从 ChatGPT 到 Gemini:我们如何为 Odoo 构建 GDPR 合规的 CV Parser
Source: Dev.to


背景
几年前,法国的一位企业主联系了我们,寻求帮助将他们的工作流程数字化。该公司专注于为 Work‑Study Programs(在法国称为 Alternance)招聘人员。
Alternance 是一种制度,学生在学校和工作之间分配时间。它之所以有吸引力,是因为学生能够:
- 免费获得学位
- 获得真实的工作经验
- 按照法国最低工资(SMIC)领取薪水
该机构充当专业的中间人,处理单个主体可能难以应付的流程。他们的工作流程如下:
- Finding Candidates – 为工作‑学习项目寻找学生或求职者。
- Screening – 面试申请者,确保他们符合官方政府标准(年龄、教育背景等)。
- Matching with Employers – 为需要学徒的公司寻找合适人选并发送最佳简历。
- Handling Paperwork – 管理复杂的行政步骤,并在公司决定雇用后确保合同签署。
简而言之,他们在学徒和雇主之间搭建桥梁,使整个过程对所有人都更加顺畅。
瓶颈:手动数据录入
在联系之前,团队使用笔记本和电子表格。我们为他们构建了一个完整的招聘流水线,基于 Odoo Community Recruitment module 并通过自定义模块扩展,以匹配他们的特定工作流程。
新系统让公司能够在一个地方跟踪所有内容:
- 申请人和公司的数据库
- 招聘阶段
- 预约
- 自动邮件/短信通知
- 日历集成
- 数字合同签署
该解决方案取得了成功,但仍有一个主要痛点:数据录入。招聘人员仍需寻找简历并手动将其输入流水线,才能开始工作。业务所有者感到沮丧——招聘人员花费数小时进行手动录入,而不是去挖掘人才。
我们决定使用 AI 来实现自动化。
设计自动化工作流
我们最初的想法是构建一个 API,让第三方能够直接向 Odoo 发送数据,但数据源尚未准备好。于是我们决定通过电子邮件接收所有求职者的简历(带 PDF 附件的普通邮件)。在专用邮箱设置完成后,我们设计了以下工作流:
- 读取邮件 – 登录邮件服务提供商并获取未读邮件。
- 提取附件 – 下载附件的简历(通常为 PDF)。
- OCR 处理 – 进行光学字符识别以提取原始文本。
- AI 解析 – 使用大语言模型将原始文本转换为结构化的 JSON 格式。
- Odoo 集成 – 使用 Odoo XML‑RPC 在招聘模块中创建记录,并附上原始 PDF 以供参考。
- 分配 – 自动将线索分配给空闲的招聘人员。

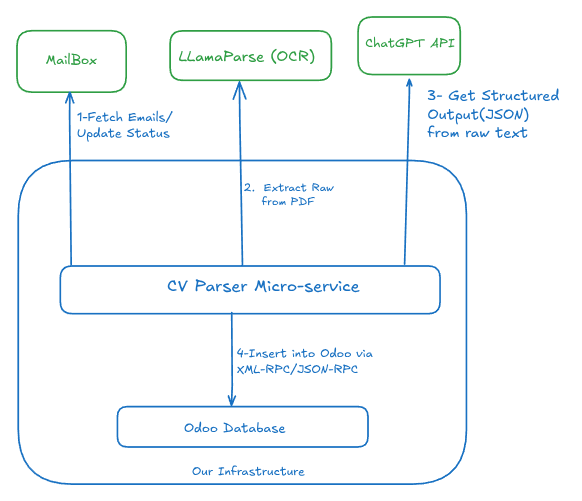
迭代 1 – Tesseract + ChatGPT
第一个方案是一个微服务,将 Tesseract 用于 OCR,结合 ChatGPT API 实现 LLM 逻辑。

它运行了几个月都很顺利,客户也很满意,但随后出现了技术问题:
- Tesseract 在处理某些简历布局时表现不佳,尤其是扫描件。
- 它在我们的 VPS 上占用过多内存,导致无法实现我们所需的高精度性能。
第2次迭代 – LlamaParse 提升 OCR 效果

- LlamaParse 能处理更广泛的 PDF 布局,并降低内存使用。
- 准确率显著提升,减少了所需的手动校正次数。
第三次迭代 – Gemini Pro Vision(当前方案)
最新版本将 ChatGPT API 替换为 Google Gemini Pro Vision。Gemini 的多模态能力让我们可以直接将 PDF 发送给模型,模型随后在一次请求中提取原始文本和结构化 JSON。
主要优势
| 功能 | Gemini Pro Vision | 之前的技术栈 |
|---|---|---|
| 多模态输入(PDF) | ✅ | ❌ (PDF → OCR → text) |
| 单步提取(文本 + JSON) | ✅ | ❌ (two separate calls) |
| 每千 token 成本 | $0.00035 | $0.0015 (ChatGPT) |
| 平均延迟 | ~1.2 s | ~2.8 s |
| 复杂布局的准确性 | 高 | 中等 |
新的微服务流程:
- 读取邮件 – 与之前相同。
- 下载 PDF – 获取附件。
- Gemini Pro Vision 调用 – 发送 PDF;接收原始文本和 JSON 负载。
- Odoo XML‑RPC – 创建招聘记录并附加原始 PDF。
- 分配线索 – 自动分配给招聘人员。

结果与要点
| 指标 | 自动化前 | 集成 Gemini 后 |
|---|---|---|
| 每份简历的手动数据录入时间 | ~4 分钟 | < 30 秒 |
| 招聘人员专注时间 | 占一天的30 % | 占一天的5 % |
| 准确率(手动修正) | 12 % 的简历需要修正 | < 2 % |
| 月成本(OCR + LLM) | $120(Tesseract + ChatGPT) | $28(Gemini) |
| 系统内存使用 | 1.2 GB(Tesseract) | 300 MB(Gemini) |
关键经验
- 选择合适的工具 – 现代多模态 LLM 可以取代整个 OCR + LLM 流程。
- 成本重要 – Gemini 更低的按 token 定价使该方案对小型机构可持续。
- 保持架构简洁 – 组件更少意味着故障点更少,维护更容易。
- GDPR 合规 – 所有处理均在安全服务器上进行,PDF 仅在必要时存储,个人数据从不发送至 Gemini 之外的第三方服务(Gemini 符合 GDPR)。
最终思考
通过从 DIY OCR + ChatGPT 组合迭代到一次性调用 Gemini Pro Vision 方案,我们把繁琐的手动流程转变为几乎即时、成本高效的流水线。招聘人员现在可以专注于他们最擅长的工作——将人才与机会匹配——而系统则负责数据提取和录入的繁重工作。
如果你也面临类似的简历解析难题,考虑使用像 Gemini 这样的多模态大模型。它能够显著简化你的架构,降低成本,并提升准确率——同时保持 GDPR 友好。
For context, **LlamaParse** is a specialized tool created by [LlamaIndex](https://www.llamaindex.ai/). It is designed specifically to *read* and parse complex documents (like PDFs) so AI models can understand them better.
Switching to LlamaParse was a great decision. It allowed us to process any CV format—scanned or digital—and obtain excellent results from the LLM. We ran this setup for a few months until we hit a new problem. This time, it wasn’t technical; it was financial. **ChatGPT was becoming too expensive.**第三轮迭代:DeepSeek 实验
我的雇主开始注意到我们在 ChatGPT API 上花费过多。与此同时,DeepSeek 刚刚登场,掀起了网络热潮。
我们对 DeepSeek 进行了一段时间的评估。它实际上表现非常出色。我们从 ChatGPT 迁移到 DeepSeek,结果立竿见影:在 ChatGPT 上只能支撑一周的预算,现在在 DeepSeek 上可以支撑整整一个月,且效果更佳。
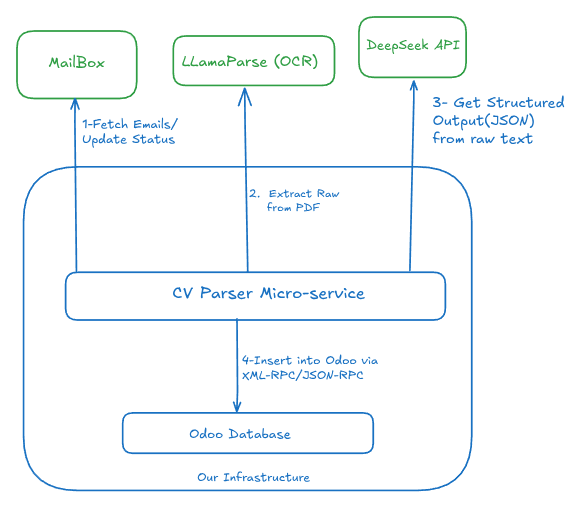
不幸的是,我们仅使用 DeepSeek 两个月就遇到了法律壁垒:GDPR 合规。
DeepSeek 并未符合欧洲数据保护法(GDPR/RGPD)的要求。由于我们在处理法国公民的个人数据,根本无法继续使用它。
胜利的设置:Google Gemini
我们进行了一次全新的迁移,这次迁移到 Google Gemini,旨在寻找成本、效率和合规性的平衡。
结果超出预期。Gemini 的能力如此强大,以至于我们能够 完全放弃 LlamaParse。现在我们使用 Gemini 同时处理视觉/OCR 部分和数据提取。整个过程非常简单:我们将提示词连同 PDF 附件直接发送给 Gemini。
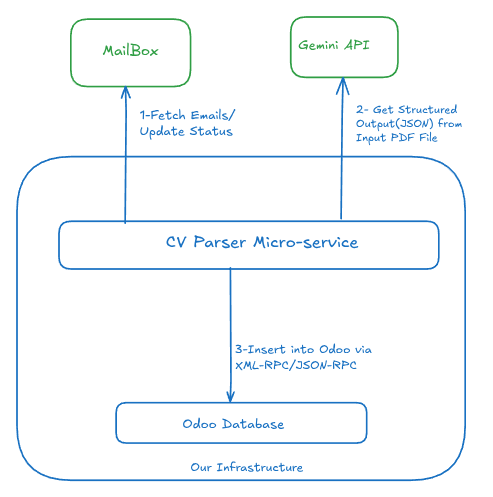
我们已经超过六个月没有触碰这个微服务的代码,因为它一直运行良好。所有流程顺畅,并且我们完全符合 GDPR 要求。
结论
这段旅程让我们明白,软件开发是关于迭代的。我们从一个基础的开源 OCR 开始,随后转向专用的解析工具,进行成本优化,最终确定了一个在性能和合规性之间提供最佳平衡的解决方案。
如今,客户的招聘人员不再在数据录入上浪费时间。他们专注于自己最擅长的工作:为合适的学生找到合适的职位。