在 Amazon Bedrock 中创建知识库(逐步控制台指南)
Source: Dev.to
前置条件
在开始之前,请确认您已具备:
- 拥有 Amazon Bedrock、Amazon S3 以及您将使用的向量存储(常见的有 OpenSearch Serverless 或 Aurora PostgreSQL/pgvector,具体取决于您的设置)的权限的 AWS 账户。
- 已准备好源文档(PDF、文本、HTML、文档导出等)。
- 目标 AWS 区域已支持 Bedrock Knowledge Bases。
- 文档存储位置(通常为 S3 存储桶)。
第一步 — 打开 Amazon Bedrock 并导航至知识库
- 登录 AWS 控制台。
- 搜索 Amazon Bedrock。
- 在 Bedrock 左侧导航栏中,找到 Knowledge bases(位于相应的部分,例如 Builder tools 下)。
- 点击 Knowledge bases。

步骤 2 — 开始创建知识库
在 Knowledge Bases 页面,点击 Create knowledge base。
这将启动一个引导式、向导式工作流。
第3步 — 选择知识库设置类型
在向导中,您通常会看到以下选项:
- 带向量存储的知识库 (推荐用于 RAG)
- 其他选项取决于您的账户/地区功能
选择 带向量存储的知识库 选项。

注意: 知识库将嵌入向量存储在向量索引中,以便 Bedrock 在查询时能够检索相关的文本块。
嵌入是数据(文本、图像、音频等)的数值表示,以数学形式捕获意义和上下文。简而言之:嵌入将人类知识转化为 AI 可以搜索、比较和推理的数学。
第 4 步 — 定义知识库详情
提供以下内容:
- 知识库名称(例如
utility-ops-kb) - 描述(可选,但推荐)
- 组织标签(可选)
我使用了名称
knowledge-base-dipayan,但最佳实践是使名称与域和环境保持一致,例如us-outage-kb-dev。

第 5 步 — 配置数据源(Amazon S3)
- 选择 Amazon S3 作为数据源。
- 选取存放文档的 S3 bucket 和前缀/文件夹。
- 确认文档格式和包含规则(如果出现提示)。

我使用了
bedrock-dipayanS3 bucket 上传了 Jeff Bezos 的 2022 年股东信。
最佳实践: 为知识库保留专用前缀,例如s3://my-company-kb/energy-utility/outage-procedures/。


IAM 权限
Bedrock 需要以下权限:
- 读取 S3 bucket 中的文档。
- 写入 嵌入向量到所选的向量存储。
- 执行 同步操作。
在向导中,你可以:
- 让 Bedrock 创建一个新的 IAM 角色,或
- 选择已有的 IAM 角色。
最佳实践: 采用最小权限原则。如果选择已有角色,请确保至少包含以下权限:
s3:GetObject(针对你的 bucket/前缀)- 你所选向量存储所需的相应权限。
第6步 — (可选)选择解析策略
原指南中包含了“S3 数据源和解析策略”的图片。图片 URL 被截断,请在此处插入相应的截图。
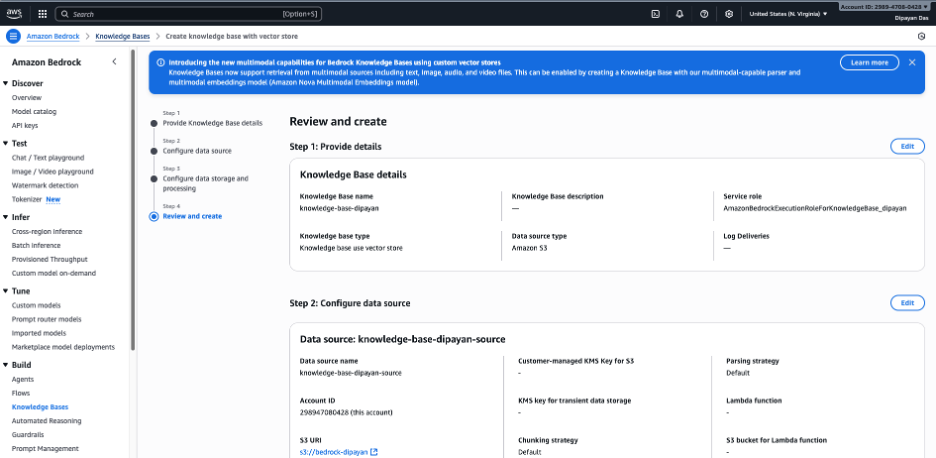
第 7 步 — 审核并创建
- 在最终摘要页面检查所有设置。
- 点击 Create knowledge base(创建知识库)。
Bedrock 现在将会:
- 爬取 S3 存储桶,
- 从受支持的文档类型中提取文本,
- 生成嵌入向量,
- 填充向量存储。
当状态变为 Active(已激活)后,即可通过 Bedrock API 或控制台开始查询知识库。
快速回顾
| 步骤 | 操作 |
|---|---|
| 1 | 打开 Bedrock → Knowledge bases(知识库) |
| 2 | 点击 Create knowledge base(创建知识库) |
| 3 | 选择 Knowledge base with vector store(带向量存储的知识库) |
| 4 | 设置名称、描述、标签 |
| 5 | 配置 S3 数据源和 IAM 角色 |
| 6 | (可选)选择解析策略 |
| 7 | 审核并创建 |
现在,您已经拥有一个可用于检索增强生成(RAG)工作负载的完整功能的 Amazon Bedrock 知识库。祝您构建愉快!
第5步 – 配置数据源
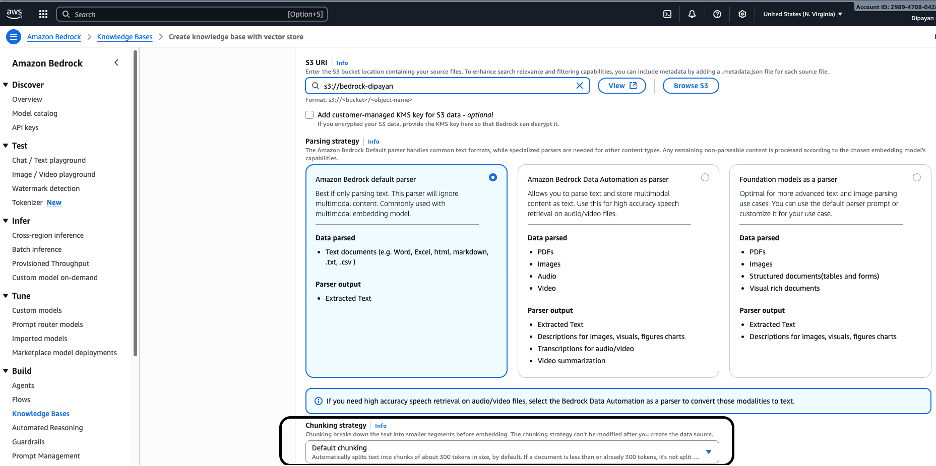
在 S3 URI 下,提供包含源文档的 Amazon S3 存储桶位置。
示例
s3://bedrock-dipayan/您可以点击 Browse S3 选择存储桶,或点击 View 查看其内容。
如果 S3 数据使用 CMK 加密,您也可以提供客户管理的 KMS 密钥(可选)。
解析
解析决定 Bedrock 在嵌入之前如何从源文件中提取内容。根据截图,提供了三种解析器选项:
选项 1 – Amazon Bedrock 默认解析器 (已选)
推荐用于大多数基于文本的知识库。
- 适用场景:文本密集的文档(PDF、Word、Excel、HTML、Markdown、CSV、TXT)
- 解析器输出:提取的纯文本
- 与 Amazon Titan Embeddings 或其他文本嵌入模型配合良好。
典型用例:企业文档、标准作业程序(SOP)、报告、政策、信函、手册。
选项 2 – Amazon Bedrock 数据自动化解析器
为多模态内容而设计。
- 适用场景:布局复杂的 PDF、图像、音频和视频文件
- 解析器输出:
- 提取的文本
- 图像描述和标题
- 音频/视频转录和摘要
当您的知识库包含必须转换为可搜索文本的非文本内容时使用此选项。
选项 3 – 基础模型作为解析器
使用基础模型解析丰富或复杂的文档。
- 适用场景:表格、表单、结构化文档、视觉丰富的 PDF
- 解析器输出:
- 提取的文本
- 图形、可视化和表格的描述
提供高级解析功能,但可能会增加成本和处理时间。
配置分块策略
分块控制在生成嵌入之前,文档如何被拆分为更小的片段。
- 默认分块(已选)
- 将文本拆分为约 500 个 token 的块
- 在必要时使用重叠以保留上下文
- 如果文档已小于块大小,则跳过分块
为何分块重要
- 更小的块提升检索精度。
- 重叠块保持语义连续性。
- 合理的分块可减少幻觉并提升依据性。
最佳实践:除非有强烈的定制需求(例如非常长的法律文档或高度结构化的数据),否则使用默认分块即可。
第6步 — 选择嵌入模型
选择用于将文档转换为向量(嵌入)的嵌入模型。常见选项包括:
- Amazon Titan Embeddings(常规默认)
- 其他提供商的嵌入模型(取决于您的账户已启用的内容)
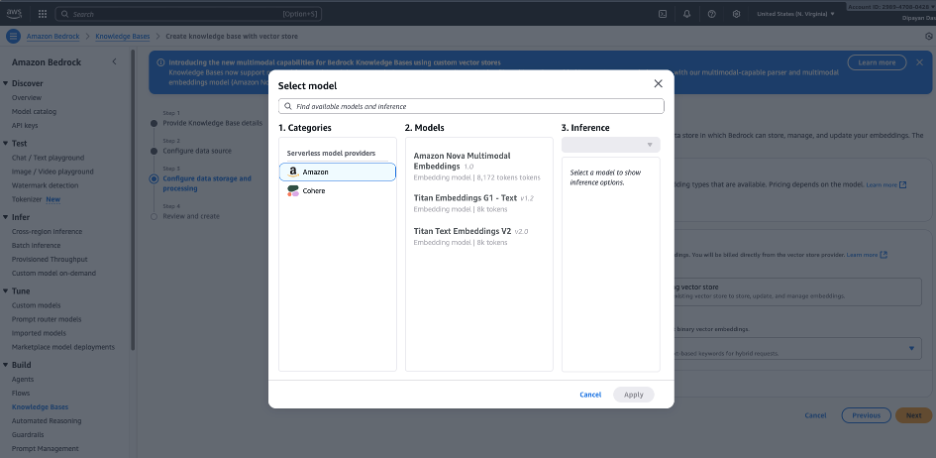
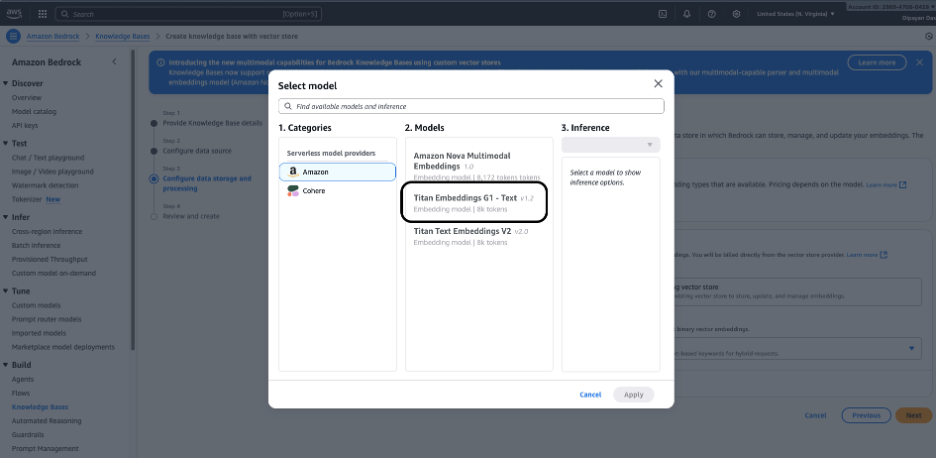
第7步 – 配置嵌入模型和向量存储
-
配置数据存储和处理 – 选择一个嵌入模型。点击 Select model 并选择一个嵌入模型(例如 Amazon Titan Embeddings),将您的文档转换为向量表示。
-
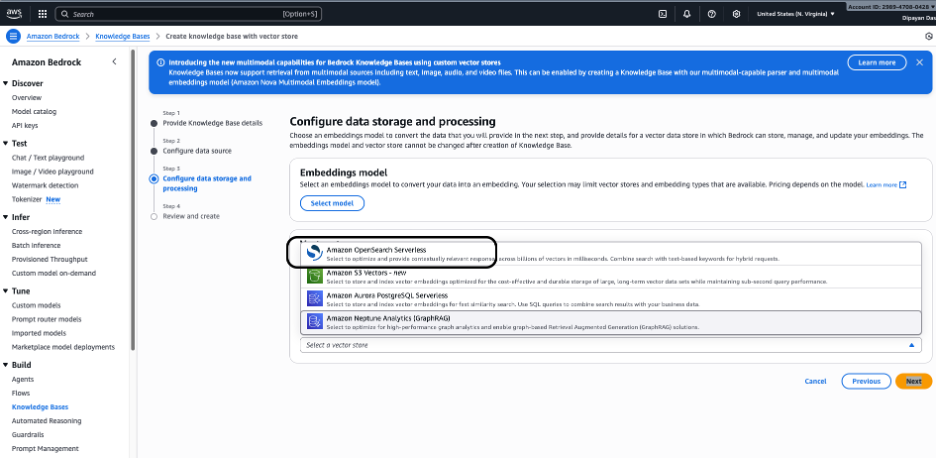
选择向量存储,Bedrock 将在其中存储和管理嵌入。可用选项:
- Amazon OpenSearch Serverless (大多数用例推荐) – 完全托管、可扩展的向量搜索,针对语义搜索和混合搜索进行优化。
- Amazon Aurora PostgreSQL Serverless (pgvector) – 如果您已经使用关系型数据库并希望进行基于 SQL 的向量查询,则适合使用。
- Amazon Neptune Analytics (GraphRAG) – 用于基于图的检索和高级关系驱动的 RAG 场景。
请选择 Amazon OpenSearch Serverless(如截图所示),它是为高性能语义搜索优化的全托管向量数据库。Bedrock 将自动创建并管理所需的向量索引。
第8步 — 审核并创建
-
审查完整的配置摘要:
- 知识库名称
- 数据源路径
- 嵌入模型
- 向量存储配置
- IAM 角色
-
点击 Create knowledge base。
此时,Knowledge Base 对象已创建,但仍需进行文档的摄取/同步。

知识库已就绪,但您会看到 “Test Knowledge Base” 选项呈灰色,因为文档需要同步后才能测试该知识库。
第9步 — 同步(摄取)您的文档
- 打开您的知识库。
- 启动 同步(有时标记为 Sync data source)。
- 监控同步状态,直至显示 已完成/就绪。
同步的作用:
它会将文档切分为块,生成嵌入向量,并将其存储在向量索引中。

第10步 — 测试已创建的知识库
Test Knowledge Base 选项在 Amazon Bedrock 中可让您在将知识库(KB)集成到应用或代理之前,交互式地验证其是否按预期工作。它充当内置的 RAG 测试控制台。
此视图可帮助您:
- 提出自然语言问题。
- 控制检索和生成行为。
- 检查用于回答的来源块。
- 验证依据性和相关性。
- 实时调优配置设置。
