Flexora:灵活的低秩适配用于大语言模型
发布: (2026年1月14日 GMT+8 06:22)
3 分钟阅读
原文: Dev.to
Source: Dev.to
当前问题
- 背景: 对大语言模型(LLM)进行微调需要消耗大量资源。LoRA(低秩适配)方法通过冻结原始模型,仅训练少量附加参数来解决这一问题。
- LoRA 的局限性: 虽然有效,LoRA 常常出现 过拟合(模型在训练集上表现很好,但在实际使用中效果差)。现有的缓解方法通常需要手动调节或在不同任务之间缺乏灵活性。
解决方案:Flexora
作者提出了 Flexora,一种新方法,能够 自动挑选出模型中最重要的层 进行微调,而不是对全部层或随机选择层进行微调。
工作机制(3个阶段)
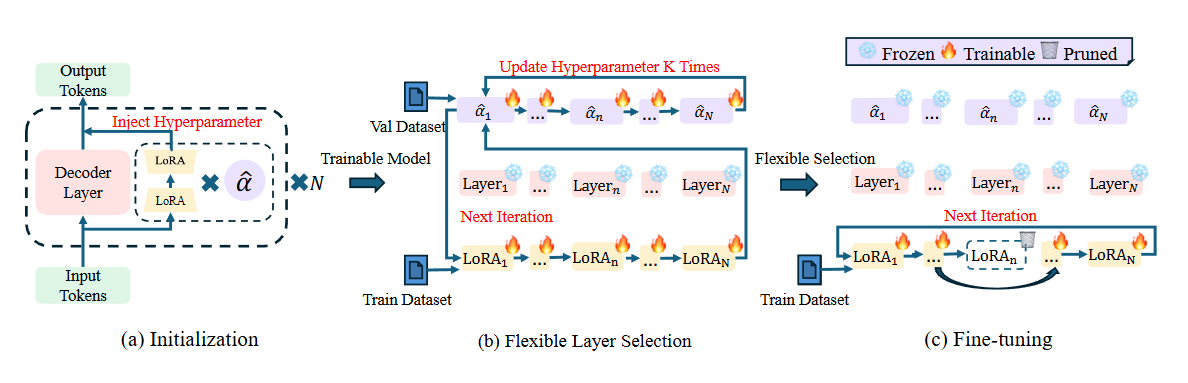
Flexora 将层选择视为超参数优化(Hyperparameter Optimization – HPO)问题。流程包括 3 步:
- 初始化阶段 – 在模型每一层的 LoRA 模块中加入一个可学习的标量参数(记作 $\alpha$)。
- 灵活层选择阶段(Flexible Selection)
- 使用一个小的验证集(validation set)通过 Unrolled Differentiation 技术训练这些 $\alpha$ 参数。
- 系统会自动学习哪些层对输出贡献最大。
- 得分高的层被保留下来,得分低的层被剔除。
- 微调阶段(Fine‑tuning) – 仅对第 2 步中选出的重要层进行训练,其余层保持冻结。这样既节约资源,又聚焦于最关键的部分。
结果与效果
- 更高的性能: Flexora 在多个基准测试(Hellaswag、PIQA、RACE 等)上超越了原始 LoRA 以及其他方法。
- 降低过拟合: 通过剔除冗余参数,模型的泛化能力得到提升(学习理解而非死记硬背)。
- 节省参数: Flexora 通常只需要约 50% 的 LoRA 参数量,却能取得更好的结果。
- 可扩展性: 该方法在多种模型上均表现良好(Llama、Mistral、ChatGLM 等)。
研究表明
- 并非所有 LLM 层对特定任务同等重要。
- Flexora 往往倾向于选择 前几层(输入层) 和 最后几层(输出层) 进行微调,因为这些层包含了与输入数据和输出结果最关键的信息。
总结: Flexora 是 LoRA 的智能升级版,能够自动“挑选精华”(选对需要学习的层),使模型更聪明、更轻量,并避免过拟合。