调模型带来了准确性障碍,随着 Flow 复杂度的提升,这些障碍变得愈发明显。虽然这些模型能够生成有效的元数据,但它们常常遗漏请求背后的真实意图。这导致一个 Flow 在上线后,未能执行最初描述的具体任务。
适应性同样难以实现。这些模型难以处理你的独特定制,例如自定义 Apex 动作或特定的 HTTP 调用。此方式导致了若干持续性问题:
- 重新训练周期增加了系统回归的风险。
- 故障诊断几乎变得不可能。
- 错误隐藏在单一且复杂的流程中。
归根结底,这些限制使得难以确保准确性。由于模型以单体方式运行,团队无法判断故障是发生在规划阶段还是最终生成阶段。这种透明度的缺失阻碍了系统在大规模下提供可靠且与意图对齐的自动化。
什么架构约束推动了从微调模型到受约束的多阶段 DSL 用于 Flow 生成的转变?
架构转变的重点在于确保结果确定性并消除幻觉。标准模型往往会出现语义漂移和无效数据组合,而这种新结构通过对元数据和 Flow 类型的严格规则来强制执行约束。
团队用 模块化的多阶段流水线 替代了旧的单体方法。该系统将生成过程拆分为具有明确验证关卡的专门阶段。全新的 领域特定语言(DSL) 精确定义系统能够构建的内容,从而在无效构造出现之前就将其阻止。
新模型通过以下方法将设计与实现分离:
- Architect 阶段 – 首先解决规划和结构。
- Developer 阶段 – 负责低层元数据的生成。
- Validation – 在每个阶段都进行,以防止错误。
这种分阶段的方法通过强制约束来确保准确性,而不是事后修正错误。
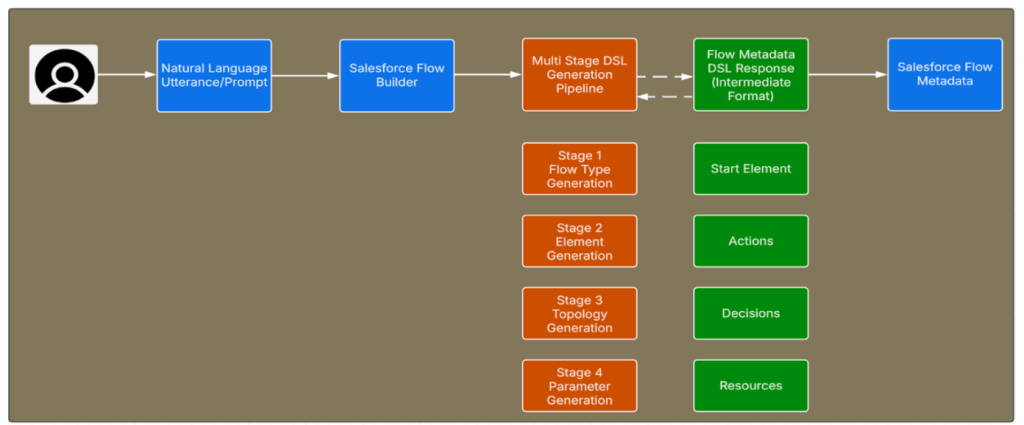
使用多阶段 DSL 生成流水线的 Agentforce 自然语言提示,用于 Flow 生成
从微调模型训练和发布流水线中出现了哪些创新速度限制?
微调模型带来了运营开销,减慢了创新速度。支持新的 Flow 类型或修复正确性问题需要组装数据集、重新训练模型,并经过一系列顺序测试环境。这些步骤意味着即使是小的改动也常常需要 数月 才能到达用户手中。
这种缓慢的节奏使得难以响应不断演变的平台需求。准确性的提升取决于模型发布的时间表,而不是工程意图;而更改 Flow 架构则需要反复进行重新训练循环。
团队通过转向 基于 DSL 的架构并使用开源大语言模型,消除了重新训练的需求。此转变使团队能够通过确定性的规则更新来处理正确性修复和架构更改。现在,准确性能够持续改进,而不必等待不频繁且高风险的发布。
随着 Flow 架构和 Flow 类型在 Salesforce 发行版中扩展,出现了哪些元数据演进约束?
Flow 在大规模环境下运行。它支持超过 63 种不同的 Flow 类型,并且其架构会随每个版本而演进。每种类型都有各自的执行语义和启动配置,这在过去使得手动生成方法极其脆弱,难以维护。
团队通过 直接从 Flow 元数据自动化生成 DSL 解决了这一问题,确保任何架构更改都会立即反映在 DSL 约束和验证逻辑中。这种方法使系统与平台同步前进,在引入新 Flow 功能时保持正确性和可靠性。
定义
这些构造现在通过 Flow Metadata WSDL 程序化生成。此方法确保生成规则始终反映平台模式。随着平台引入新功能,DSL 会自动演进。
因为 DSL 从权威元数据中提取信息,系统能够与实际运行时行为保持一致。此更改消除了模式漂移错误的风险,并且能够让 Flow 生成的准确性随平台自然扩展。
Shipra 重点介绍她团队最喜爱的 AI 工具。
在支持诸如 Screen Flows、UI 组件和自定义操作等复杂 Flow 类型时,出现了哪些正确性约束?
复杂的 Flow 类型带来了超出静态元数据的正确性挑战。Screen Flows 充当用户界面,需要准确的组件选择和响应式行为。自定义操作则通过引入特定语义,进一步增加了模型难以可靠预测的难度。
起始元素也充当多态组件。它们包含的字段会根据 Flow 类型而变化。单一的生成方法往往无法处理这些差异,导致配置错误或无效。
受约束的 DSL 架构通过在每个阶段强制特定规则来解决此问题。管道会实时选择有效元素并验证元数据,还会调用动态 API 解析组织的具体细节。这些步骤确保即使在复杂的 UI 驱动场景中也能保持准确性。
Shipra 解释为何工程师应加入 Salesforce。
在证明受约束的 DSL 架构提升了 Flow 准确性时,你面临了哪些测量和评估挑战?
衡量准确性需要超出简单观察的手段。人工审查难以规模化,诸如成功保存等基本指标也不足以证明 Flow 符合用户意图。
团队通过构建自动化评估框架来解决此问题。该系统使用数百个提示和 Flow‑as‑a‑Judge 模型来测试结果。框架在三个具体维度上评估每个生成的 Flow:
- 成功保存
- 激活准备度
- 与用户意图的一致性
通过对相同提示使用不同方法进行测试,团队能够直接比较结果。受约束的 DSL 方法在 Screen Flows 等复杂类型上显示出更高的保真度。该框架提供了量化证据,证明架构转变提升了准确性。
了解更多
- 保持联系 — 加入我们的 Talent Community!
- 查看我们的 Technology and Product 团队,了解如何参与。