감시자를 누가 감시하나요? 에이전트 신뢰성을 위한 LLM-as-a-Judge 구축
Source: Dev.to
시작하기 전에
전제 조건: 기존 에이전시 워크플로우( MCP Forensic Series 참고)와 고‑추론 모델(Claude 3.5 Opus 또는 GPT‑4o) – 판사 역할을 할 모델이 필요합니다.
1. “골든 데이터셋”
에이전트를 평가하려면 정답 키가 필요합니다. tests/golden_dataset.json을 생성하세요. 여기에는 “정답”—오류가 존재한다는 것이 확실한 시나리오가 들어갑니다.
{
"test_id": "TC-001",
"input": "The Great Gatsby, 1925",
"expected_finding": "Page count mismatch: Observed 218, Standard 210",
"severity": "high"
}감독자 메모: 기업 환경에서는 “신뢰성”이 “권한 부여”의 전제 조건입니다. $50k 규모의 오류가 발생하지 않는다는 것을 입증하기 전까지는 에이전트를 확장할 예산을 받기 어렵습니다. 이 프레임워크는 내부 설득에 필요한 데이터를 제공합니다.
2. 판사의 루브릭
좋은 판사는 단순 “예/아니오”를 넘어선 루브릭이 필요합니다. 평가 항목은 다음과 같습니다.
- 정밀도(Precision): 실제 오류만을 찾아냈는가?
- 재현율(Recall): 모든 실제 오류를 찾아냈는가?
- 추론(Reasoning): 왜 해당 레코드를 플래그했는지 설명했는가?
3. 복원력을 위한 리팩터링
우리는 흔히 발생하는 “시니어‑레벨” 함정—에이전트 로직을 하드코딩하는 문제—를 제거했습니다. 시스템 프롬프트를 Python 클라이언트에서 전용 config/prompts.yaml 파일로 이동시켰습니다. **명령어(Instructions)**와 **실행(Execution)**을 분리함으로써 가시성이 향상되고, 서로 다른 프롬프트 버전을 판사와 A/B 테스트하여 특정 모델에 가장 높은 정확도를 제공하는 버전을 찾을 수 있게 되었습니다.
4. 구현: 평가 루프
레포에 evaluator.py를 추가했습니다(GitHub 링크). 이 스크립트는 에이전트를 실행할 뿐 아니라 그들의 “생체 신호”도 모니터링합니다.
- 오류 투명성: 예외를 무시하던 방식을 구조화된 로깅으로 교체했습니다. 공급자가 실패하면 조용히 사라지는 대신 진단을 위해 사건이 로그에 기록됩니다.
- 핸드쉐이크: 루프는 포렌식 팀을 실행하고 로그를 수집한 뒤, 전체 패키지를 고‑추론 판사 에이전트에 제출합니다.
평가‑최적화 청사진
이 다이어그램은 “코드가 실행되는가?”에서 “지능이 품질 기준을 충족하는가?” 로의 전환을 보여줍니다. 폐쇄 루프 시스템은 단순 작업에 더 작은 모델을 선택해 비용 최적화를 시작하기 전에 반드시 필요합니다.
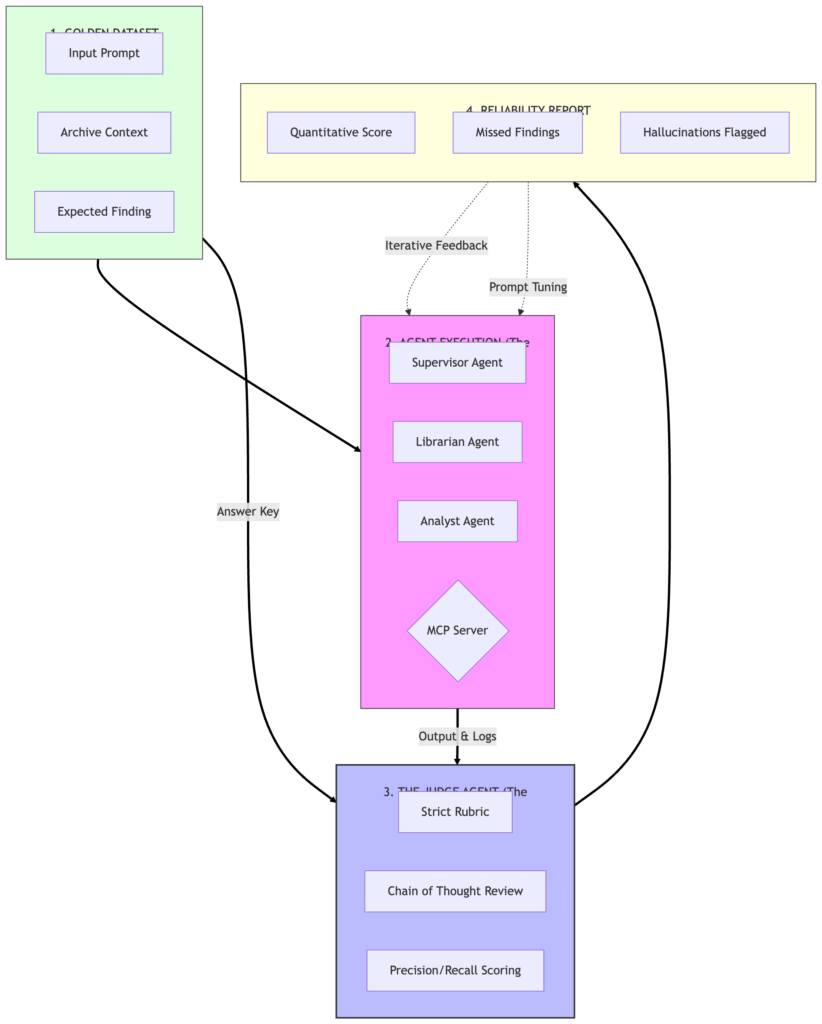
감독자 수준 인사이트: “정확도 vs. 비용” 곡선
감독자로서 나는 “토큰당 비용”보다 더 많은 것을 신경 씁니다. 방어 가능성이 필요합니다. 포렌식 감사를 받게 되면 과거 정확도 등급을 제시해야 하기 때문이죠. 이 평가자를 구현하면 “느낌 체크”에서 정량적 신뢰도 점수로 전환되어, 배포를 위한 최소 품질 기준을 설정할 수 있습니다. 모델 업데이트나 프롬프트 변경으로 정확도가 2 % 떨어지면 판사가 배포를 차단합니다.
프로덕션‑그레이드 AI 시리즈
- 포스트 1: 판사 에이전트 — 현재 위치
- 포스트 2: 회계사 (인지 예산 및 모델 라우팅) — 곧 공개
- 포스트 3: 가디언 (Human‑in‑the‑Loop 핸드쉐이크) — 곧 공개
기초가 궁금하신가요? 이전 시리즈를 확인해 보세요: The Zero‑Glue AI Mesh with MCP.