클라우드 네이티브가 에이전트 AI 핵심에 자리 잡는 이유: Kubernetes 기반 멀티‑에이전트 보안 플랫폼 구축 교훈
Source: CNCF Blog
Posted on June 17, 2026
In March, I gave a talk at KubeCon + CloudNativeCon Europe 2026 in Amsterdam. After the session, the same questions kept coming up on the CNCF Slack and in person: why build agentic AI on cloud native foundations at all? Which CNCF projects actually do the heavy lifting? Where does the human sit, and how do you organise the teams around it? What follows is the short answer, drawn from a system we are currently developing and rolling out at Orange Innovation.
The context: an internal real‑time security‑operations platform protecting a regulated production environment, currently in active development with a rollout underway. A2A protocol for inter‑agent coordination (open‑sourced in 2025, now under the Linux Foundation). MCP for environment integration (hosted under the Agentic AI Foundation, an LF project). Falco with eBPF intercepts every syscall on the workloads we monitor; events flow through Kafka into an Isolation Forest classical anomaly model that pre‑filters in front of the LLM‑driven agents. The goal is to materially shorten mean time to detect and respond, and to offload rule authorship from human analysts to the agent layer. The lessons below are written for that context, but apply equally to any cloud native estate where a SOC team and a platform team share responsibility for what runs in production.
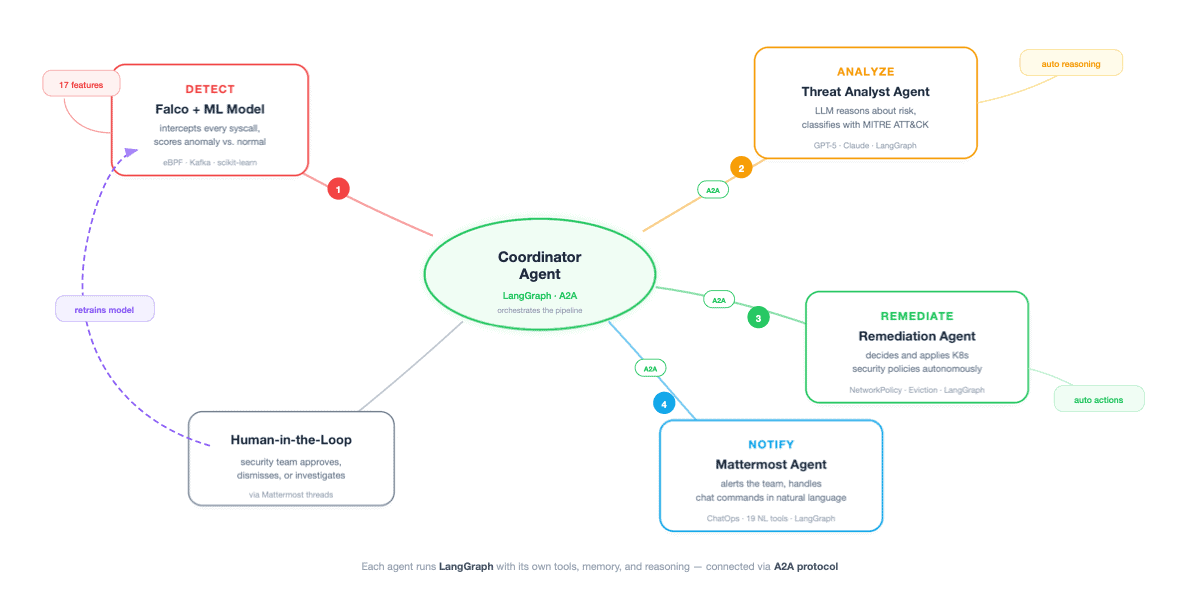
Figure 1: System overview. A Coordinator Agent (LangGraph + A2A) orchestrates four specialised agents: Detect (Falco + ML), Analyse (Threat Analyst), Remediate, and Notify (Mattermost), plus a Human‑in‑the‑Loop branch and a feedback loop that retrains the anomaly model. Adapted from my talk at KubeCon + CloudNativeCon Europe 2026.
Below are five technical lessons that have held up so far; how we organized the work across teams and the community, and a closing note on why the CNCF and LF stack is the right substrate for this kind of system.
1. Each agent is a Kubernetes workload, not an in‑process module
We deploy each agent as its own Deployment, with its own resource limits, identity, and restart policy. Most agents run LangGraph internally for their tool‑use and reasoning loop; a few are hand‑written without a framework where we need tighter control (see “Why this stack” below). The agent layer behaves like any microservice mesh: canary rollouts, HPA, namespace isolation apply without invention. The opposite pattern (all agents in one process) is faster to demo on a laptop and would be wrong in production. One agent stuck on a model‑API timeout drags the rest down.
2. Inter‑agent traffic needs mTLS, not a service mesh
A2A messages carry proposed detection rules and response actions; the threat model says they are at least as sensitive as the data plane.
We do not run a service mesh. cert‑manager issues per‑agent identities; agents perform mTLS directly at their gRPC/HTTP transport, with no sidecar. Cilium provides the network substrate and CiliumNetworkPolicy restricts which agent identities may reach which MCP server. The combination (cert‑manager + agent‑level mTLS + CiliumNetworkPolicy) is materially simpler than a mesh and gives us what a mesh would have given us.
Of all our choices so far, A2A is the one I would make again without hesitation. Open‑sourced in 2025, governed under the Linux Foundation, not bound to a single framework, so operators can plan a 3‑to‑5‑year deployment around it. Pairing A2A (LF) with the CNCF stack (LF) puts the whole substrate under one open governance umbrella, which in regulated industries is a procurement argument as much as a technical one.
3. Agent safety constraints are policy‑as‑code, not LLM prompt reasoning
In our architecture, a reviewer agent decides whether a proposed action is safe to execute. That could be a detection rule deployment, a containment, a firewall change. The instinct is to put safety constraints in the reviewer’s system prompt. Don’t.
Upstream of the reviewer, a threat‑analyst agent classifies each escalation against the MITRE ATT&CK framework, so the reviewer gets a structured input rather than free‑form LLM prose. We codified the reviewer’s constraints as OPA policies and Kyverno admission rules. The reviewer calls into OPA via MCP, gets a deterministic verdict, and acts. The reviewer’s prompt itself is short and, frankly, boring. The policy is version‑controlled, unit‑tested, and code‑reviewed like any other artefact. If there is one change to make before anything else, it is this one.
4. Observability rides the A2A trace_id, GitOps owns the configuration
The A2A envelope carries a trace_id with every task; that trace_id is what holds our observability together. Agents emit structured JSON logs with the trace_id, the agent identity, the MCP calls made, and the LLM token usage. Prometheus scrapes per‑agent metrics (request rates, MCP‑call latency, reviewer auto‑execute / auto‑reject / escalate ratios). Cilium Hubble gives the flow view when the question is “did the right pod reach the right service”.
The first time we walked an internal stakeholder through a specific automated decision during development, we pulled every entry for that trace_id and lined them up. The whole reasoning chain walked through in about fifteen minutes. Without trace_id propagation through A2A, it would have been a day.
Every agent’s system prompt, tool list, and output schema is a Kubernetes Custom Resource, reconciled by Argo CD from Git. The reviewer’s policy bundle lives in the same repo. Promoting a change is a pull request: code‑reviewed, audited, reversible. This is where most early multi‑agent deployments fall over: prompts scattered across notebooks and config files until the day an agent surprises someone.
5. Gate the LLM with a classical anomaly model
If every event triggered the full agent fan‑out, the LLM tier would dominate the platform’s economics. A scikit‑learn Isolation Forest sits in front of the agents, scoring each sample in microseconds on 17 features; only samples above a calibrated threshold reach the agent fan‑out. The LLM is invoked on the small fraction that looks genuinely novel: exactly the slice of work a human detection engineer used to do. Per‑event latency and token cost both stay bounded, and sizing the LLM tier becomes normal capacity planning.
The Isolation Forest retrains weekly by design, and feature‑distribution drift is itself a paged Prometheus metric. The anomaly threshold is not a static constant. It is a policy parameter the reviewer consults at decision time. We can tighten it under load without redeploying agents.
Keep the human in the loop, by protocol, not by culture
Every consequential decision has three terminal states. Auto‑execute. Auto‑reject. Or escalate to a human SOC analyst on Mattermost, with the full reasoning chain attached and ChatOps commands to approve, dismiss, or investigate inline. The third is not an error path; it is a normal output of the reviewer. It is designed to fire in three cases: reviewer confidence falls below threshold; the asset is on an always‑escalate list (control‑plane components, identity stores, anything customer‑facing or compliance‑sensitive); or the proposed action would exceed a configured blast radius.
“Should this case escalate?” is a deterministic policy verdict, version‑controlled in Git, with its own SLO and dashboards. It is not a question of