당신의 코딩 에이전트는 더 큰 컨텍스트 윈도우가 필요하지 않다. 동료가 필요하다.
Source: Dev.to
저는 몇 달 동안 Claude Code로 작업해 왔습니다. 정말 인상적이지만, 코드베이스가 충분히 커져 에이전트가 자체 컨텍스트에 빠지기 시작하면 그때부터는 그렇지 않습니다.
1 M 토큰 컨텍스트 윈도우는 거대하게 들리지만, 실제 프로젝트—수백 개의 파일, 6단계 깊이의 import 체인, YAML 및 .env 파일에 흩어져 있는 설정—를 넣어보면 벽에 부딪히게 됩니다. 응답이 느려지고, 품질이 떨어지며, 비용이 상승하는데, 이는 모델이 질문과 무관한 코드를 읽는 데 토큰의 절반을 사용하기 때문입니다.
본능적으로 더 큰 컨텍스트 윈도우를 기다리게 되지만, 그것은 올바른 해결책이 아닙니다. 더 똑똑한 CTO가 된다고 해서 CTO가 직접 모든 코드를 검토해야 한다는 의미는 아닙니다.
Enter AgentHub – 코드베이스를 전문화된 에이전트들로 분할하고, 적절한 에이전트에 질의를 라우팅하며, 질문이 여러 도메인에 걸칠 때 이들이 협업하도록 하는 가벼운 Python 라이브러리입니다.
실제 상황에서의 문제
Django 프로젝트를 작업하고 있다고 가정해 보세요. 코딩 에이전트에게 이렇게 물어봅니다:
“결제 흐름은 어떻게 작동하나요?”
이제 에이전트는 인증 미들웨어, URL 라우팅, 직렬 변환기, 결제 서비스, Stripe 웹훅, 데이터베이스 모델, 테스트 픽스처… 모든 것을 하나의 컨텍스트 창에 로드하고 대부분은 관련이 없는 상태에서 처리해야 합니다.
실제 답은 2‑3개의 모듈에 걸쳐 있는 4‑5개의 파일 안에 있을 수 있지만, 에이전트는 사전에 이를 알지 못합니다. 모든 것을 흡수하고 토큰을 소모한 뒤, 한 번에 너무 많은 정보를 기억하려다 보니 희석된 답변을 제공합니다.
이는 용량 문제라기보다 라우팅 문제입니다.
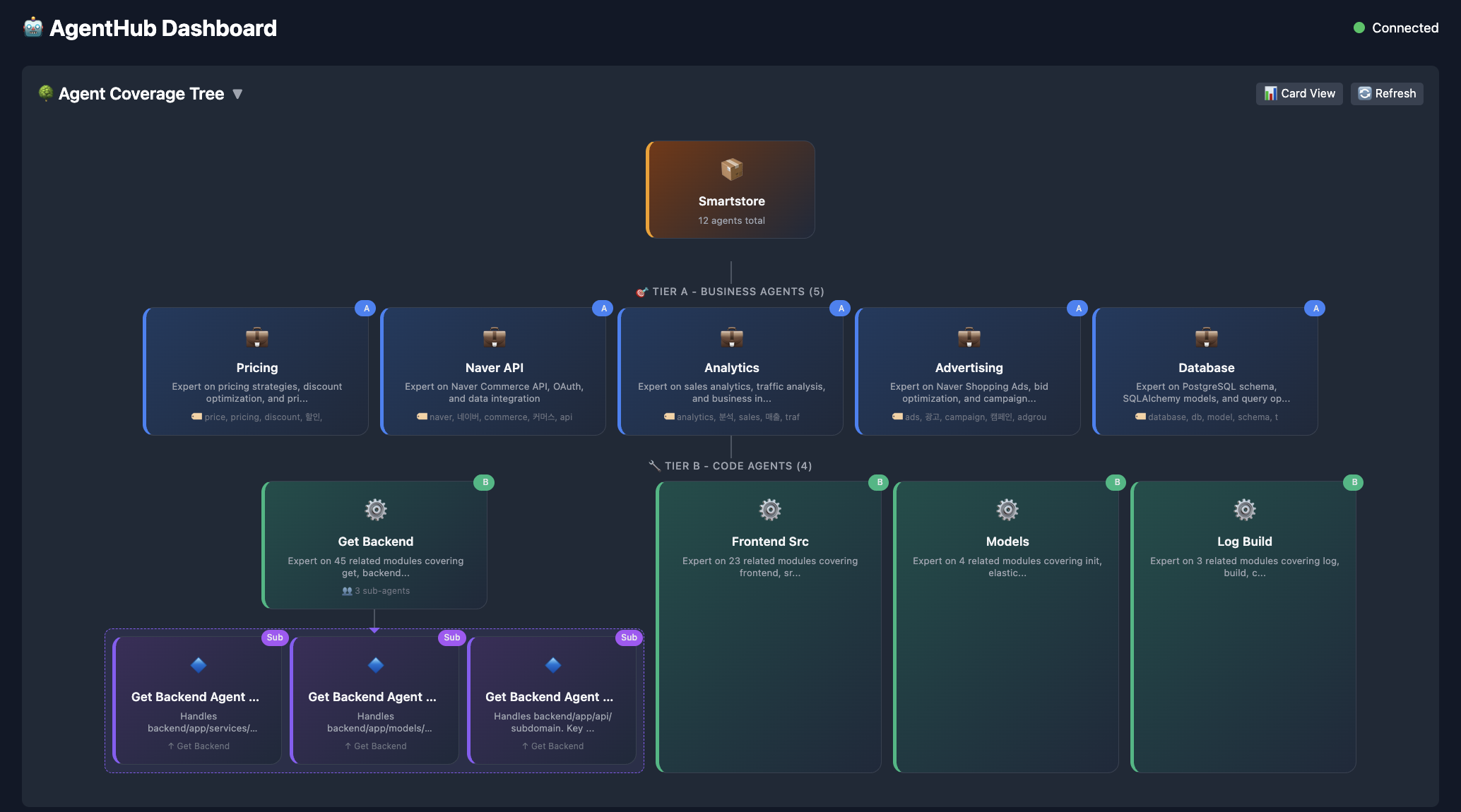
레이어 1: 자동 생성된 도메인 에이전트
첫 번째 통찰은 여러분의 코드베이스가 이미 자연스러운 경계가 어디인지 알려준다는 것입니다.
- 폴더 → 도메인
- 파일 → 책임
- 임포트 그래프 → 의존성
그 구조를 사용해 에이전트를 자동으로 생성해보면 어떨까요?
AgentHub의 build 명령은 리포지토리를 스캔하고 Tier B 에이전트를 생성합니다 — 논리적 도메인당 하나씩, 각 에이전트는 자신이 소유한 파일만 미리 로드됩니다.
from agenthub import AgentHub
from agenthub.auto import discover_all_agents
hub, summary = discover_all_agents("./my-project")
response = hub.run("How does user authentication work?")작동 방식
- 파일 트리 탐색 – 폴더 구조, 크기 및 언어를 매핑합니다.
- 임포트 그래프 구축 –
import문을 파싱하여 예를 들어api/views.py→services/auth.py→models/user.py와 같은 관계를 파악합니다. - 에이전트 생성 – 각 도메인에 속한 파일만을 컨텍스트 윈도우에 로드한 집중형 에이전트를 구축합니다.
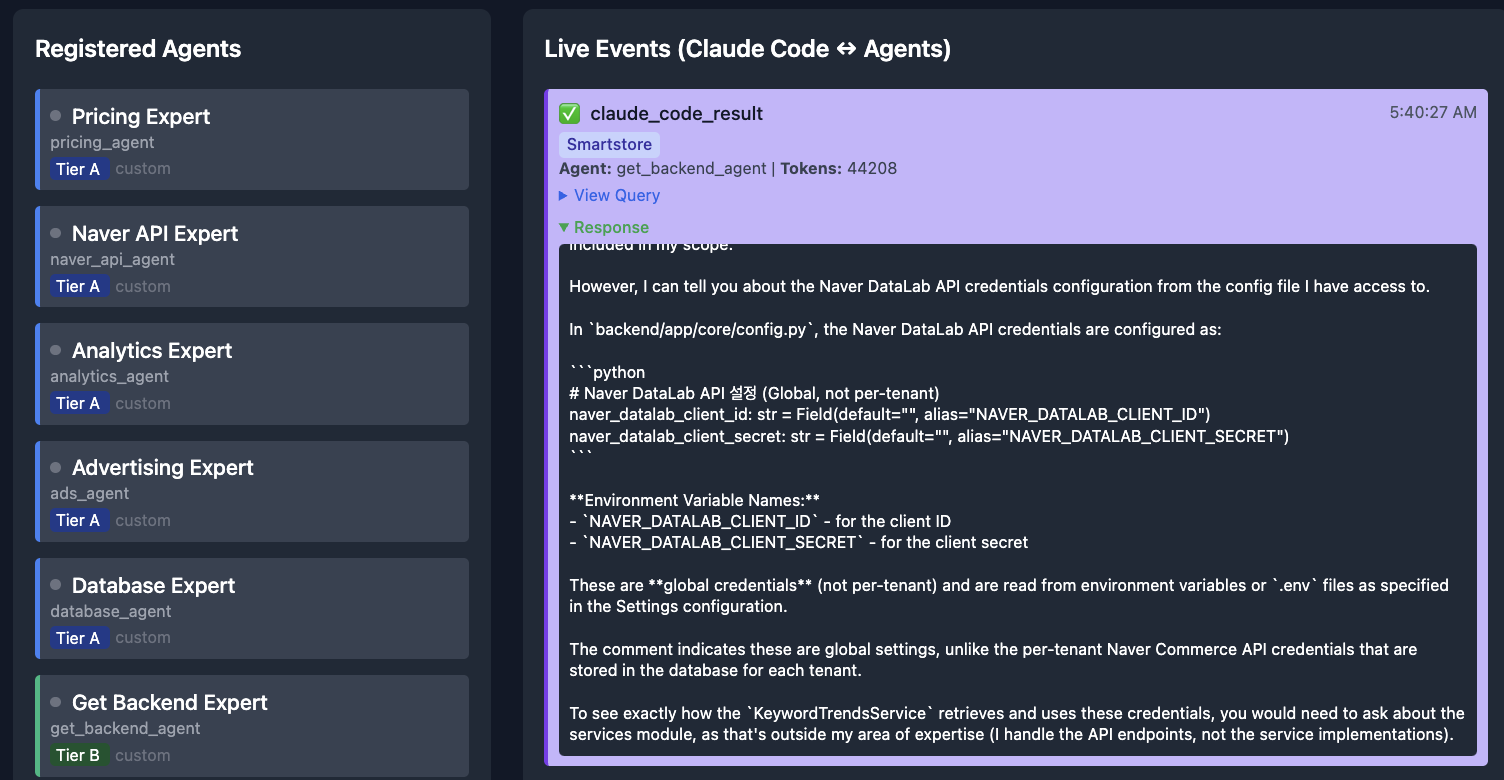
쿼리가 들어오면 라우터가 각 에이전트의 키워드와 도메인에 대해 점수를 매겨 가장 적합한 에이전트에 전달합니다:
src/api/에이전트 → API 관련 질문src/models/에이전트 → 스키마 관련 질문
불필요한 토큰이 없습니다.
Tier A 에이전트(선택)는 코드 구조만으로는 추론할 수 없는 비즈니스 로직을 위해 직접 작성됩니다. 예를 들어 마진 규칙을 알고 있는 가격 에이전트나 KPI 정의를 알고 있는 분석 에이전트 등이 있습니다.
레이어 2: 교차 질문을 위한 DAG 팀
단일 에이전트 라우팅은 범위가 제한된 질문(예: “UserSerializer 클래스는 무엇을 하나요?”)에 매우 효과적입니다. 하지만 교차 질문(예: “체크아웃 흐름은 전체적으로 어떻게 작동하나요?”)에서는 잘 작동하지 않으며, 답변이 API, 서비스, 모델, 결제 레이어에 걸쳐 존재합니다.
이를 위해 AgentHub는 DAG 팀을 생성합니다:
- Complexity classifier는 쿼리가 여러 도메인에 걸쳐 있음을 감지합니다.
- Decomposer는 관련 에이전트를 식별합니다.
- Import graph는 에이전트 간의 의존성 엣지를 제공합니다.
- Execution – 독립적인 에이전트는 병렬로 실행되고, 의존적인 에이전트는 순차적으로 실행됩니다.
- Synthesizer는 결과를 하나의 일관된 답변으로 합칩니다.
DAG는 쿼리당 import graph를 기반으로 구축되므로, 협업 구조가 실제 코드 연결을 반영하며, 상상된 아키텍처가 아닙니다.
레이어 3: 병렬 세션
개발자가 “툴바에 저장 버튼을 추가하고 그리고 시계열 차트 컴포넌트를 만들라”고 말하면, 이는 완전히 다른 파일을 건드리는 두 개의 독립적인 작업이다. 현재 코딩 에이전트는 이를 순차적으로 처리한다. 왜 병렬로 실행하지 않을까?
AgentHub의 병렬 세션 레이어:
- 다중 파트 요청을 별개의 작업으로 분해한다.
- import 그래프를 사용해 파일 겹침을 분석한다.
- 겹치지 않는 작업에 대해 별도의 Git 브랜치에서 독립적인 Claude Code 세션을 띄운다.
- 각 세션은 해당 작업에 관련된 파일들만을 스코프로 한다.
- 머지 코디네이터가 브랜치를 합치고, 테스트를 실행하며, Git만으로는 감지할 수 없는 의미적 충돌을 잡아낸다.
이를 회사 모델에 비유하면: 스타트업이 두 사람일 때 CTO(당신의 코딩 에이전트)는 모든 것을 안다. 회사가 성장함에 따라 각 지식 조각을 담당하는 전문가들(Tier B 에이전트)을 고용하고, CTO는 협업을 조율한다.
Overview
부서가 커지면 팀(DAG 팀)을 조직합니다. 그리고 전사적인 이니셔티브가 있을 때, 팀들은 각각의 트랙에서 동시에 작업하고 경계에서 동기화합니다.
병합 단계가 복잡해지는 부분입니다. 텍스트 충돌은 간단합니다 — git이 이를 처리합니다. 의미적 충돌은 더 어렵습니다: 두 브랜치가 깔끔하게 병합되지만 서로의 가정을 깨뜨리는 경우. 이런 경우 AgentHub가 병합 후 테스트 스위트를 실행합니다. 테스트가 실패하면, 해결 에이전트가 실패를 검토하고 충돌한 변경 사항을 추적하여 수정하거나 개발자에게 에스컬레이션합니다.
Where It Stands
AgentHub는 v0.1.0입니다. 핵심 자동‑에이전트 생성, DAG 팀, 그리고 병렬‑세션 인프라가 모두 구현되었습니다. 파이썬 CLI 형태로 제공되며 MCP를 통해 Claude Code와 통합되어, 에이전트가 터미널 안에서 바로 도구로 나타납니다.
Current Status
- Auto‑agent generation – 잘 작동합니다; 레포지토리를 지정하면 유용한 에이전트를 얻을 수 있습니다.
- DAG teams – 기능은 동작하지만 분해 프롬프트에 대한 조정이 필요합니다.
- Routing layer – 어떤 에이전트가 쿼리를 처리할지 결정하는 부분은 아직 수동으로 튜닝해야 하며, 다양한 코드베이스에서 신뢰성 있게 동작하도록 개선이 필요합니다.
- Parallel sessions – 대부분 실험 단계이며, git 오케스트레이션은 견고하지만 의미적 충돌 해결은 아직 다소 거칠습니다.
아직 오픈소스로 공개하지는 않습니다. 라우팅과 에이전트 품질을 만족스러운 수준으로 끌어올릴 때까지는 공개하고 싶지 않은 거친 부분들이 남아 있기 때문입니다. 하지만 핵심 아이디어—에이전트 경계에 import 그래프를 활용하고, DAG 기반 협업 및 기업 성장 모델—는 구현 방식과 관계없이 유용하다고 생각해 아키텍처를 공유합니다.
코딩 에이전트를 사용하면서 컨텍스트 제한에 부딪히는 경우, 여러분이 어떻게 해결하고 있는지 알려주시면 좋겠습니다.
Built by John. The entire AgentHub codebase was developed collaboratively with Claude — which felt appropriately recursive.