키워드만으로는 부족할 때: Elasticsearch를 활용한 더 똑똑한 검색 구축
Source: Dev.to
위에 제공된 소스 링크만 포함되어 있으며 번역할 실제 텍스트가 제공되지 않았습니다. 번역이 필요한 전체 내용을 알려주시면 한국어로 번역해 드리겠습니다.
Abstract
키워드 검색은 사용자가 질의를 저장된 문서와 다르게 표현할 때 종종 실패합니다. 저는 Elasticsearch와 벡터 임베딩을 활용한 의미 검색 시스템을 구축하여 이 격차를 메웠습니다. 이 블로그에서는 시스템이 어떻게 작동하는지, 구현 방법, 그리고 검색이 단순히 단어가 아니라 의미를 이해하기 시작했을 때 어떤 변화가 있었는지를 살펴보겠습니다.
처음에 눈치채지 못한 문제
처음에는 전통적인 키워드 검색만으로 충분하다고 생각했습니다. 이는 사용자 쿼리와 저장된 문서 사이의 용어를 매칭하여, 문서에 동일한 단어가 포함되어 있으면 더 높은 순위를 매깁니다. 간단하고 효율적이죠.
하지만 다음 쿼리를 테스트해 보았습니다:
“Affordable laptop for students”
내 데이터셋에는 다음과 같은 제품명이 있었습니다:
“Budget notebook with 8 GB RAM for college use”
사람에게는 이 두 문장이 명확히 연관됩니다:
- Affordable ↔ budget
- Laptop ↔ notebook
- Students ↔ college use
그럼에도 검색 엔진은 해당 제품을 매우 낮게 순위 매기거나 아예 반환하지 않았습니다. 단어가 정확히 일치하지 않기 때문에 시스템이 연관성을 고려하지 않은 것입니다.
의미가 동일하더라도 결과가 정확한 어휘에 크게 좌우된다는 것을 깨달았습니다. 실제 사용자들은 키워드가 아니라 아이디어로 생각합니다. 그래서 나는 생각하게 되었습니다: 검색이 단어 대신 의미를 비교한다면 어떨까?
의미 검색 이해
Semantic search sounds complex, but the core idea is surprisingly intuitive.
텍스트를 숫자로 변환 – 원시 텍스트를 저장하는 대신, 각 문장을 임베딩으로 변환합니다. 임베딩은 의미를 포착하는 부동소수점 값들의 리스트입니다.
Example:“Affordable laptop for students” → [0.021, -0.134, 0.889, …]Elasticsearch에 임베딩 저장 –
dense_vector필드 타입을 사용하여 각 문서마다 고유한 벡터를 저장합니다.벡터 비교 – 코사인 유사도(또는 다른 거리 측정법)를 사용해 고차원 공간에서 두 벡터가 얼마나 가까운지 측정합니다. 각도가 작을수록 의미적 유사도가 높습니다.
k‑Nearest Neighbors (kNN) – 질의 벡터가 주어지면 Elasticsearch가 가장 가까운 k개의 저장된 벡터를 찾습니다. 이 벡터들이 가장 관련성 높은 결과로 반환됩니다.
So instead of asking, “Does this document contain the same words?” we ask, “Is this document semantically close to the query?” That shift changes the entire behavior of search.
시스템 작동 방식
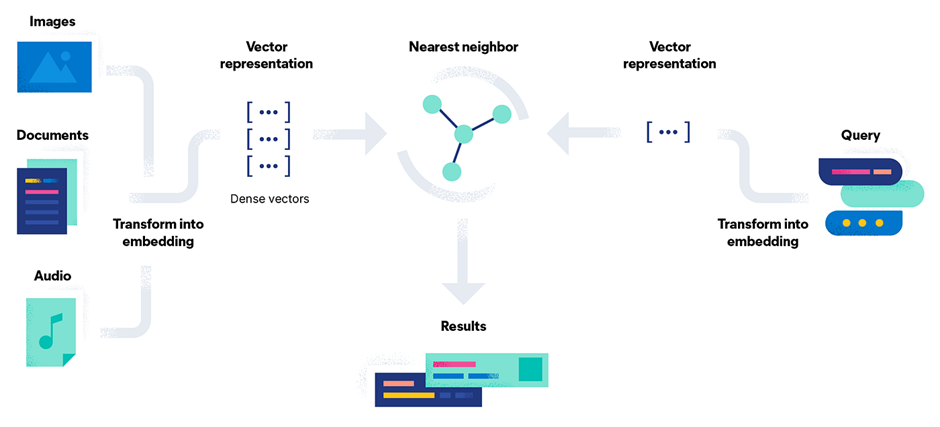
- 사용자 질의 → 임베딩 – 사용자가 질의를 입력하면, 트랜스포머 모델(예: sentence‑transformer)이 이를 실시간으로 임베딩으로 변환합니다.
- 문서 임베딩은 이미 저장되어 있음 – Elasticsearch에 있는 모든 문서는
dense_vector필드에 임베딩이 저장되어 있습니다. 이 벡터들은 인덱싱 과정에서 생성되었습니다. - kNN 검색 – Elasticsearch는 kNN 쿼리를 실행하여, 질의 벡터와 저장된 모든 벡터를 코사인 유사도로 비교하고 가장 가까운 매치를 찾아냅니다.
- 결과 반환 – 의미적으로 가장 유사한 문서들이 사용자에게 반환됩니다.
개념적으로는 “고차원 공간에서 거리 비교”일 뿐이며, 구현은 다소 고급스럽게 느껴질 수 있습니다.
단계별 구축
1. Elasticsearch 설정
Elastic Cloud에 Elasticsearch를 배포했습니다. 관리형 서비스를 이용하면 로컬 인스턴스를 직접 실행하는 것보다 설정이 훨씬 빨라집니다. 몇 분 안에 Kibana와 Python 클라이언트를 통해 접근 가능한 클러스터를 확보했습니다.
2. 인덱스 매핑 생성
임베딩을 저장하기 위해 384 차원( all‑MiniLM‑L6‑v2 문장‑트랜스포머의 출력 크기) dense_vector 필드를 정의했습니다.
PUT products
{
"mappings": {
"properties": {
"title": { "type": "text" },
"description":{ "type": "text" },
"embedding": {
"type": "dense_vector",
"dims": 384
}
}
}
}교훈: 매핑에 지정한 차원 수가 실제 벡터 크기와 일치하지 않으면 Elasticsearch가 문서를 거부합니다. 이 부분은 유연하게 조정할 수 없습니다.
3. 임베딩 생성
Python에서 sentence-transformers 라이브러리를 사용했습니다:
from sentence_transformers import SentenceTransformer
model = SentenceTransformer('all-MiniLM-L6-v2')
def embed(text: str):
return model.encode(text).tolist() # 384개의 float 리스트 반환이 모델은 가볍고 빠르며 강력한 의미 표현을 제공하므로 소규모‑중간 규모 데이터셋에 적합합니다.
4. 문서 인덱싱
각 제품에 대해 제목과 설명을 연결하고, 임베딩을 생성한 뒤 문서를 인덱싱했습니다:
doc = {
"title": title,
"description": description,
"embedding": embed(f"{title} {description}")
}
es.index(index="products", id=product_id, document=doc)5. 검색
두 가지 접근 방식을 시도했습니다:
| 접근 방식 | 설명 |
|---|---|
| 전통적인 키워드 검색 | title/description에 대한 match 쿼리. |
| 시맨틱 kNN 검색 | embedding 필드에 대한 코사인 유사도를 이용한 script_score. |
시맨틱 접근 방식은 쿼리에 동의어가 포함되거나 표현이 달라져도 일관되게 관련 결과를 반환했습니다.
최종 생각
키워드 매칭에서 의미 유사성으로 전환함으로써 부서진 검색 경험을 사용자 의도를 진정으로 이해하는 것으로 바꾸었습니다. 문장‑transformers를 활용한 임베딩과 Elasticsearch의 dense_vector + kNN 기능을 이용하면 비교적 적은 인프라 오버헤드로 강력하고 의미를 인식하는 검색 시스템을 구축할 수 있습니다. 즐거운 검색 되세요!
키워드 vs. 벡터 검색: 나의 첫 번째 실습 테스트
최근에 제품 카탈로그 검색을 위해 두 가지 접근 방식을 비교하는 작은 프로토타입을 만들었습니다:
- 키워드 매치 쿼리 – 빠르고 간단하지만, 동의어가 많은 쿼리에서는 어려움을 겪었습니다.
- k‑NN 벡터 쿼리 – 사용자 쿼리에 대한 임베딩을 실시간으로 생성하고 이를 Elasticsearch의 k‑NN 검색에 전달했습니다.
관련성 차이는 거의 즉시 눈에 띄었습니다.
### 결과 비교
제가 관찰한 내용을 간단히 정리하면 다음과 같습니다:
[](https://dev-to-uploads.s3.amazonaws.com/uploads/articles/6hp6is7y8t7wpyenqr3t.png)
- **속도** – 키워드 검색이 약간 더 빠른데, 이는 예상된 결과입니다.
- **관련성** – 벡터 검색이 사용자 의도와 일관되게 더 잘 맞았습니다.
- **지연 시간** – k‑NN 쿼리에서 약간 더 높았지만, 데이터셋 규모에 비해 여전히 허용 가능한 수준이었습니다. `num_candidates`와 같은 파라미터를 조정하면 성능이 더욱 향상되었습니다.
가장 눈에 띈 점은 속도가 아니라 **관련성**이었습니다. 시스템이 동의어와 문맥적 의미를 제대로 이해하기 시작했습니다.
### 가장 많이 배운 도전 과제
- **차원 불일치** – 인덱스 생성 후에 벡터 차원을 변경할 수 없어서 인덱스를 삭제하고 다시 구축해야 했습니다.
- **초기 느린 쿼리** – k‑NN 파라미터 튜닝이 부적절해 지연 시간이 발생했으며, 불필요한 후보 검사를 줄여 해결했습니다.
이러한 문제들은 큰 장애물은 아니었지만, Elasticsearch가 벡터를 내부적으로 어떻게 처리하는지 이해하는 데 큰 도움이 되었습니다.
### 실제 적용을 생각하며
프로덕션 환경에서는 **하이브리드 접근 방식**—키워드 매칭과 벡터 유사도를 결합하는 것이 정밀도와 재현율 사이의 최적 균형을 제공합니다. Elastic Cloud는 분산 검색 워크로드의 확장을 보다 쉽게 만들어 줍니다.
잠재적인 사용 사례는 다음과 같습니다:
- 전자상거래 사이트
- FAQ 검색 시스템
- 지식 베이스
- 지원 봇
사용자가 자연어로 원하는 것을 설명하는 모든 곳에서, 의미 검색은 실질적인 가치를 더합니다.
## 결론
이 프로젝트는 작은 불만에서 시작되었습니다: 기술적으로는 작동하지만 지능적으로 느껴지지 않는 검색 결과. Elasticsearch에 벡터 검색을 추가함으로써 단어 겹침만이 아니라 의미를 이해하는 시스템을 구축했습니다.
**핵심 요점**
- 임베딩은 강력하지만, 신중한 설정이 필요합니다. 작은 설정 실수 하나가 전체를 망칠 수 있습니다.
- 관련성은 단순히 텍스트를 일치시키는 것 이상이며, 의도를 해석하는 것입니다.
오늘날 검색 시스템을 구축한다면, 키워드에만 의존하는 것으로는 충분하지 않을 수 있습니다. 의미 검색이 결과를 어떻게 개선하는지 한 번 보면 그 차이를 무시하기 어렵습니다.