GCC vs Clang:相同指令,不同性能(AGU Insight)
发布: (2026年3月28日 GMT+8 02:01)
3 分钟阅读
原文: Dev.to
Source: Dev.to
Introduction
我在进行 GCC 与 Clang 基准测试时注意到一些有趣的现象。
- 相同的代码。相同的机器。
- 两个循环都是标量的(没有向量化)。
然而 GCC 始终使用更少的 CPU 周期。
乍一看这似乎说不通。如果两者:
- 执行的大致相同的指令
- 都没有向量化
为什么会出现性能差距?
The Missing Piece: It’s Not Just Instructions
大多数人关注的都是:
- 指令数量
- 向量化
但在本例中,这并不是全部。
真正更重要的是:
- 地址计算的组织方式
- 指令的调度方式
- 延迟隐藏得有多好
下面是数据:
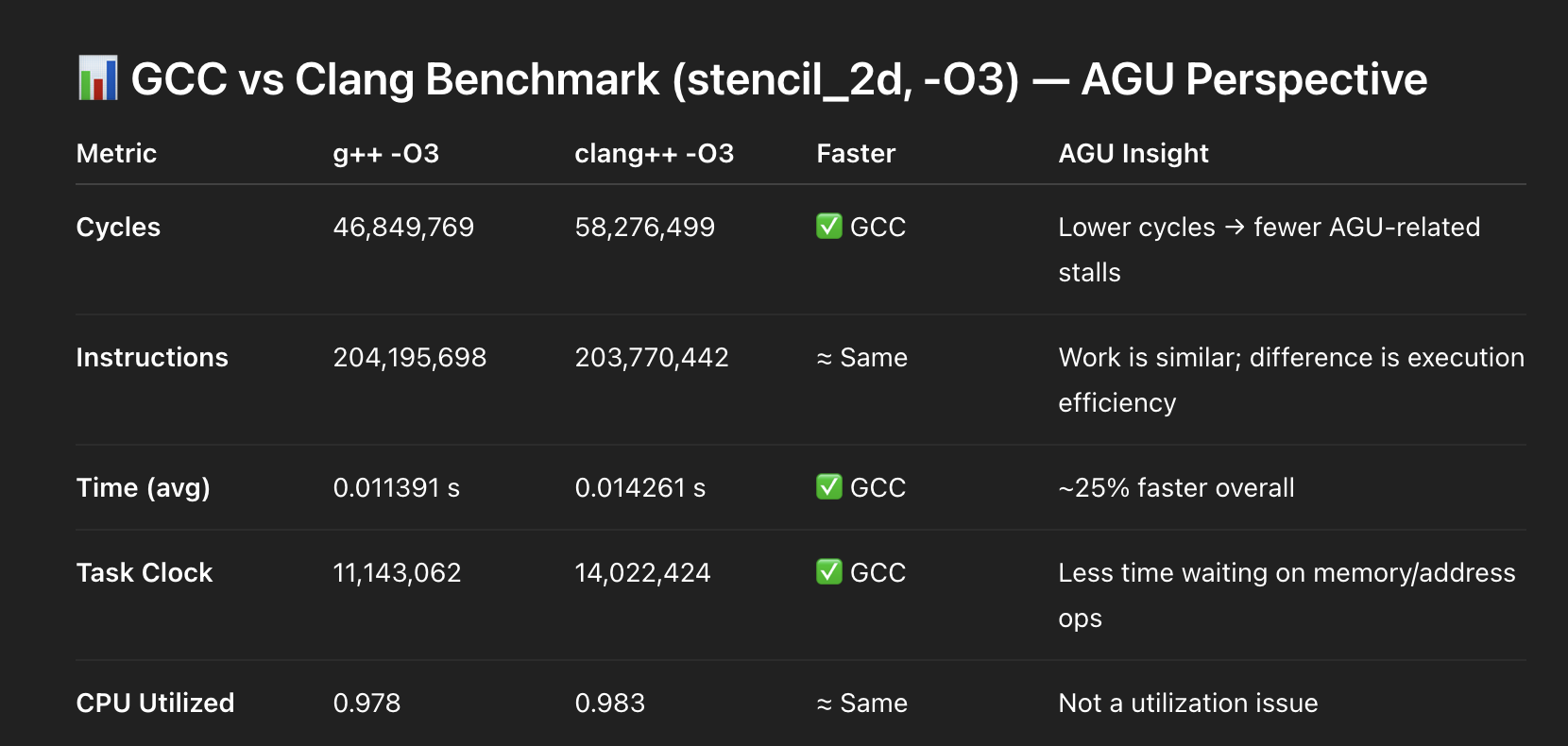
AGU Pressure (Address Generation Units)
在 x86 CPU 上,内存指令依赖 AGU(地址生成单元)。
像下面这种复杂的寻址模式:
base + index * scale + offset👉 会增加 AGU 压力
而更简单的模式,例如:
pointer++👉 更便宜,CPU 更容易高效执行
What I Observed
GCC
- 生成更简单的寻址模式
- 减少 AGU 争用
- 让执行更平稳
Clang
- 显示出更高的 AGU 压力
- 更多停顿
- 调度效率较低(在本例中)
Key Takeaway
关键不在于有哪些指令,而在于 编译器向 CPU 流水线提供指令的效率。
相同的指令计数 ≠ 相同的性能。
Why This Matters
在紧凑循环中,以下因素的影响可以和向量化一样大,甚至更大:
- AGU 压力
- 寻址模式
- 指令调度
Want to Dive Deeper?
Discussion
你是否遇到过类似的情况:即使汇编代码相似、指令数量相同,性能却相差甚远?欢迎分享你的观察。