在AWS上构建AI驱动的客户流失预测管道(逐步指南)
发布: (2026年1月1日 GMT+8 08:56)
7 分钟阅读
原文: Dev.to
Source: Dev.to
我们的成果
- ✅ 84.2% AUC 在验证数据上
- ✅ 通过 SageMaker 端点进行实时预测
- ✅ 由 Claude(Bedrock)提供支持的自然语言解释
Source: …
🎯 我们正在构建的内容
一个端到端的机器学习流水线:
| 步骤 | 操作 |
|---|---|
| 摄取 | 将客户数据导入 S3 |
| 训练 | 使用 SageMaker XGBoost 进行流失预测模型训练 |
| 部署 | 实时推理端点 |
| 解释 | 使用 Amazon Bedrock(Claude)解释预测 |
| 暴露 | 通过 API Gateway + Lambda 提供所有功能 |
先决条件:AWS 账户,基础 Python 知识
🏗️ 架构概览

该管道由 5 层组成
| 层级 | 服务 | 目的 |
|---|---|---|
| 数据摄取 | S3 | 存储原始客户数据 |
| 机器学习训练 | SageMaker Training | 训练 XGBoost 模型 |
| 模型存储 | S3 | 存储模型制品 |
| 推理与 AI | SageMaker Endpoint, Bedrock | 实时预测 + 自然语言解释 |
| API 层 | API Gateway, Lambda | 提供 REST API |
第一步 – 设置 S3 并上传数据
# 使用您的账户 ID 设置存储桶名称
export BUCKET_NAME=churn-prediction-$(aws sts get-caller-identity --query Account --output text)
# 创建存储桶
aws s3 mb s3://$BUCKET_NAME
# 上传您的数据
aws s3 cp WA_Fn-UseC_-Telco-Customer-Churn.csv s3://$BUCKET_NAME/raw/📥 数据集:从 Kaggle 下载 Telco Customer Churn 数据集。
Step 2 – Create SageMaker IAM Role
- 打开 IAM 控制台 → Roles → Create role。
- 选择 SageMaker – Execution 作为受信实体。
- 附加策略:
AmazonSageMakerFullAccess和AmazonS3FullAccess。 - 将角色命名为 SageMakerChurnRole。
第三步 – 训练模型
创建一个名为 train_churn.py 的文件,内容如下:
import boto3
import sagemaker
import pandas as pd
import os
from sklearn.model_selection import train_test_split
from sagemaker.inputs import TrainingInput
# Config
BUCKET = os.environ['BUCKET_NAME']
ROLE = os.environ['ROLE_ARN']
PREFIX = 'churn-prediction'
session = sagemaker.Session()
region = session.boto_region_name
# Load and prepare data
df = pd.read_csv('WA_Fn-UseC_-Telco-Customer-Churn.csv')
df['TotalCharges'] = pd.to_numeric(df['TotalCharges'], errors='coerce').fillna(0)
df['Churn'] = (df['Churn'] == 'Yes').astype(int)
# Encode categorical columns
cat_cols = [
'gender', 'Partner', 'Dependents', 'PhoneService', 'MultipleLines',
'InternetService', 'OnlineSecurity', 'OnlineBackup', 'DeviceProtection',
'TechSupport', 'StreamingTV', 'StreamingMovies', 'Contract',
'PaperlessBilling', 'PaymentMethod'
]
for col in cat_cols:
df[col] = df[col].astype('category').cat.codes
# Feature set
feature_cols = ['SeniorCitizen', 'tenure', 'MonthlyCharges', 'TotalCharges'] + cat_cols
X = df[feature_cols]
y = df['Churn']
# Train‑test split
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42, stratify=y
)
train_df = pd.concat([y_train.reset_index(drop=True), X_train.reset_index(drop=True)], axis=1)
test_df = pd.concat([y_test.reset_index(drop=True), X_test.reset_index(drop=True)], axis=1)
train_df.to_csv('train.csv', index=False, header=False)
test_df.to_csv('test.csv', index=False, header=False)
# Upload CSVs to S3
s3 = boto3.client('s3')
s3.upload_file('train.csv', BUCKET, f'{PREFIX}/train/train.csv')
s3.upload_file('test.csv', BUCKET, f'{PREFIX}/test/test.csv')
# XGBoost container
container = sagemaker.image_uris.retrieve('xgboost', region, '1.7-1')
xgb = sagemaker.estimator.Estimator(
image_uri=container,
role=ROLE,
instance_count=1,
instance_type='ml.m5.xlarge',
output_path=f's3://{BUCKET}/{PREFIX}/output',
sagemaker_session=session
)
xgb.set_hyperparameters(
objective='binary:logistic',
num_round=100,
max_depth=5,
eta=0.2,
eval_metric='auc'
)
xgb.fit({
'train': TrainingInput(f's3://{BUCKET}/{PREFIX}/train', content_type='csv'),
'validation': TrainingInput(f's3://{BUCKET}/{PREFIX}/test', content_type='csv')
})
# Deploy endpoint
predictor = xgb.deploy(
initial_instance_count=1,
instance_type='ml.t2.medium',
endpoint_name='churn-prediction-endpoint',
serializer=sagemaker.serializers.CSVSerializer()
)运行脚本
export BUCKET_NAME=churn-prediction-YOUR_ACCOUNT_ID
export ROLE_ARN=arn:aws:iam::YOUR_ACCOUNT_ID:role/SageMakerChurnRole
python3 train_churn.py示例训练输出
2026-01-01 00:24:27 Uploading - Uploading generated training model
2026-01-01 00:24:27 Completed - Training job completed
Training seconds: 103
Billable seconds: 103
✅ Training complete!
Model artifact: s3://churn-prediction-905418352184/churn-prediction/output/sagemaker-xgboost-2026-01-01-00-22-03-339/output/model.tar.gz
Deploying endpoint (3‑5 min)...
INFO:sagemaker:Creating model with name: sagemaker-xgboost-2026-01-01-00-24-53-959
INFO:sagemaker:Creating endpoint-config with name churn-prediction-endpoint
INFO:sagemaker:Creating endpoint with name churn-prediction-endpoint
✅ Endpoint deployed: churn-prediction-endpoint
Test prediction: 0.4% churn probability现在,你已经拥有一个完整功能的流失预测模型、一个实时的 SageMaker 端点,并且(在接下来的步骤中)还有一个调用 Bedrock 为每个预测生成简明英文解释的 API 层。敬请期待本教程的其余部分!
第 4 步 – 创建带 Bedrock 集成的 Lambda
创建一个名为 ChurnPredictionAPI 的 Lambda 函数,代码如下:
import json
import boto3
import os
sagemaker_runtime = boto3.client('sagemaker-runtime')
bedrock = boto3.client('bedrock-runtime')
ENDPOINT_NAME = os.environ.get('SAGEMAKER_ENDPOINT', 'churn-prediction-endpoint')
def lambda_handler(event, context):
body = json.loads(event['body']) if isinstance(event.get('body'), str) else event
# Get prediction from SageMaker
response = sagemaker_runtime.invoke_endpoint(
EndpointName=ENDPOINT_NAME,
ContentType='text/csv',
Body=body['features']
)
churn_prob = float(response['Body'].read().decode())
# Generate explanation with Bedrock Claude
prompt = f"""A customer has {churn_prob:.1%} churn probability.
Customer: Tenure {body.get('tenure', 'N/A')} months, ${body.get('monthly_charges', 'N/A')}/month, {body.get('contract', 'N/A')} contract.
In 2 sentences, explain the risk and suggest one retention action."""
bedrock_response = bedrock.invoke_model(
modelId='anthropic.claude-3-haiku-20240307-v1:0',
body=json.dumps({
"anthropic_version": "bedrock-2023-05-31",
"max_tokens": 100,
"messages": [{"role": "user", "content": prompt}]
})
)
explanation = json.loads(bedrock_response['body'].read())['content'][0]['text']
risk = "High" if churn_prob > 0.7 else "Medium" if churn_prob > 0.4 else "Low"
return {
'statusCode': 200,
'headers': {'Content-Type': 'application/json'},
'body': json.dumps({
'churn_probability': f"{churn_prob:.1%}",
'risk_level': risk,
'explanation': explanation
})
}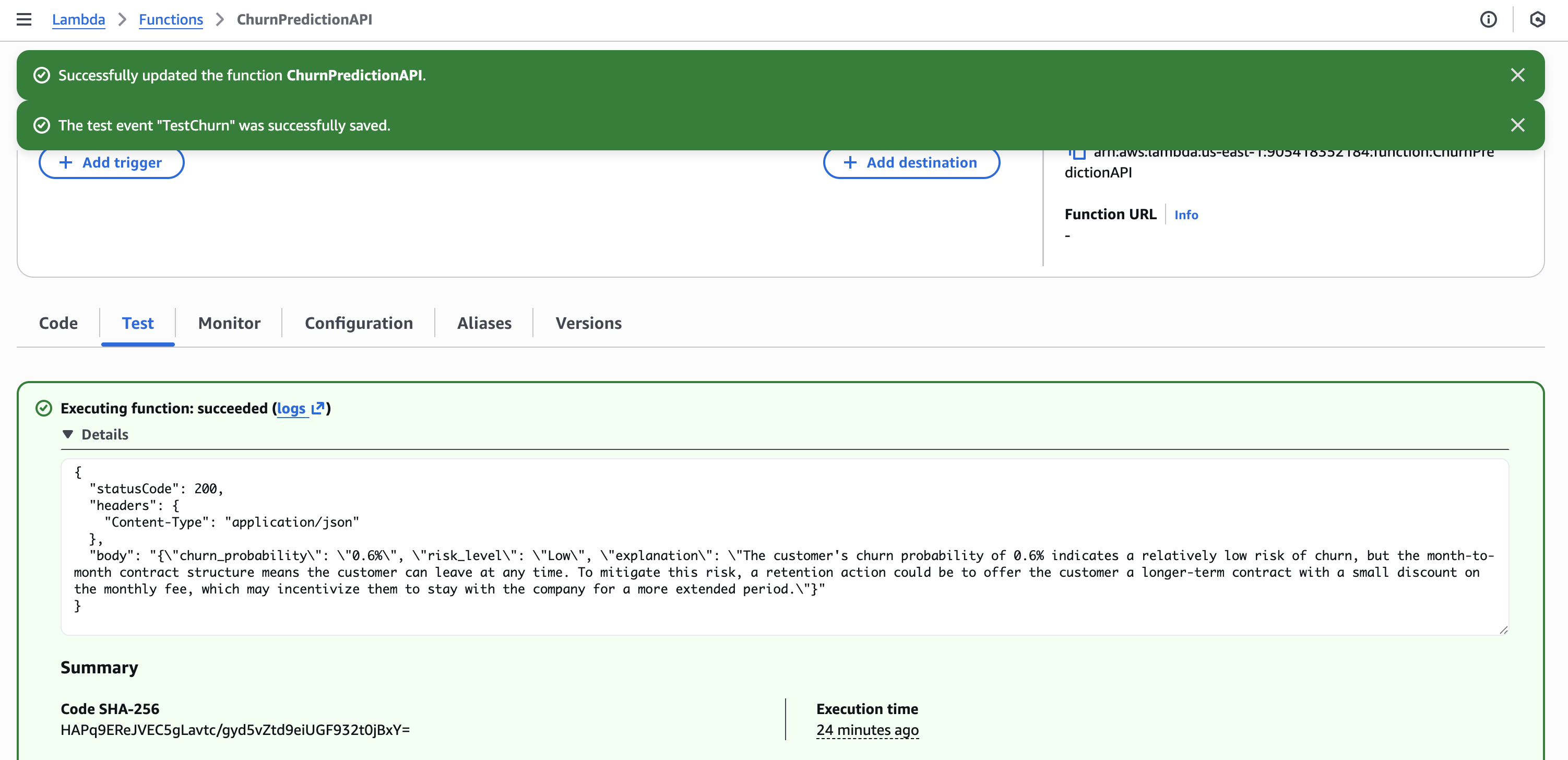
Lambda 配置
- 运行时(Runtime): Python 3.11
- 超时时间(Timeout): 30 秒
- 角色(Role):
LambdaChurnRole(具备 SageMaker + Bedrock 权限) - 环境变量(Environment variable):
SAGEMAKER_ENDPOINT=churn-prediction-endpoint
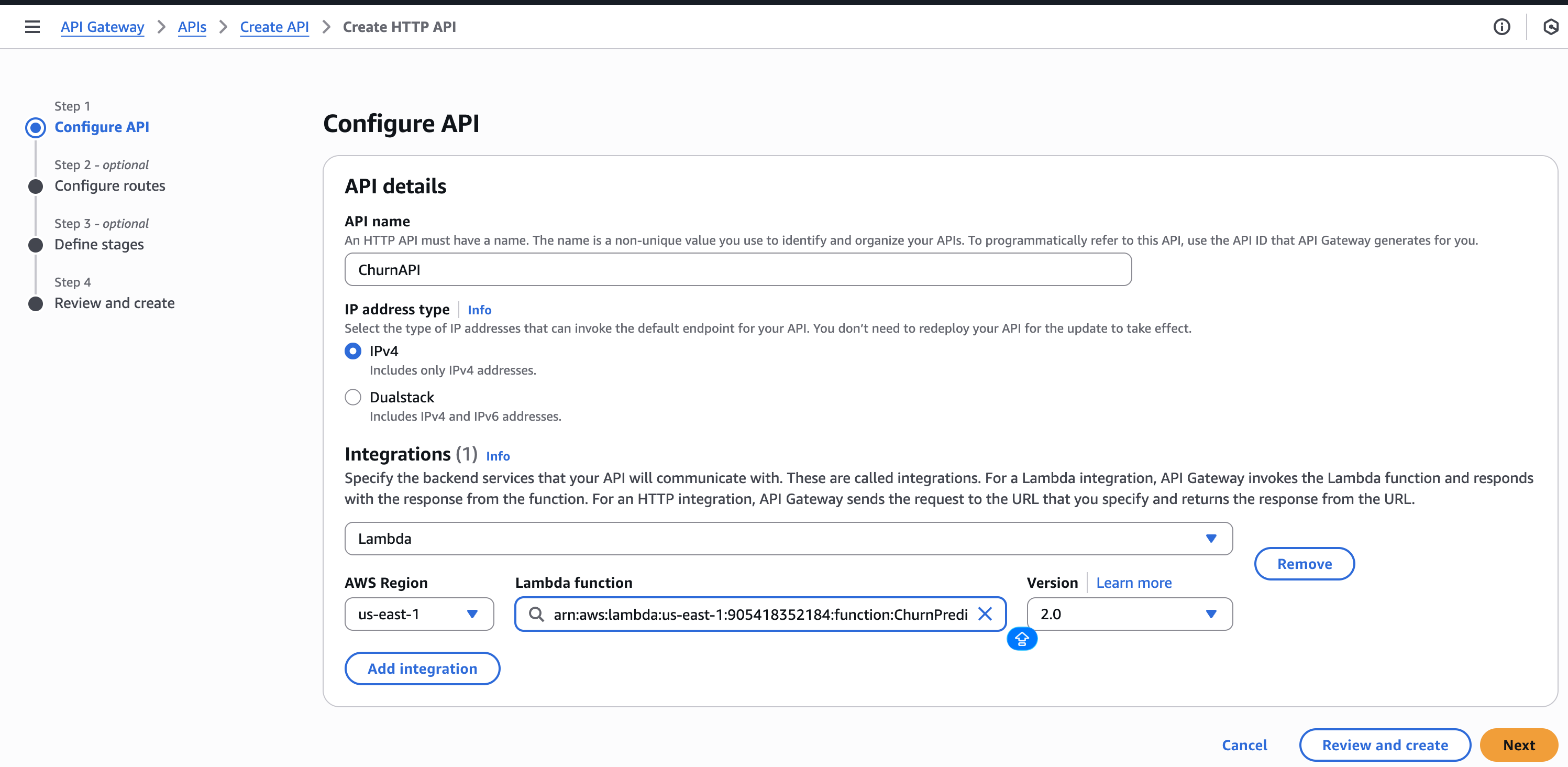
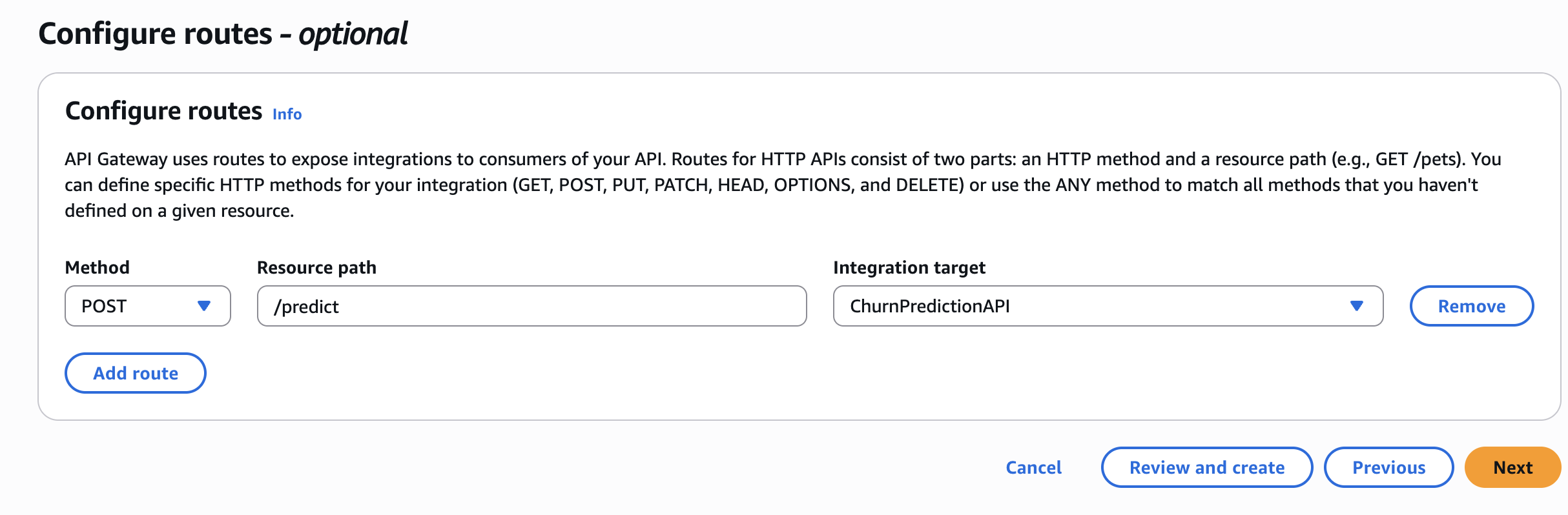
步骤 5 – 创建 API 网关
- 在 API Gateway 中创建一个 HTTP API。
- 添加 Lambda 集成 →
ChurnPredictionAPI。 - 创建一个 POST 路由:
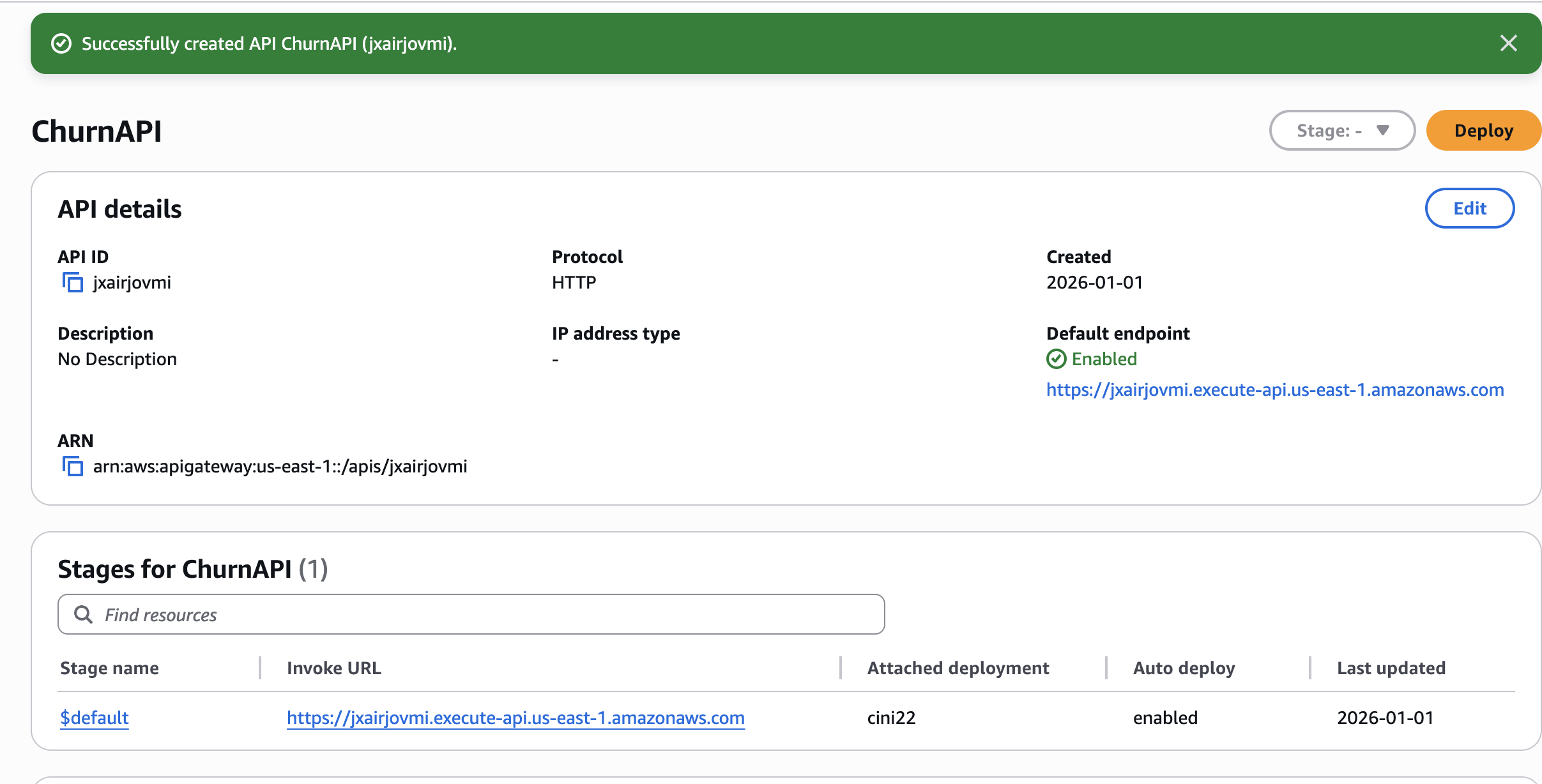
/predict。 - 部署并记录调用 URL。
🧪 测试 API
curl -X POST "https://YOUR_API_URL/predict" \
-H "Content-Type: application/json" \
-d '{
"features": "0,24,65.5,1500.0,1,0,1,2,0,0,1,1,0,0,1,0,2,1,1",
"tenure": 24,
"monthly_charges": 65.5,
"contract": "Month-to-month"
}'
示例响应
{
"churn_probability": "0.6%",
"risk_level": "Low",
"explanation": "The customer's high churn probability of 0.6% and the month-to-month contract indicate a significant risk of losing the customer. To mitigate this risk, a retention action could be to offer the customer a longer-term contract with a discounted monthly rate or additional benefits, which may help increase their loyalty and reduce the likelihood of churn."
}🧹 清理
完成后删除资源以避免产生费用:
# Delete SageMaker endpoint (most expensive!)
aws sagemaker delete-endpoint --endpoint-name churn-prediction-endpoint
aws sagemaker delete-endpoint-config --endpoint-config-name churn-prediction-endpoint
# Delete Lambda
aws lambda delete-function --function-name ChurnPredictionAPI
# Delete S3 bucket
aws s3 rb s3://$BUCKET_NAME --force💡 关键经验教训
- SageMaker XGBoost 已具备生产就绪能力 – 通过最小调优实现约 84 % 的 AUC。
- Bedrock 带来真实的业务价值 – 将原始预测转化为可操作的洞察,使非技术利益相关者也能使用机器学习。
- IAM 权限很棘手 – 通过控制台创建角色可以帮助避免 “explicit deny” 错误。
- 成本意识很重要 – 当不再需要时,务必删除昂贵的资源(例如 SageMaker 端点)。
未使用时的端点
(~$0.05/小时累计!)
资源
感谢阅读!如果对您有帮助,请关注我获取更多 AWS + 数据工程 内容。
有问题吗? 在下方留言!