CNCF에 llm-d를 환영합니다: Kubernetes를 SOTA AI 인프라로 진화시키다
Source: CNCF Blog
Posted on March 24, 2026
by Carlos Costa (IBM Research), Clayton Coleman (Google), and Rob Shaw (Red Hat)
우리는 llm‑d가 공식적으로 클라우드 네이티브 컴퓨팅 재단(CNCF) 샌드박스 프로젝트로 승인되었음을 알려드리게 되어 매우 기쁩니다!
생성 AI가 연구실에서 프로덕션 환경으로 전환함에 따라, 플랫폼 엔지니어링 팀은 새로운 인프라스트럭처 과제에 직면하고 있습니다. llm‑d는 쿠버네티스와 더 넓은 CNCF 생태계를 최첨단(State‑of‑the‑Art, SOTA) AI 인프라로 진화시키기 위해 CNCF에 합류했으며, 분산 추론을 일류 클라우드‑네이티브 워크로드로 다룹니다. CNCF에 참여함으로써 llm‑d는 리눅스 재단의 신뢰받는 관리와 개방형 거버넌스를 확보하고, 조직이 진정으로 중립적인 표준 위에 구축할 수 있는 자신감을 제공합니다.
2025년 5월에 Red Hat, Google Cloud, IBM Research, CoreWeave, NVIDIA가 협업하여 시작된 llm‑d는 **“모든 모델, 모든 가속기, 모든 클라우드”**라는 명확한 비전을 가지고 설립되었습니다. 이후 AMD, Cisco, Hugging Face, Intel, Lambda, Mistral AI와 같은 업계 리더와 캘리포니아 대학교 버클리 캠퍼스 및 시카고 대학교 등 대학 지원자들이 프로젝트에 합류했습니다.
“Mistral AI에서는 추론 최적화가 엔진만을 넘어 KV‑cache 관리와 분산 서빙과 같은 과제를 해결해야 하며, 이는 Mixture of Experts(MoE)와 같은 차세대 모델을 지원하기 위해 필수적이라고 믿습니다. 이러한 문제에 대한 개방형 협업은 유연하고 미래 지향적인 인프라를 구축하는 데 핵심입니다. 우리는 DisaggregatedSet 연산자를 **LeaderWorkerSet (LWS)**에 기여하는 등 llm‑d 생태계에 참여함으로써 AI 서빙을 위한 개방 표준을 발전시키는 데 지원하고 있습니다.”
— Mathis Felardos, Inference Software Engineer, Mistral AI
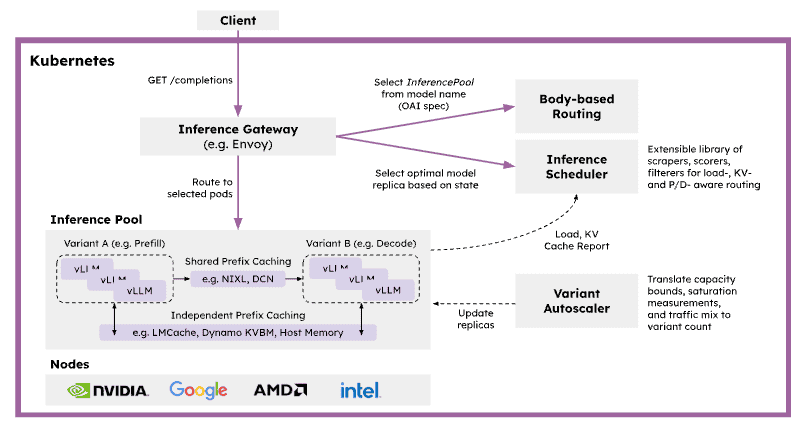
llm‑d가 CNCF 환경에 가져오는 것
CNCF는 복잡한 워크로드‑오케스트레이션 문제를 해결하기 위한 자연스러운 장소입니다. AI 서빙은 상태가 많이 유지되고 지연에 민감하며, 프롬프트 길이, 캐시 로컬리티, 모델 단계에 따라 요청 비용이 크게 달라집니다. 기존 서비스‑라우팅 및 자동 스케일링 메커니즘은 이러한 추론 상태를 인식하지 못해 비효율적인 배치, 캐시 단편화, 부하가 걸릴 때 예측할 수 없는 지연을 초래합니다. llm‑d는 고수준 제어 플레인(예: KServe)과 저수준 추론 엔진(예: vLLM) 사이의 격차를 메우는 사전 통합된 Kubernetes‑네이티브 분산 추론 프레임워크를 제공함으로써 이를 해결합니다. llm‑d는 CNCF AI Conformance 프로그램과 협력하여 분산 서빙과 같은 핵심 기능이 생태계 전반에서 상호 운용될 수 있도록 할 계획입니다.
오픈 API와 확장 가능한 게이트웨이 프리미티브를 기반으로 구축함으로써, llm‑d는 CNCF 생태계에 여러 중요한 기능을 도입합니다:
- Inference‑Aware Traffic Management – Kubernetes Gateway API Inference Extension (GAIE)의 주요 구현; 프로그래머블하고 프리픽스‑캐시‑인식 라우팅을 위해 Endpoint Picker (EPP)를 사용합니다.
- Native Kubernetes Orchestration – LeaderWorkerSet (LWS) 와 같은 프리미티브를 활용해 복잡한 다중‑노드 복제와 광범위한 전문가 병렬성을 오케스트레이션하고, 맞춤형 AI 인프라를 관리 가능한 클라우드‑네이티브 마이크로서비스로 전환합니다.
- Prefill/Decode Disaggregation – 프롬프트 처리와 토큰 생성 단계를 독립적으로 확장 가능한 파드로 분리하여 두 단계 간의 자원 활용 비대칭을 해결합니다.
- Advanced State Management – GPU, TPU, CPU, 스토리지 계층 전반에 걸친 계층형 KV‑캐시 오프로드를 도입합니다.
모든 가속기에서 SOTA 추론 성능
클라우드‑네이티브 철학의 핵심 원칙 중 하나는 벤더 락‑인 방지입니다. AI 인프라스트럭처에서는 서비스 제공 능력이 하드웨어에 구애받지 않아야 함을 의미합니다.
우리는 가속기‑중립적인 사고방식으로 SOTA 추론을 민주화하는 것이 LLM의 광범위한 채택을 위한 가장 중요한 촉진제라고 믿습니다. llm‑d의 주요 사명은 모든 가속기에서 SOTA 추론 성능을 달성하는 것입니다. 모델 및 상태를 인식하는 라우팅 정책을 도입해 요청 배치를 특정 하드웨어 특성에 맞추어 최적화함으로써, llm‑d는 활용도를 극대화하고 다음과 같은 핵심 추론 지표에서 측정 가능한 향상을 제공합니다:
- 첫 토큰까지의 시간 (TTFT)
- 출력 토큰당 시간 (TPOT)
- 토큰 처리량
- KV‑캐시 활용도
NVIDIA, AMD, Google 등 어느 가속기에서 워크로드를 실행하든, llm‑d는 고성능 AI 서빙이 여러분 스택의 핵심이자 조합 가능한 기능으로 유지되도록 보장합니다.
명확하고 재현 가능한 벤치마크는 이러한 최적화의 가치를 입증하는 데 필수적입니다. AI 산업은 종종 마케팅 주장이나 상업 분석가에 의존해 추론 성능을 측정하는 표준 방법이 부족합니다. llm‑d는 오픈 벤치마킹을 통해 추론 벤치마크를 정의하고 실행하는 중립적인 사실상의 표준이 되고자 합니다.
예를 들어 멀티‑테넌트 SaaS 사용 사례에서는 공유 고객 컨텍스트를 활용해 프리픽스 캐싱을 통해 상당한 계산 비용을 절감할 수 있습니다. 최신 v0.5 릴리스에서 보여지듯, llm‑d의 추론 스케줄링은 베이스라인 Kubernetes 서비스에 비해 거의 제로에 가까운 지연 시간과 막대한 처리량을 유지합니다:
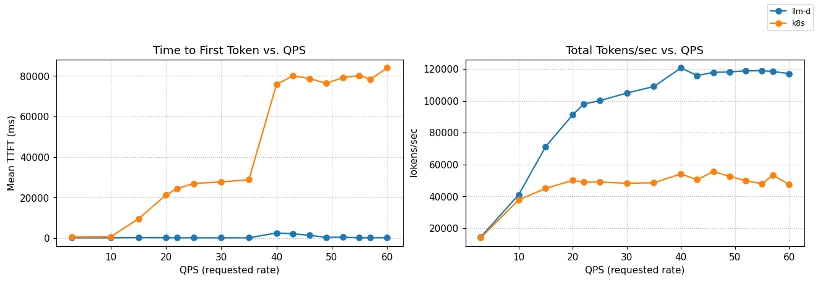
Figure 1: Qwen3‑32B (8 × vLLM pods, 16 × NVIDIA H100)에서 QPS에 따른 TTFT 및 처리량. llm‑d 추론 스케줄링은 거의 제로에 가까운 TTFT를 유지하면서 ~120 k tok/s까지 확장되며, 베이스라인 Kubernetes 서비스는 부하가 증가함에 따라 급격히 성능이 저하됩니다.
클라우드‑네이티브와 AI‑네이티브 생태계 연결
궁극적인 AI 인프라를 구축하려면 Kubernetes 오케스트레이션과 최첨단 AI 연구 사이의 격차를 메워야 합니다. llm‑d는 대형 파운데이션‑모델 구축업체와 AI‑네이티브 기업의 AI/ML 리더, 그리고 조직 전반에 AI를 빠르게 도입하고 있는 전통적인 기업들과 깊은 관계를 적극적으로 구축하고 있습니다. 또한 모델 개발 및 학습을 분산된 클라우드‑네이티브 서빙과 직접 연결하는 원활하고 엔드‑투‑엔드 오픈 생태계를 보장하기 위해 PyTorch Foundation과의 협업을 확대할 것을 약속합니다.
참여하기: “잘 밝혀진 경로”를 따르세요
핵심적으로, llm‑d는 “잘 밝혀진 경로” 철학을 따릅니다. 플랫폼 팀이 깨지기 쉬운 블랙박스를 조합하도록 내버려 두는 대신, llm‑d는 검증된, 프로덕션 준비가 된 배포 패턴을 제공합니다—현실적인 부하 하에서 엔드‑투‑엔드로 테스트된 벤치마크 레시피입니다.
우리는 개발자, 플랫폼 엔지니어, AI 연구자 여러분을 초대하여 오픈 AI 인프라의 미래를 함께 만들어 나가고자 합니다:
- Explore the Well‑Lit Paths: 오늘 바로 인프라에 SOTA 추론 스택을 배포하기 위해 llm‑d guides를 방문하세요.
- Learn More: 공식 웹사이트인 llm‑d.ai를 확인하세요.
- Contribute: Slack 커뮤니티에 참여하고 GitHub 저장소에 기여하세요 .
CNCF에 오신 것을 환영합니다, llm‑d! 함께 AI 인프라의 미래를 구축해 나가길 기대합니다.