性能提升 16 倍,成本降低 98%:深入了解升级后的 SLS Vector Indexing Architecture
Source: Dev.to
请提供您希望翻译的正文内容,我将为您翻译成简体中文并保持原有的格式、Markdown 语法以及技术术语不变。谢谢!
向量索引在日志场景中的成本与吞吐挑战
在语义索引中,嵌入过程是决定语义召回率的关键因素。在整个语义索引流水线中,嵌入同样是核心成本组成部分。
- 成本: 嵌入 1 GB 数据的费用可能高达数百人民币。
- 速度: 吞吐量仅约 100 KB/s。
相比之下,索引构建和存储的成本可以忽略不计。GPU 上嵌入模型的推理效率直接决定了构建语义索引的速度和总体成本。
对于知识库场景,这类成本可能是可以接受的,因为数据相对静态且更新频率低。然而,对于 Simple Log Service (SLS) 流式数据,新数据会持续产生,给性能和成本都带来巨大压力。每 GB 几百人民币且吞吐仅 100 KB/s 的表现,难以支撑生产工作负载。
为提升大规模应用的性能与成本效率,我们针对嵌入服务的推理瓶颈开展了系统化优化。通过深入分析、方案选型以及定制化改进,我们实现了 16 倍的吞吐提升,同时显著降低了每次请求的资源成本。
技术挑战与优化策略
为了实现嵌入服务的最佳成本效益,我们需要解决以下关键挑战:
1. 推理框架
市场上存在多种推理框架——vLLM、SGLang、llama.cpp、TensorRT、sentence‑transformers——它们各自侧重点不同(通用 vs. 专用,CPU vs. GPU)。选择最适合嵌入工作负载并能最大化硬件(尤其是 GPU)性能的框架至关重要。
框架在连续批处理、内核优化等任务上的固有计算效率,可能成为嵌入模型推理性能的瓶颈。
2. 最大化 GPU 利用率
GPU 资源昂贵,未充分利用会导致浪费。这与 CPU 时代有显著区别。
- 批处理: 嵌入推理对批大小极为敏感。单条请求的处理效率远低于批处理。必须实现高效的请求批处理机制。
- 并行处理: CPU 预处理(如分词)、网络 I/O 与 GPU 计算必须完全解耦并并行化,以防止 GPU 空闲。
- 多模型副本: 与参数庞大的聊天模型不同,典型的嵌入模型参数较少。单个 A10 GPU 上的一个副本可能仅使用约 15 % 的计算能力和 13 % 的显存。将多个模型副本部署在同一 GPU 上,以“用满”资源,对降低成本和提升吞吐量至关重要。
3. 基于优先级的调度
语义索引包含两个阶段:
| 阶段 | 批大小 | 优先级 |
|---|---|---|
| 索引构建 | 大 | 低 |
| 在线查询 | 小 | 高(实时) |
必须确保查询请求的嵌入任务不会被构建任务阻塞。需要细粒度的优先级队列调度机制——单纯的资源池隔离不足以满足需求。
4. 端到端流水线的瓶颈
在提升 GPU 利用率后,流水线的其他环节(例如分词)可能会成为新的瓶颈。
解决方案
我们最终实现了以下优化方案。

优化 1 – 将 vLLM 设为核心推理引擎(替换 llama.cpp)
-
切换原因:
- 我们最初选择 llama.cpp 是基于其出色的 C++ 性能、对 CPU 友好(部分任务在 CPU 节点上运行)以及易于集成。
- 最近的测试显示,在相同硬件条件下,vLLM(或 SGLang)的吞吐量比 llama.cpp 高出 2 倍,而平均 GPU 利用率 降低了 60 %。
- 关键差异在于 vLLM 的连续批处理(Continuous Batching) 机制以及高度优化的 CUDA kernel。
-
部署变更:
- 我们将嵌入模块拆分为独立服务,并部署在 Platform for AI (PAI) 的 Elastic Algorithm Service (EAS) 上。
- 向量构建和查询操作现在通过远程调用获取嵌入。
- 虽然这会带来网络开销和额外的运维成本,但显著提升了基线性能,并为后续优化奠定了坚实基础。
优化 2 – 在单个 GPU 上部署多个模型副本
- 目标: 通过在一块 A10 GPU 上运行多个模型副本,提高 GPU 利用率。
- 选用框架: Triton Inference Server。
- 方便控制每块 GPU 上的模型副本数量。
- 提供调度和动态批处理功能,将请求路由到不同的副本。
- 实现细节: 绕过 vLLM HTTP 服务器,直接在 Triton 的 Python 后端调用 vLLM 核心库 (
LLMEngine),降低开销。
优化 3 – 将分词过程与模型推理解耦
- 发现的问题: 在多个 vLLM 副本运行后,分词成为在提升 GPU 吞吐量后新的性能瓶颈。
- 解决方案: (原文续写)
[原始内容在此被截断;剩余步骤将描述如何将分词卸载到独立服务或并行化、使用快速分词器以及采用的缓存机制等。]
结果
- 吞吐量: 相比基线提升约 16 倍。
- 每请求成本: 由于 GPU 利用率提升和空闲资源减少,成本显著下降。
- 可扩展性: 系统现在能够在生产环境中持续处理日志流,摆脱了之前的性能和成本限制。
优化 4 – 优先级队列和动态批处理
- Triton Inference Server 配备了内置的优先级队列机制和动态批处理机制,完全符合嵌入服务的需求。
- 查询操作期间的嵌入请求被分配更高的优先级,以降低查询延迟。
- 动态批处理将进入的请求分组为批次,提高整体吞吐效率。
Source:
最终架构设计
在解决嵌入的性能瓶颈后,还需要重构整体的语义索引架构。系统需要:
- 切换为调用远程嵌入服务。
- 在数据读取、分块、嵌入请求以及结果处理/存储步骤之间实现完全的异步化和并行化。
嵌入调用
在之前的架构中,直接调用嵌入的 llama.cpp 引擎进行嵌入。新架构中,嵌入通过远程调用完成。
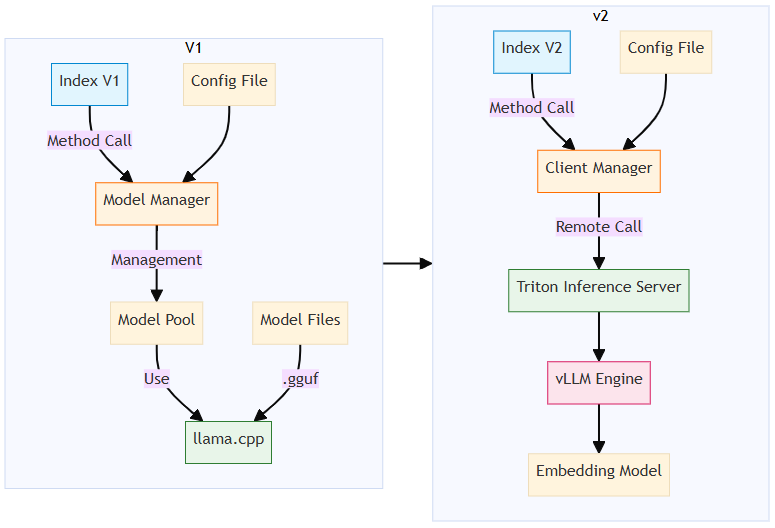
完全异步化和并行化
旧架构按顺序处理数据解析 → 分块 → 嵌入,导致基于 GPU 的嵌入服务无法充分负载。
新设计实现了完全的异步化和并行化,高效利用网络 I/O、CPU 和 GPU 资源。
流水线任务编排
我们将语义索引构建过程划分为多个任务,并将其构建为有向无环图(DAG)进行执行。不同任务可以异步并行运行,每个任务内部也支持并行执行。
整体流程
DeserializeDataTask
→ ChunkingTask (parallel)
→ GenerateBatchTask
→ EmbeddingTask (parallel)
→ CollectEmbeddingResultTask
→ BuildIndexTask
→ SerializeTask
→ FinishTask流水线调度框架
为了高效执行流水线任务,我们实现了一个数据驱动和事件驱动的调度框架。
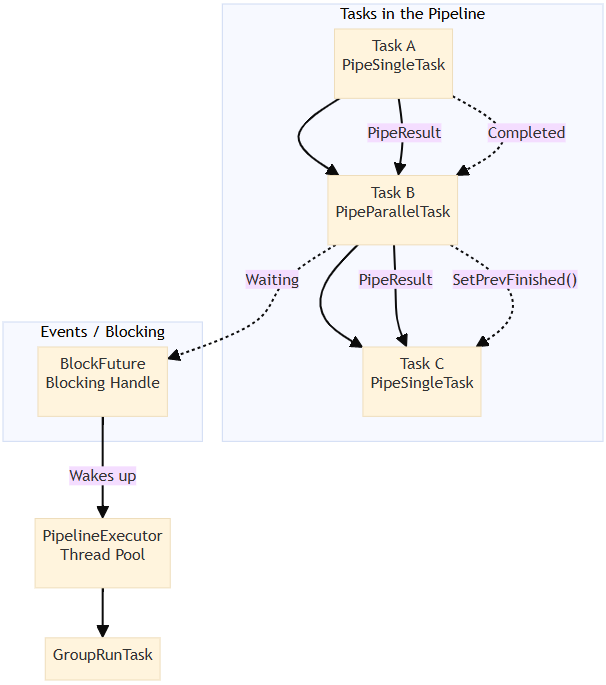
完全重新设计的构建过程
通过大量代码修改,我们实现了一次重大的架构跃迁,使得语义索引构建具备高性能。

结论:更高的吞吐量和成本效率
- 吞吐量 从 170 KB/s 提升至 3 MB/s。
- SLS 向量索引服务 的定价为 CNY 0.01 每百万 token,相较行业替代方案具有 两个数量级 的成本优势。
欢迎使用此服务。更多信息请参阅使用指南。