LLM이 다음 토큰을 선택할 때 실제로 일어나는 일🤯
발행: (2026년 1월 12일 오후 12:16 GMT+9)
5 분 소요
원문: Dev.to
Source: Dev.to
핵심 아이디어
프롬프트가 주어지면, 모델은 가능한 다음 토큰들에 대한 확률 분포를 예측합니다.
예시:
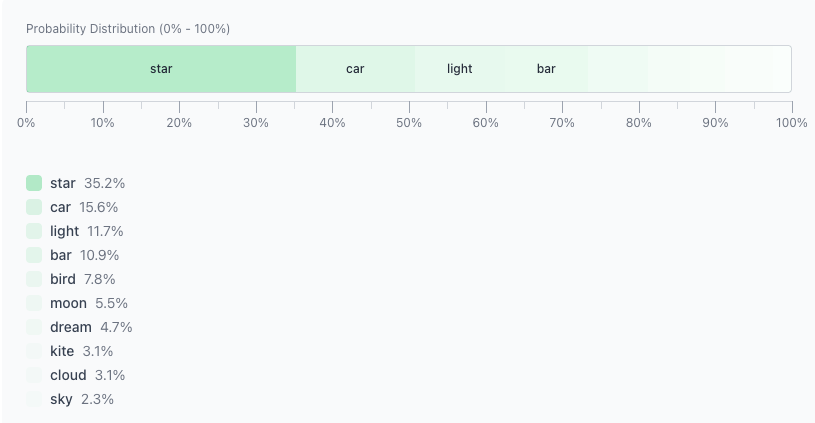
Twinkle twinkle little이 시점에서 모델은 각 후보 토큰에 확률을 할당합니다. 이를 0–100 스케일에 배치했다고 생각할 수 있습니다:
- 확률이 높을수록 → 더 큰 구간
- 확률이 낮을수록 → 더 작은 구간
샘플링: 실제로 일어나는 일
다음은 샘플링입니다. 실용적인 사고 방식:
- 무작위 숫자를 생성한다.
- 그 숫자가 어느 구간에 속하는지 확인한다.
- 해당 토큰을 출력한다.
“star” 가 가장 큰 구간을 차지하므로 가장 가능성이 높은 결과가 됩니다:
Twinkle twinkle little starTemperature, Top‑p, 그리고 Top‑k는 모두 이 샘플링 단계에만 영향을 미칩니다.
이후 기본값을 사용합니다:
- Temperature = 1
- Top‑p = 1
- Top‑k = 10
그리고 한 번에 하나씩 파라미터를 바꿔봅니다.
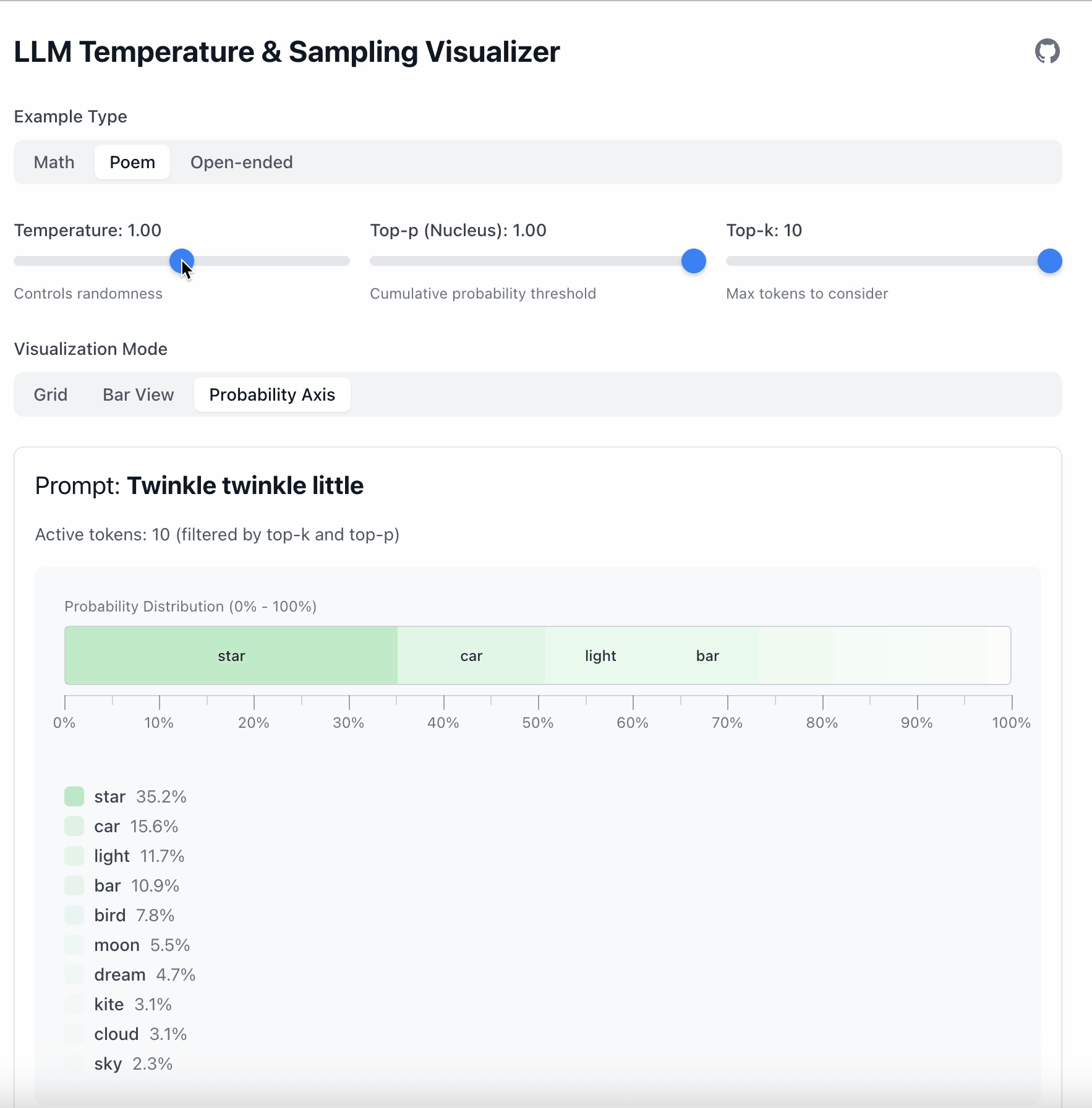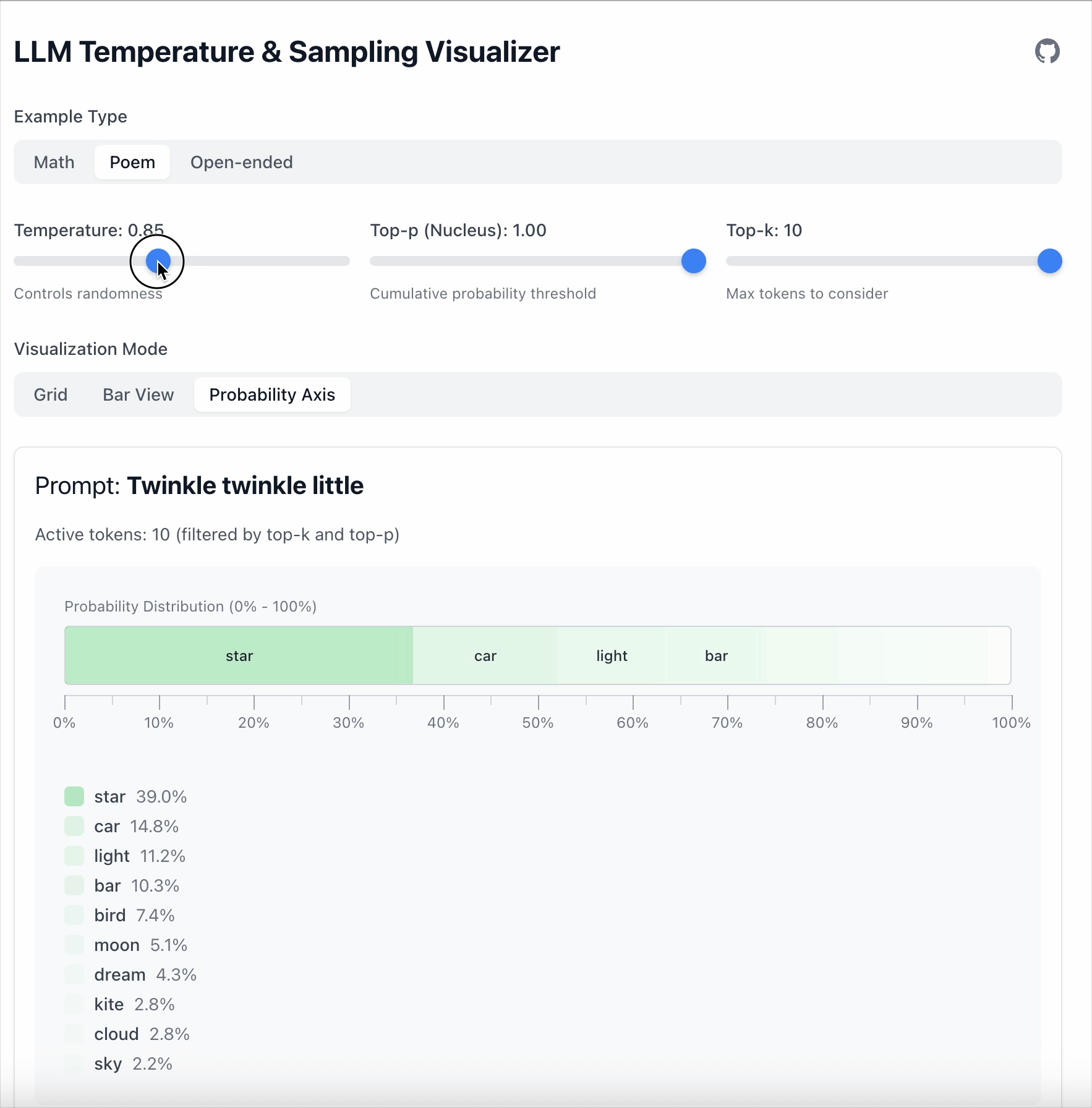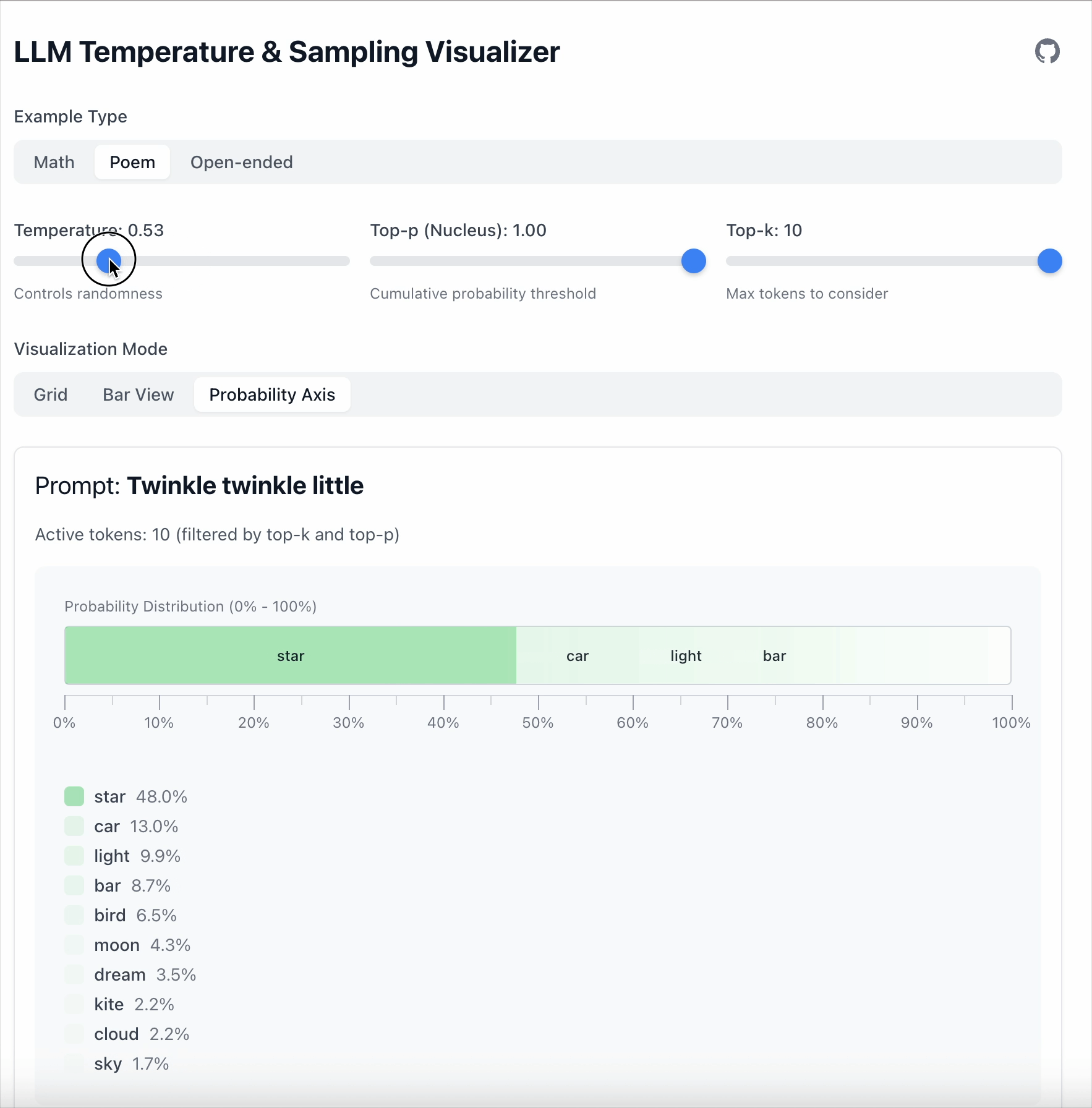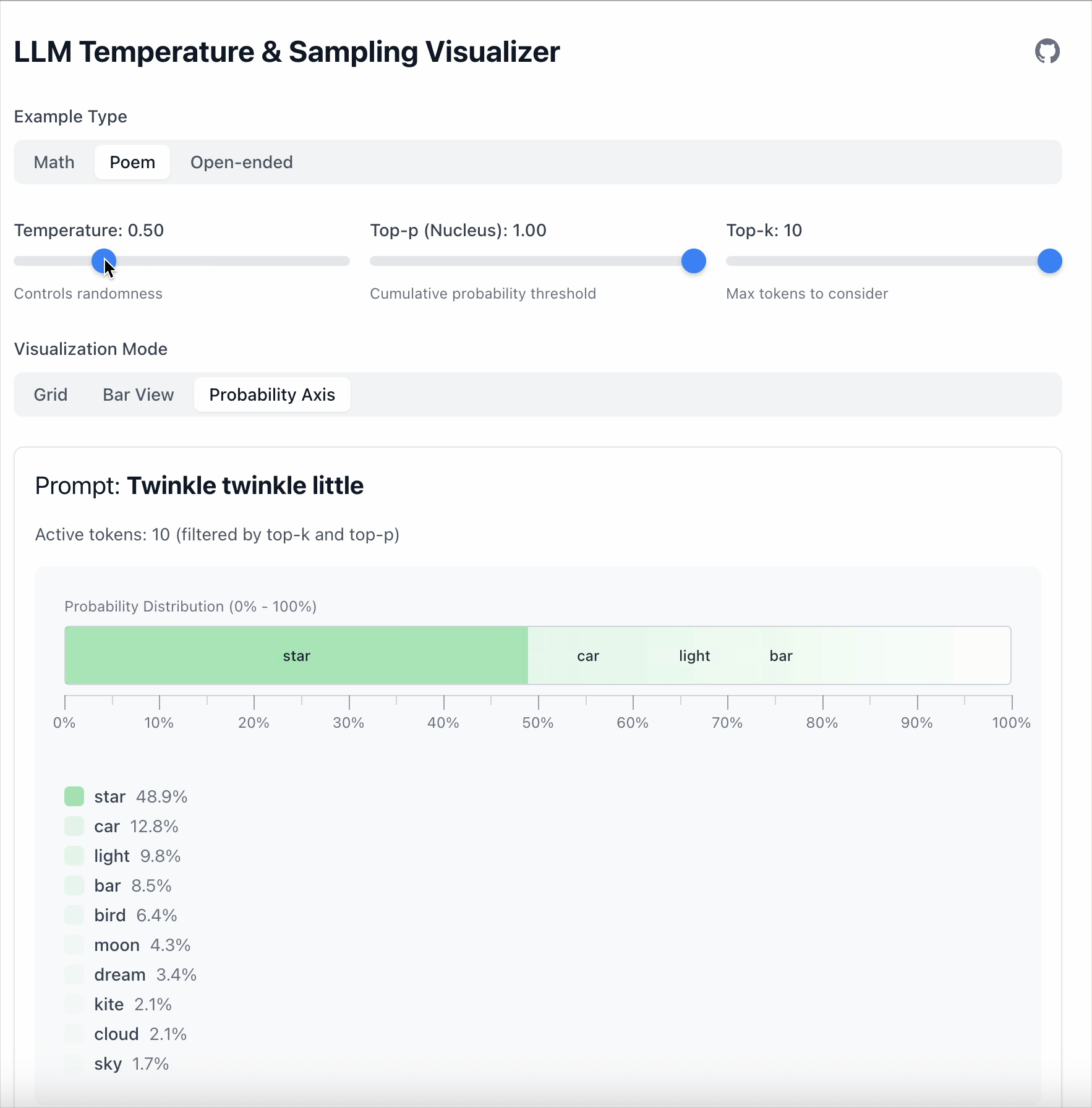
Temperature
Temperature는 한 가지 일을 합니다: 확률 차이를 늘리거나 평탄하게 만든다.
- 낮은 temperature → 강한 선호도 → 안정된 출력
- 높은 temperature → 평탄한 분포 → 더 많은 무작위성
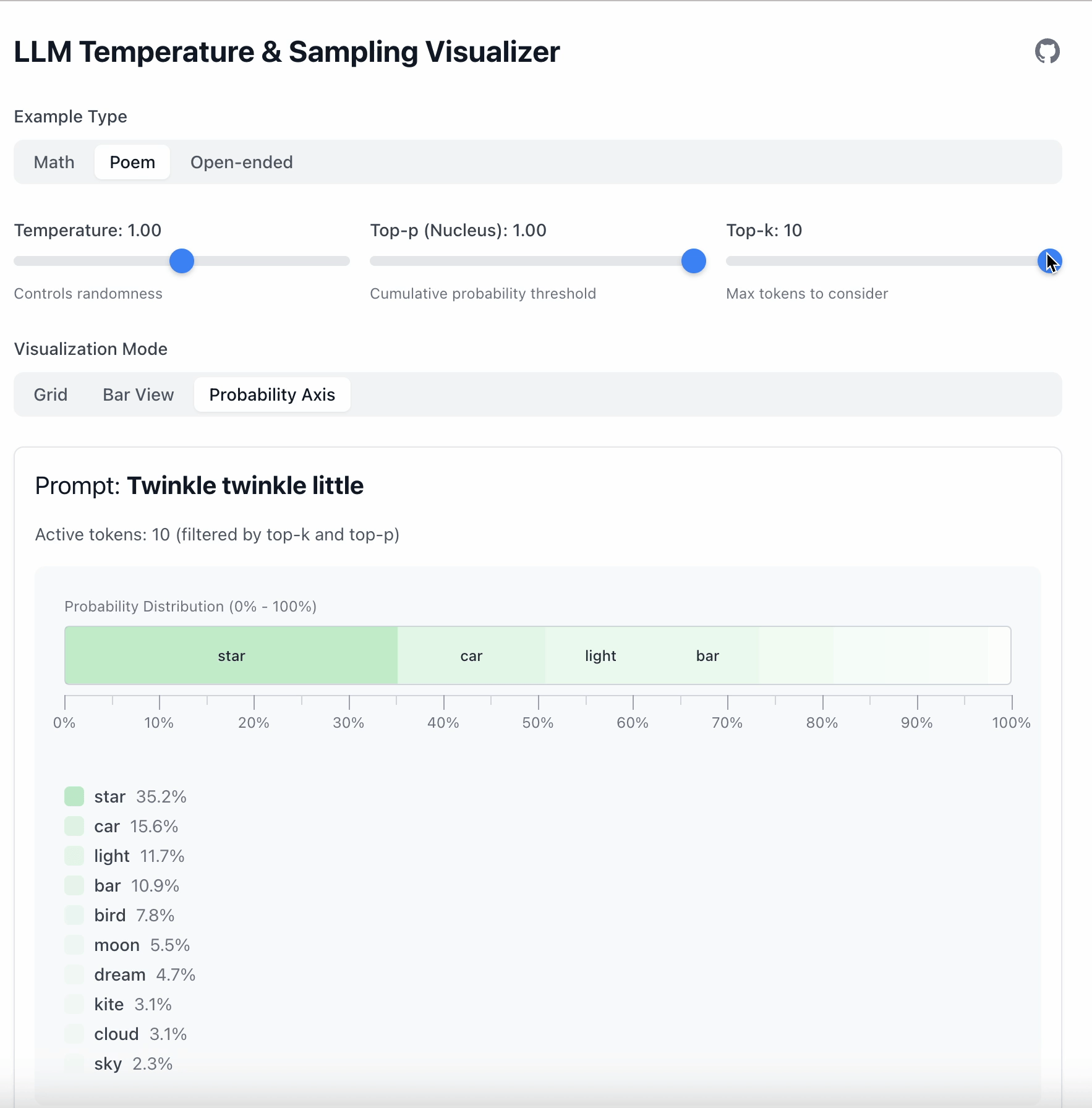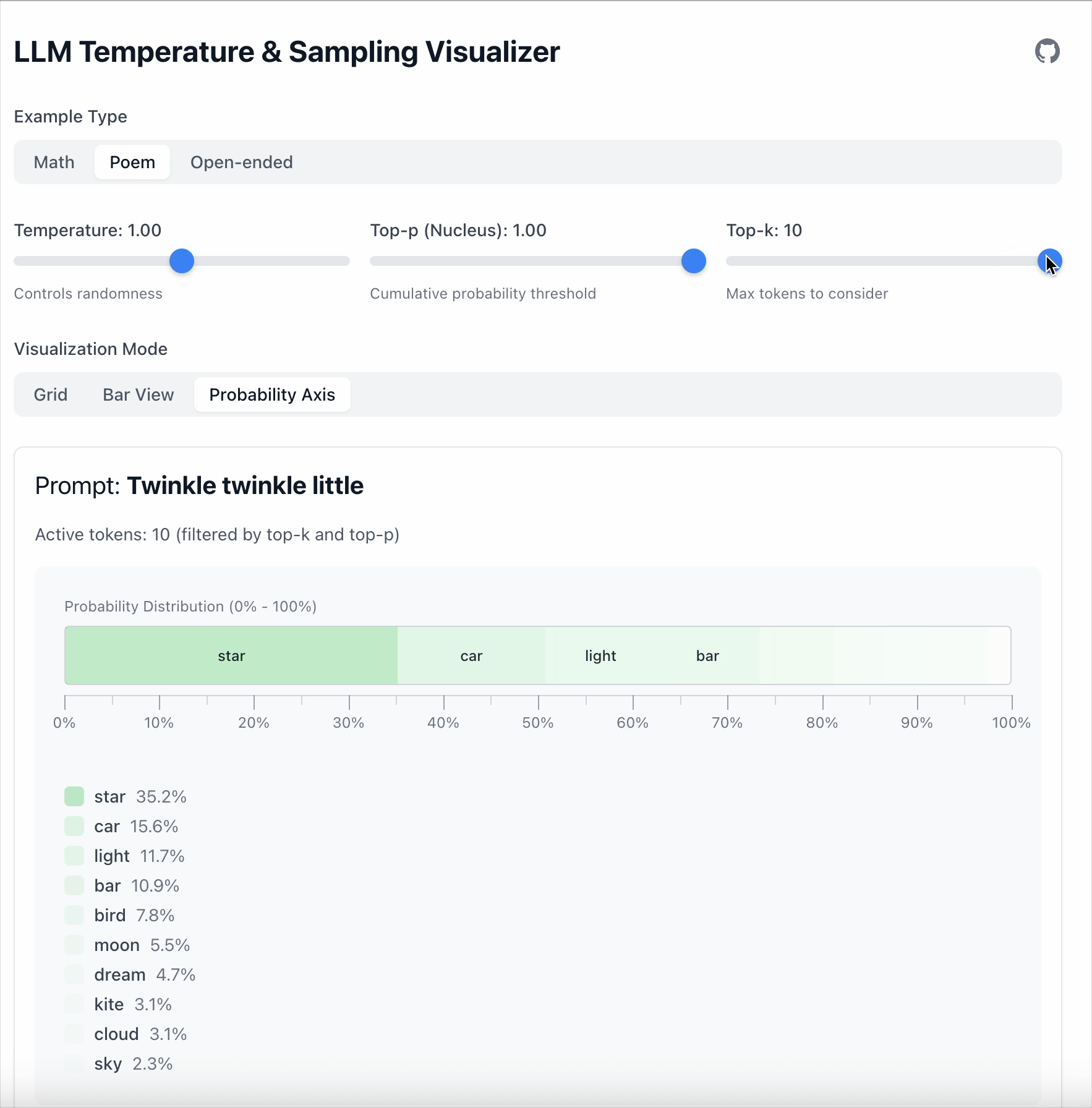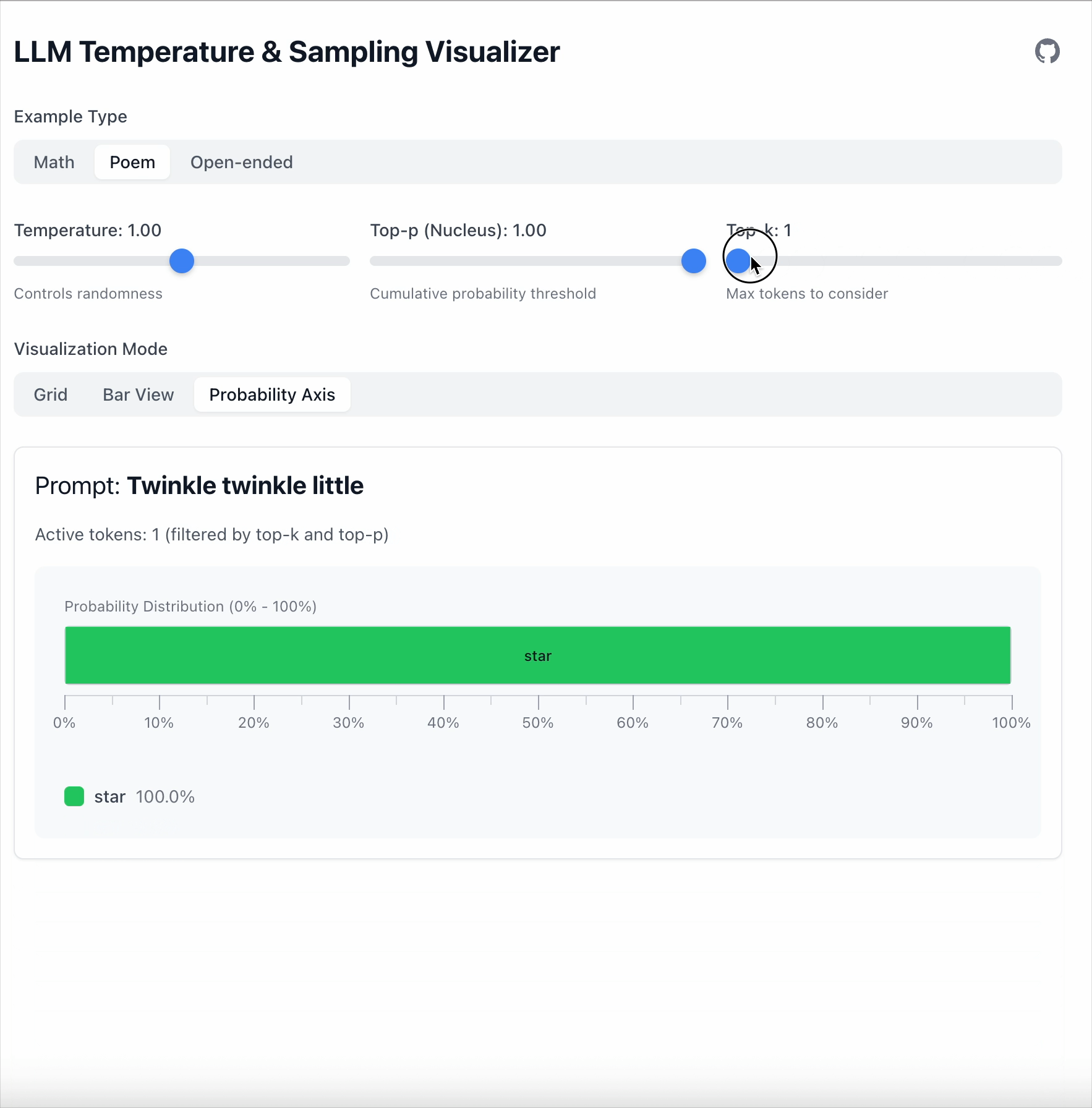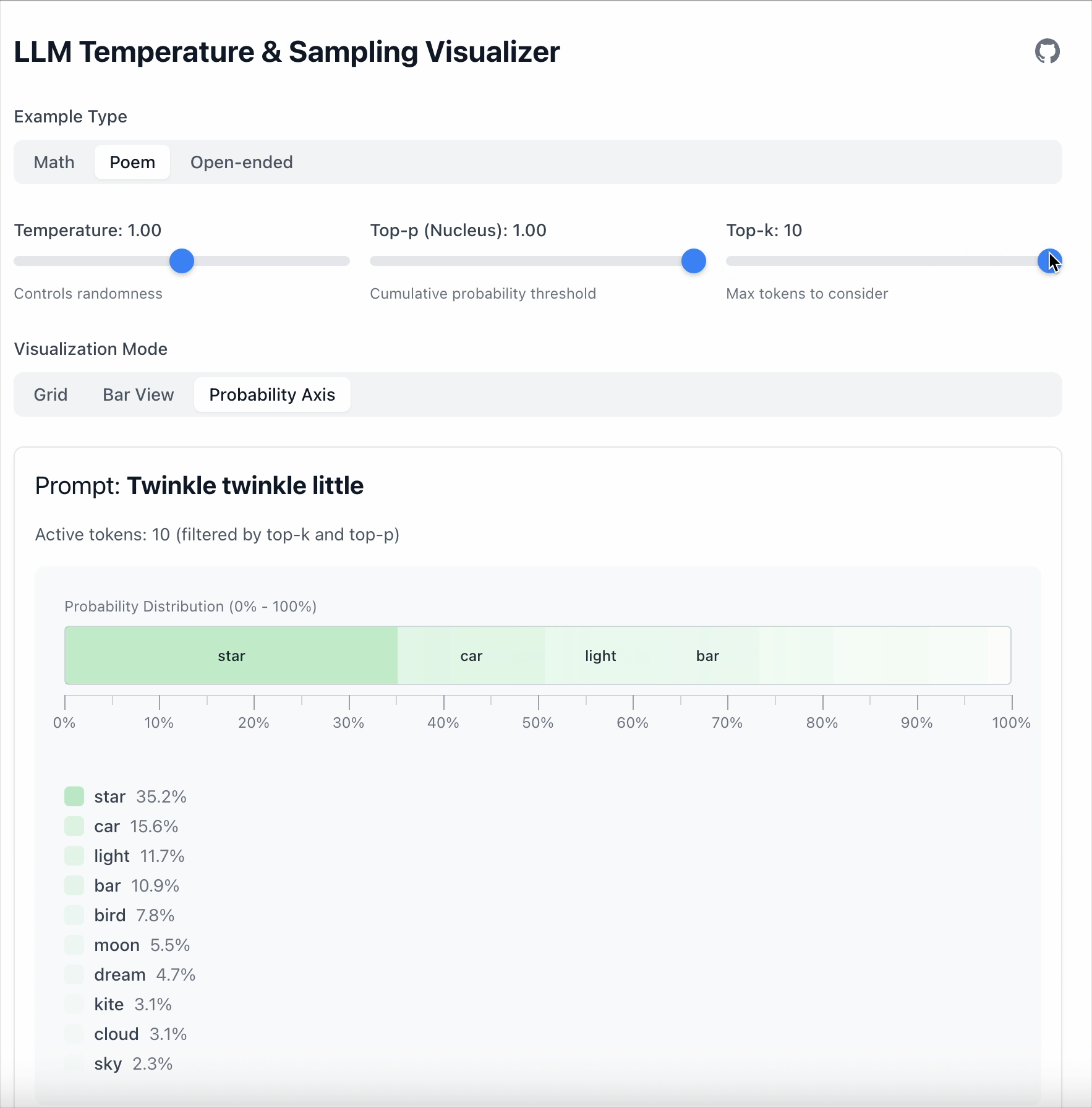
이 예시에서 “star” 와 “car” 사이의 차이는 19.6 입니다.
- Temperature = 0.5 로 설정하면 차이가 36.1 로 커집니다.
- Temperature = 1.68 로 설정하면 확률이 낮은 토큰들이 더 경쟁력을 갖게 됩니다.
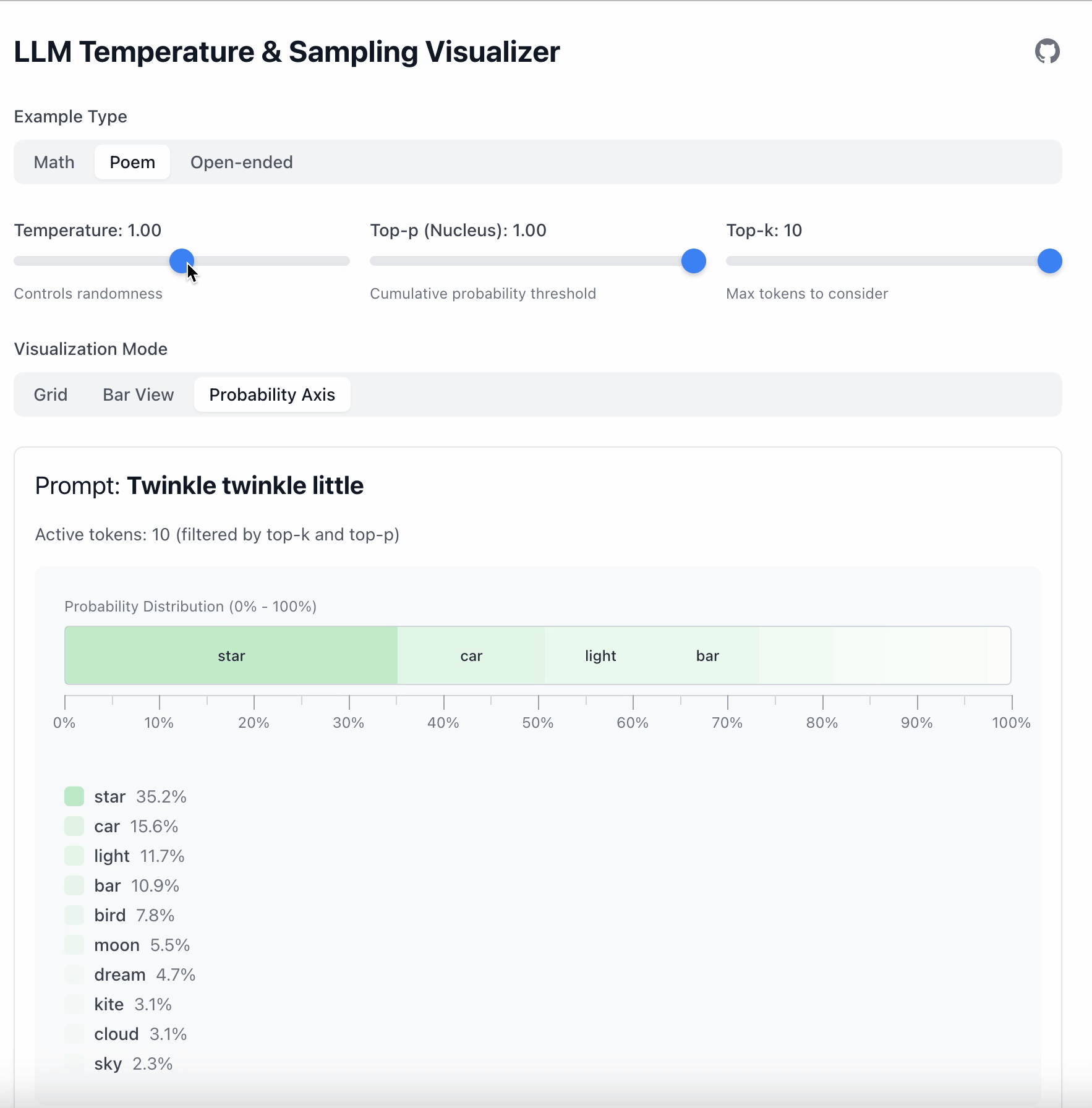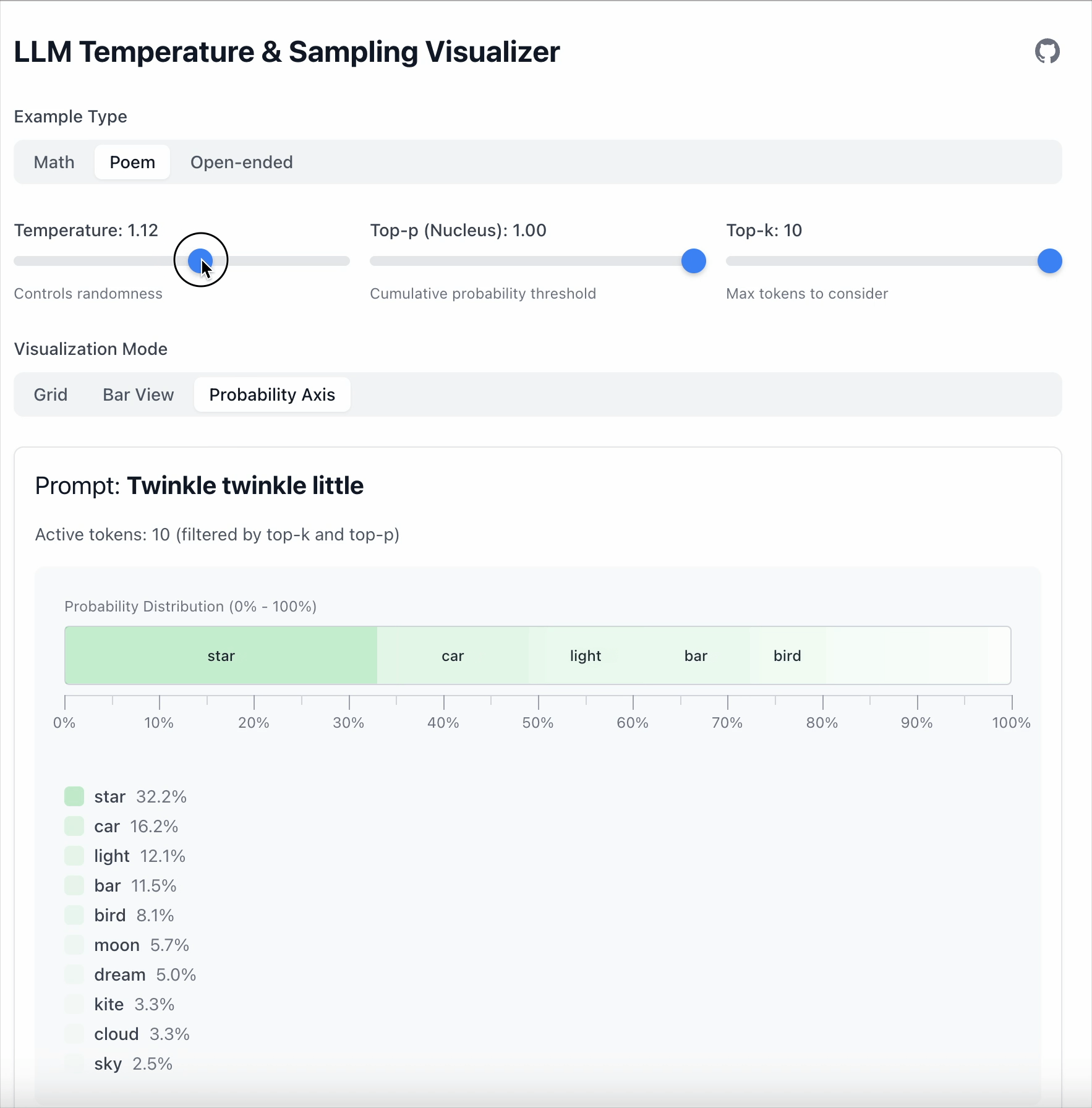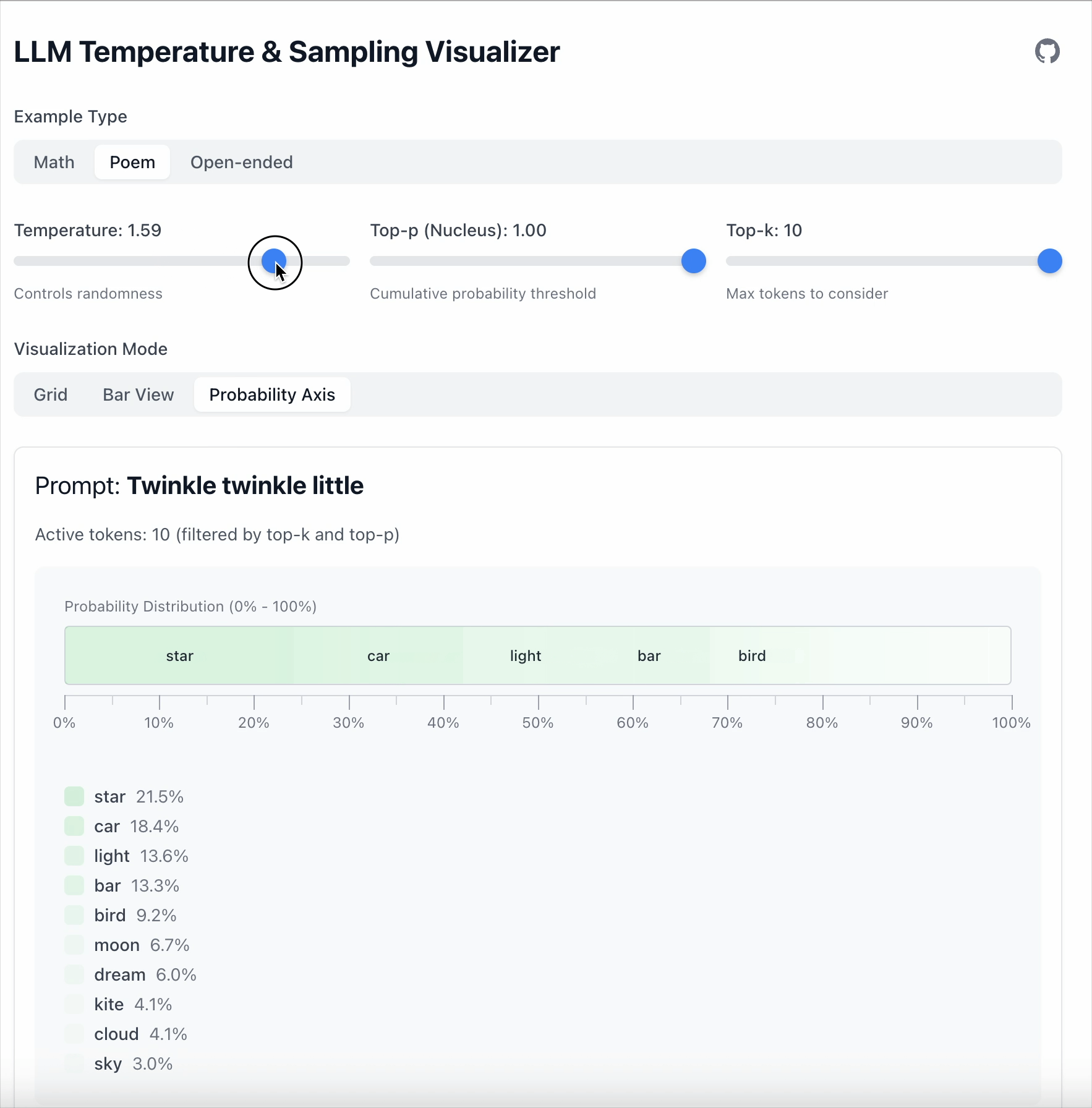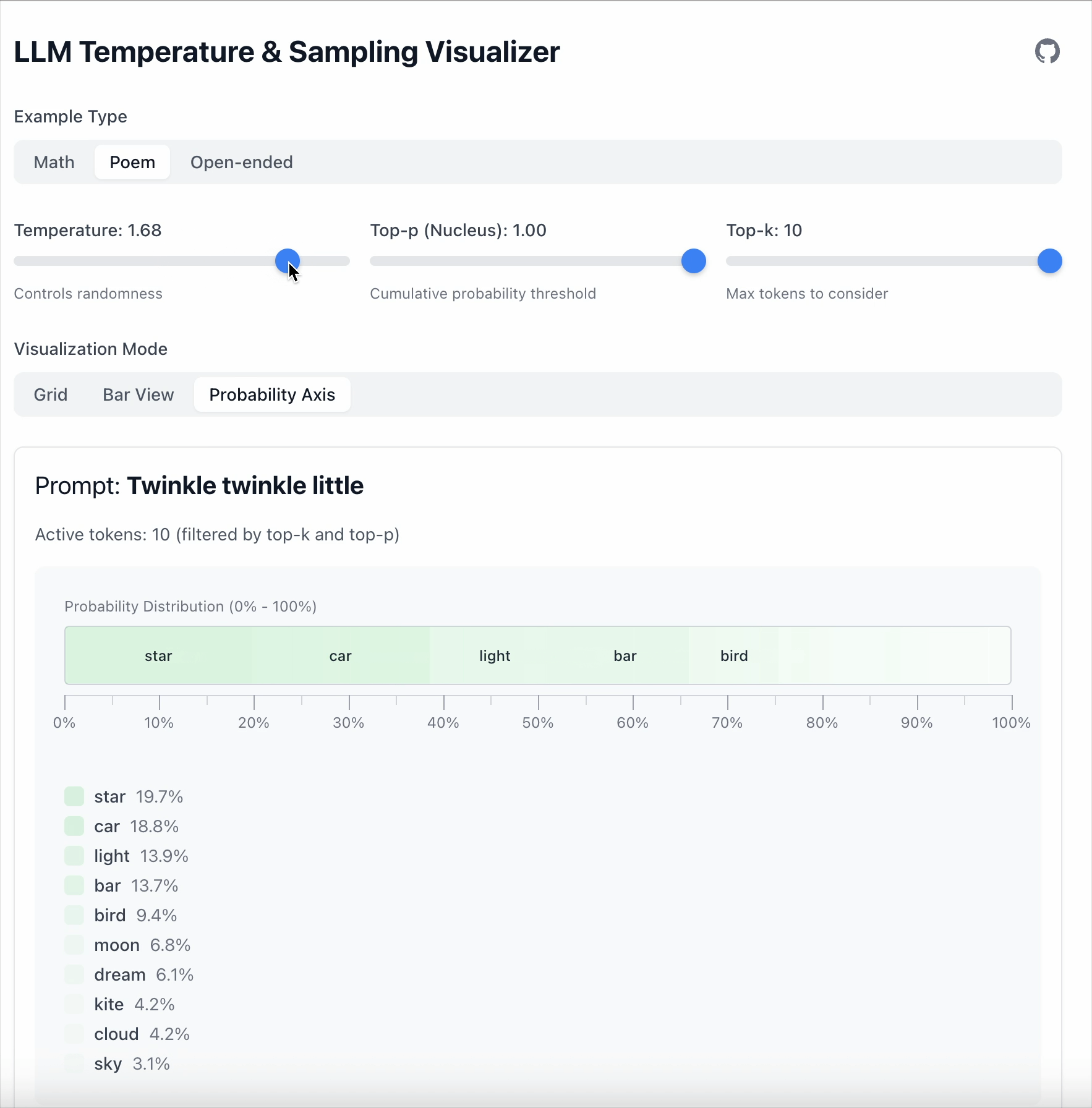
핵심 포인트: Temperature는 토큰을 제거하지 않으며, 단지 모델이 토큰을 얼마나 강하게 선호하는지만 바꿉니다.
Top‑p (Nucleus Sampling)
Top‑p는 얼마나 많은 확률 질량을 유지할지 제어합니다. 과정은 간단합니다:
- 가장 높은 확률의 토큰부터 시작한다.
- 누적 확률이 Top‑p 이상이 될 때까지 토큰을 계속 추가한다.
- 나머지는 버린다.
Top‑p = 0.6이면 전체 확률의 60 %를 차지하는 토큰들만 남게 됩니다.
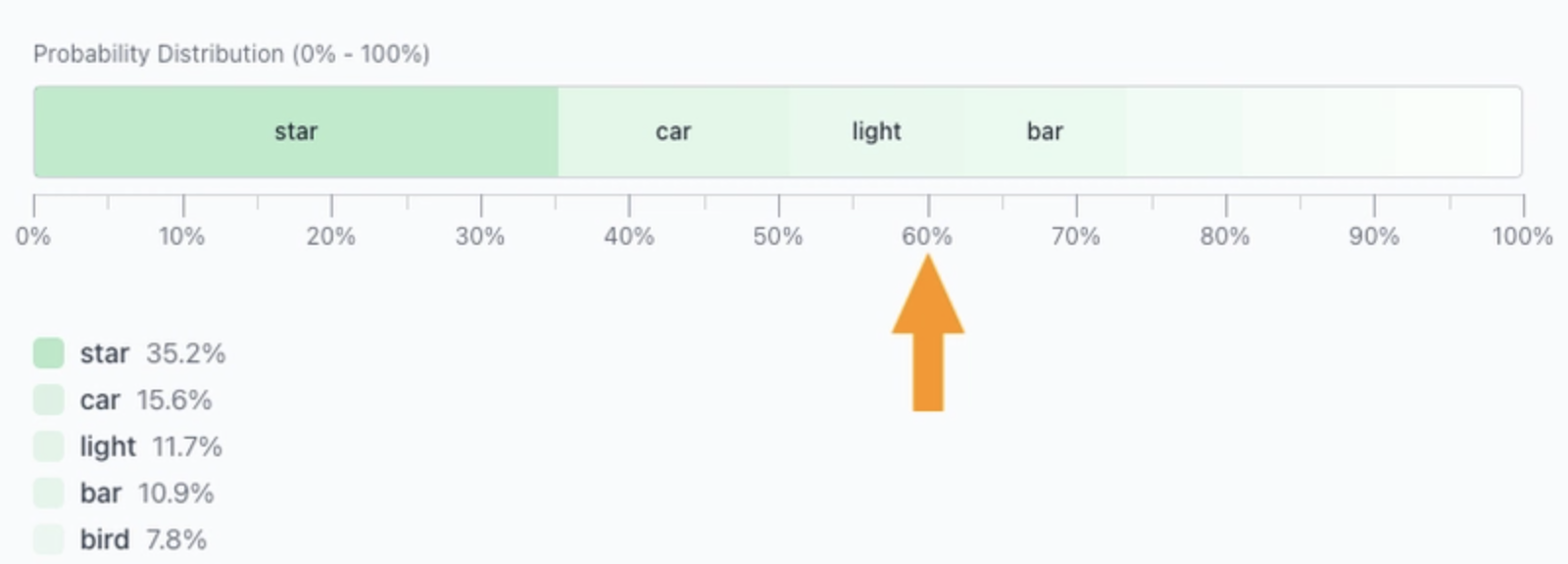
남은 토큰들은 다시 정규화됩니다:
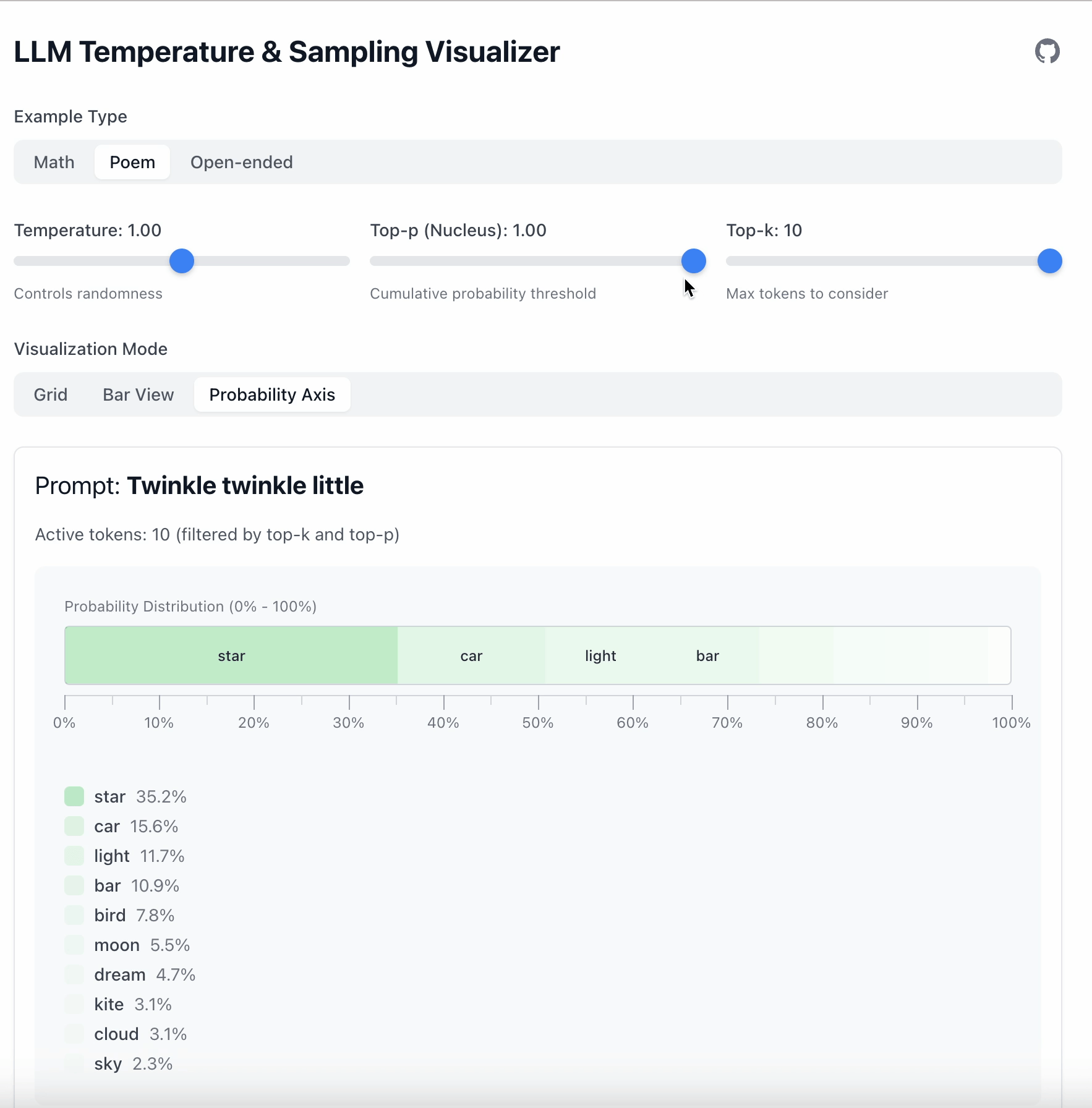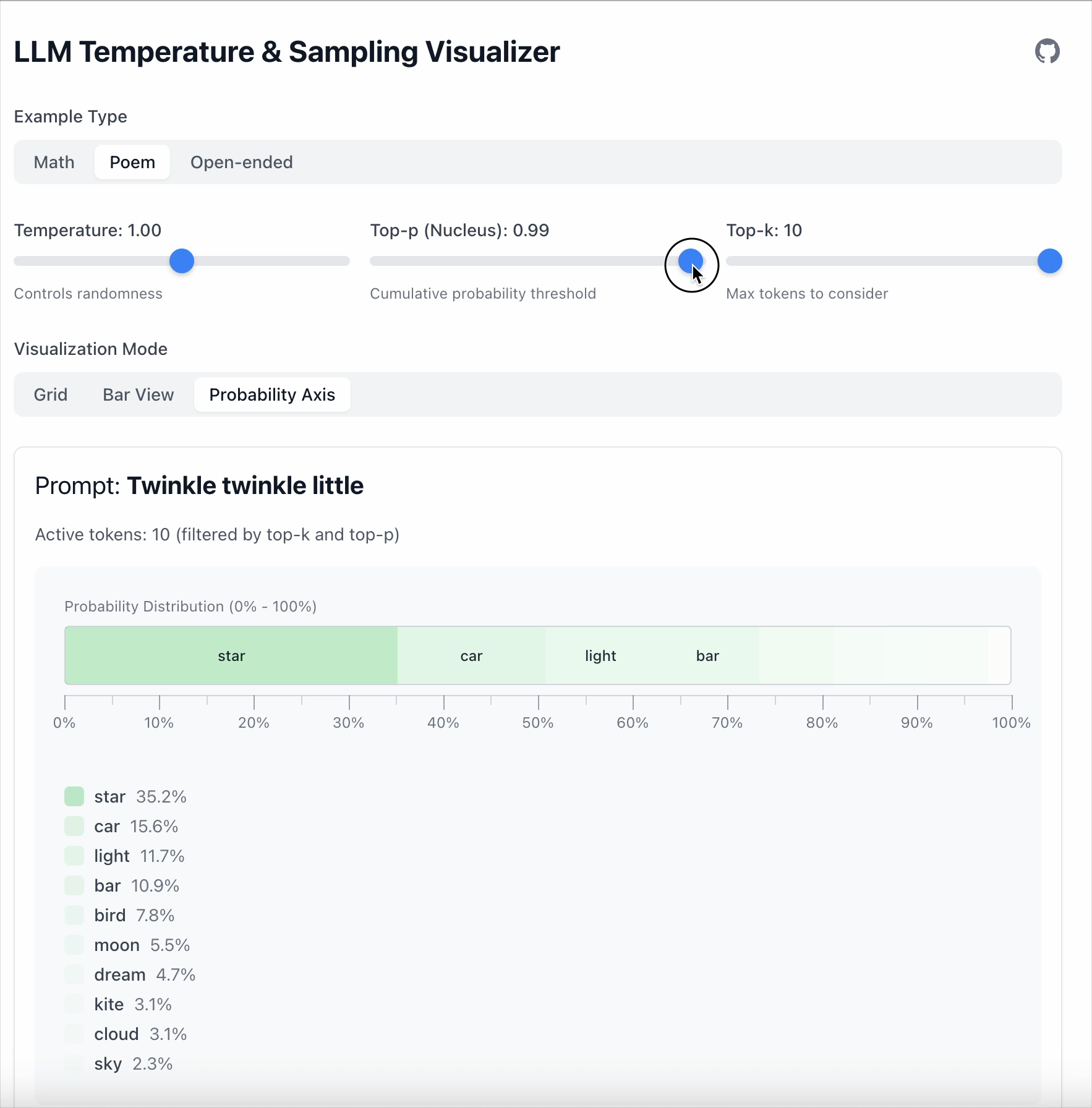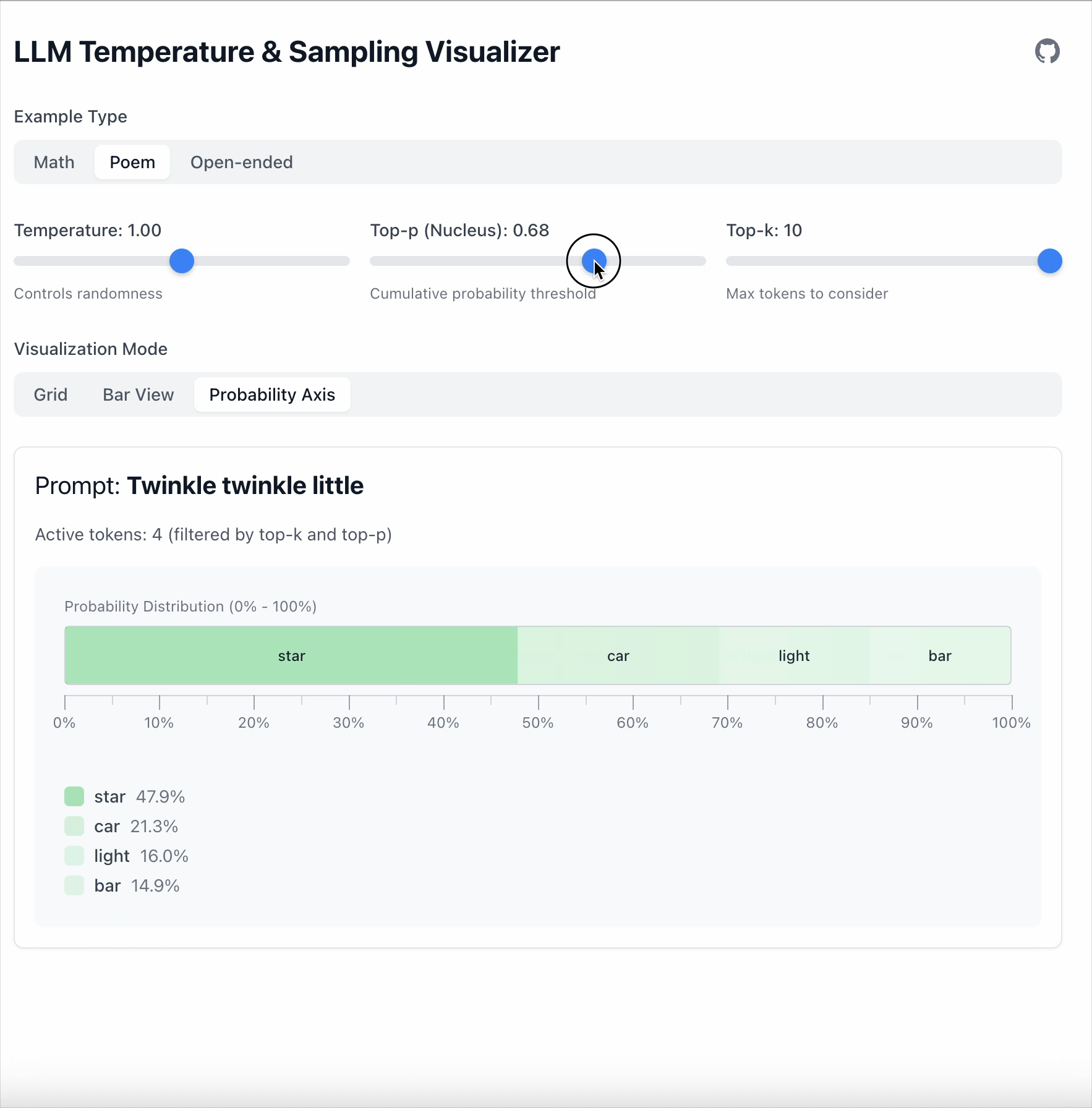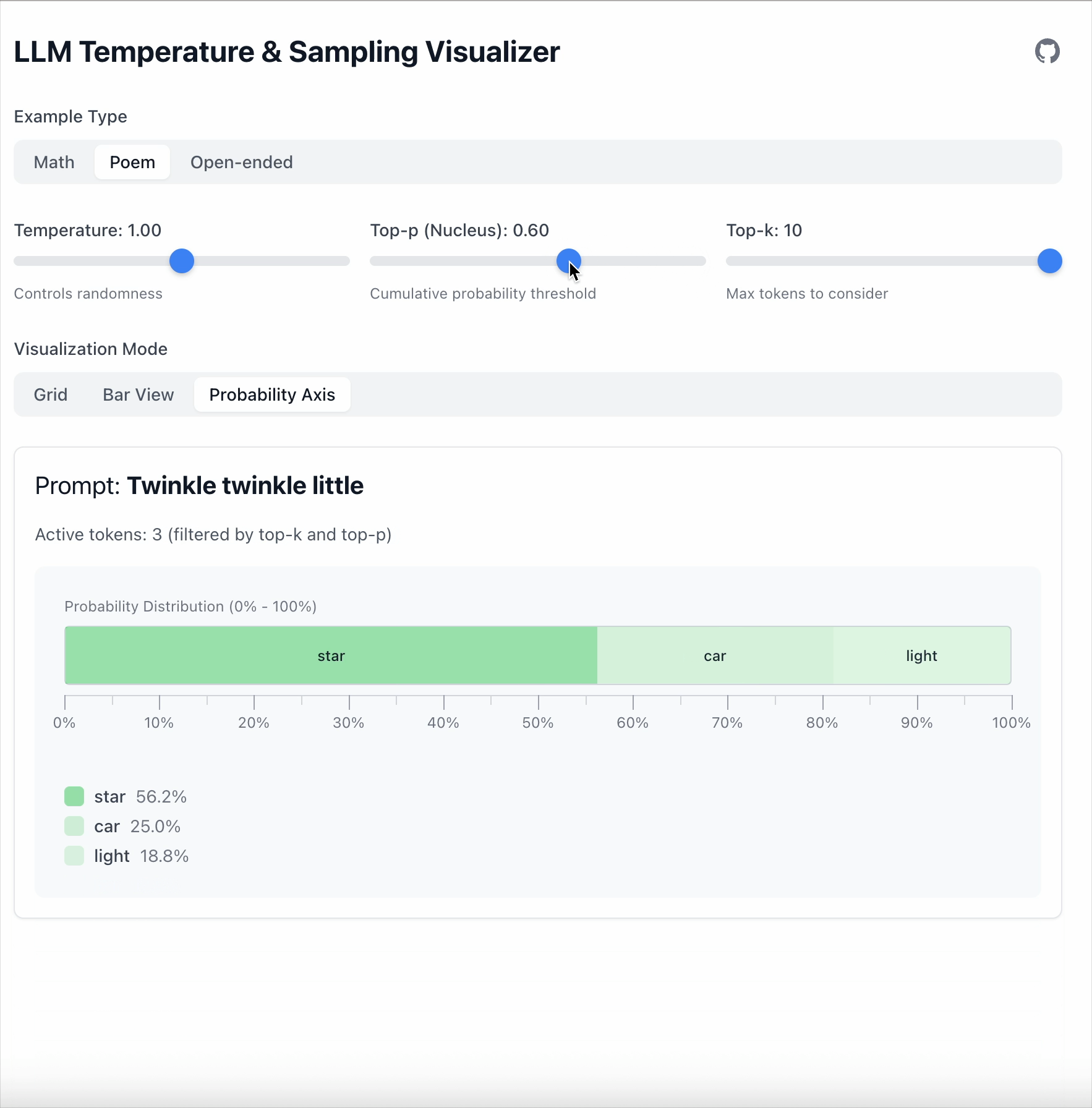
- 토큰 수는 동적으로 변합니다.
- 더 뾰족한 분포일수록 적은 토큰을 유지합니다.
Top‑k
Top‑k는 더 간단합니다: 상위 K개의 토큰만 유지한다.
- Top‑k = 1 → 항상 가장 가능성이 높은 토큰을 선택한다.
- Top‑k = 5 → 상위 5개 중에서 샘플링한다.
- 그 외의 토큰은 모두 무시한다.
한 줄로 정리하면:
- Top‑k는 토큰의 수량을 제한한다.
- Top‑p는 확률 질량을 제한한다.
데모
이 글에 사용된 모든 시각 자료는 LLM Sampling Visualizer에서 가져왔습니다:
👉
샘플링 파라미터가 추상적으로 느껴진다면, 이 도구를 5분만 사용해도 텍스트를 더 읽는 것보다 직관을 빠르게 얻을 수 있습니다.