公司的 AI 能力归根结底是数据能力。
Source: Byline Network

AI Ready 数据与数据治理
“公司的 AI 能力归根结底是数据能力。”
CrowdWorks 首席技术官(封面照片)양수열 在 5 日举办的 “AI‑Ready DATA 战略” 网络研讨会上,以 “面向 AI Ready 数据的数据整合与治理体系” 为主题发表演讲时如此强调。
许多企业和组织尝试通过引入生成式 AI 来创造新的业务价值,但实现目标的过程并不容易。采用优秀的基础 AI 模型,并构建将内部数据接入的检索增强生成(RAG)系统已成为常规做法,但要取得实际成效仍需跨越诸多障碍。
양수열 CTO 表示:“仅靠模型或 RAG 流程让公司通过 AI 提升业务价值是有限的”,并指出:“普通企业或组织在 AI 引入时应重点关注的是,如何将内部数据管理并维持为 AI Ready 数据形态。” 他进一步说明:“在引入 AI 提升公司竞争力时,模型本质上是不可控的领域,竞争对手也会使用市面上的优秀模型,” 因此“拥有能够妥善管理内部提取数据的治理体系才是竞争力所在”。
大多数公司已经在内部保存了多种类型的数据。
- 结构化数据:存储于数据库
- 非结构化数据(文档·图片·视频等):存储于 KMS、论坛等
要在大型语言模型(LLM)中利用这些数据,需要将结构化和非结构化数据 标准化为数据集,并加载到搜索引擎和向量数据库中,再与 LLM 连接形成 RAG 系统。此过程包括结构化数据的向量化以及非结构化数据的标准化与转换。尤其是文档数据,不仅要提取文本,还要从表格、图形等可视化二进制文件中准确抽取信息,这一环节可以借助小型语言模型(SLM)或 LLM 完成。
RAG 系统构建流程
将各种非结构化数据转换为 AI 模型可使用的形式是一项繁琐工作。国内企业的文档倾向于摘要,使用表格、图形、示意图的频率高于长文本。要把合同、官方文件、账单等拥有多种格式和复杂结构的文档转化为 AI Ready 数据,需要投入大量人力。
在准备好 AI Ready 数据后,搜索引擎或向量数据库会在用户与 LLM 之间检索相关资料并传递给 LLM,随后 LLM 给出初步答案,系统再将符合上下文的回复返回给用户,这样的 RAG 应用即告完成。

实现上述工作流需要以下步骤:
- 数据收集
- 模型开发
- 数据训练
- 评估·验证
- 服务部署
- 监控·改进
最关键的是,这一流程不是一次性完成,而是 持续循环、验证、改进 的过程。
양수열 CTO 说:“在公司内部决定构建 AI 系统并不是一次性事件,而是需要不断重复的过程。” 他指出,“即使在 RAG 构建的数据和模型部署后,也需要对答案的满意度进行代理性能评估;准确性、偏见防止、合规等安全性评估必须在监控、运营、改进阶段持续进行。”
仅仅引入以 RAG 为核心的 AI 环境并不能立刻提升企业竞争力。技术组件本身难以与竞争对手形成差异化。
양 CTO 解释:“企业内部使用的 AI 模型大多是开源模型,且近期的开源模型通过微调提升性能的空间已趋于有限。” 同时,“将现有业务应用流程与 AI 系统对接的部分也难以形成显著差异。” 他强调:“公司在 AI 系统中真正的差异点在于,如何把内部数据管理成 AI Ready 数据并保持其质量。” 因此,“在考虑市面模型和 RAG 方法论的演进时,应以系统性变革为基础,并随时引入新的模型或方法,这种体系化的做法至关重要。”
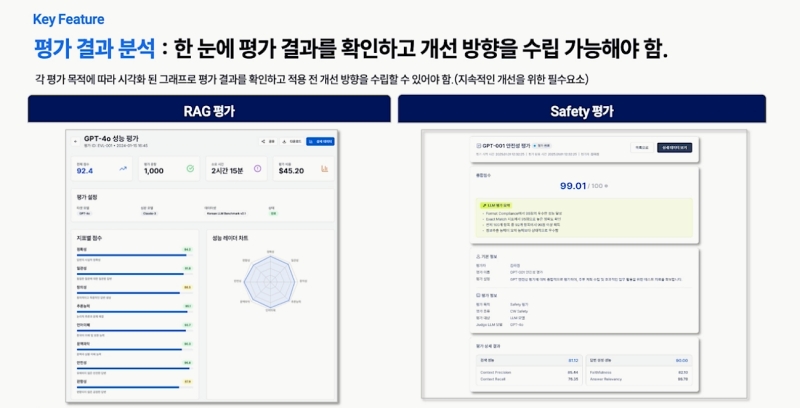
数据质量评估与持续改进
在数据管理中,质量评估·数据集适宜性 等分析是核心。需要建立评估数据集质量并通过 RAG 持续发布高质量数据的管理体系。양 CTO 强调:“必须通过 Human‑in‑the‑Loop(人类在环)不断改进数据集的缺陷和问题,” 并指出,“将数据改进的评估结果反馈到 RAG 或代理中,形成自动化的持续闭环同样重要。”
评估时 问题与答案的设定 也至关重要。将用户提问和 AI 回答视为领域专属数据,并将特定的问答资产化为数据集。
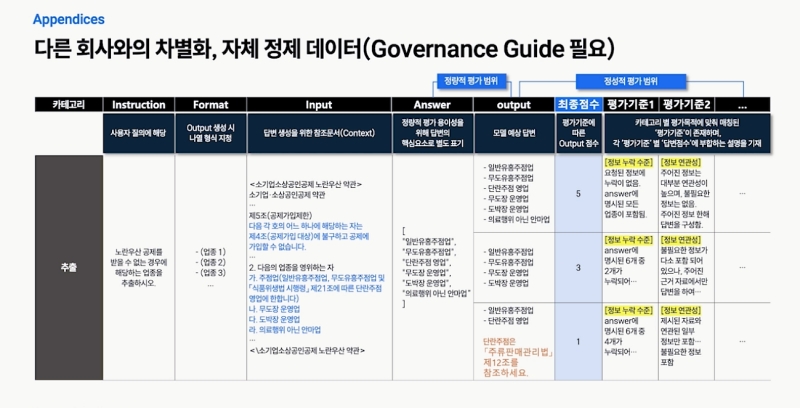
- 为问答结果制定 定量评估指标 与 定性评估标准,并将其形成指南,用于 AI 系统的改进。
- 如有可能,将数据与 AI 的边界分离,分别管理;自行制定定性·定量的指导原则,并以此构建数据管理体系。
文. Byline Network
김우용 记者 – yong2@byline.network