보편적인 AI로 가는 길 (초당 17k 토큰)
I’m happy to translate the article for you, but I’ll need the full text you’d like translated. Could you please paste the content (excluding the source line you already provided) here? Once I have it, I’ll keep the source line unchanged and translate the rest into Korean while preserving all formatting and technical terms.
Source: …
개요
많은 사람들은 AI가 진정한 혁신이라고 믿습니다. 제한된 분야에서는 이미 인간의 성능을 능가하고 있습니다. 잘 활용한다면 인간의 창의성과 생산성을 전례 없이 증폭시킬 수 있습니다. 그러나 그 광범위한 채택은 두 가지 주요 장벽에 의해 방해받고 있습니다: 높은 지연 시간과 천문학적인 비용.
- 지연 시간 – 언어 모델과의 상호작용은 인간 인지 속도에 비해 크게 뒤처집니다. 코딩 도우미는 몇 분씩 고민할 수 있어 프로그래머의 흐름을 방해하고 인간‑AI 협업의 효율성을 제한합니다. 반면 자동화된 에이전시 AI 애플리케이션은 밀리초 수준의 지연 시간을 요구하며, 여유로운 인간 속도의 응답은 받아들일 수 없습니다.
- 비용 – 최신 모델을 배포하려면 방대한 엔지니어링과 자본이 필요합니다. 수백 킬로와트를 소비하는 방 크기의 슈퍼컴퓨터, 액체 냉각, 고급 패키징, 스택 메모리, 복잡한 I/O, 그리고 수많은 케이블이 요구됩니다. 이는 도시 규모의 데이터 센터 캠퍼스와 위성 네트워크로 확장되어 극심한 운영 비용을 초래합니다.
사회가 데이터 센터와 인접 전력 시설에 의해 정의되는 디스토피아적 미래를 향해 나아가고 있는 듯 보이지만, 역사는 다른 방향을 시사합니다. 과거의 기술 혁명은 종종 기괴한 프로토타입으로 시작했으며, 이후 보다 실용적인 결과를 낳는 돌파구에 의해 대체되었습니다.
예를 들어 ENIAC: 방을 가득 메운 진공관과 케이블의 거대한 괴물. ENIAC은 인류에게 컴퓨팅의 마법을 소개했지만, 느리고 비용이 많이 들며 확장성이 없었습니다. 트랜지스터는 워크스테이션과 PC, 스마트폰, 그리고 어디에나 존재하는 컴퓨팅으로 이어지는 빠른 진화를 촉발시켜 ENIAC의 거대함을 압도했습니다.
범용 컴퓨팅이 쉽게 만들 수 있고, 빠르고, 저렴해짐으로써 주류에 진입했습니다.
AI도 동일한 길을 걸어야 합니다.
Source: …
Taalas 소개
2.5년 전 설립된 Taalas는 어떤 AI 모델이든 맞춤형 실리콘으로 변환하는 플랫폼을 개발했습니다. 이전에 본 적 없는 모델이 들어오는 순간부터 단 2개월 만에 하드웨어로 구현할 수 있습니다.
그 결과물인 Hardcore Models는 소프트웨어 기반 구현에 비해 속도, 비용, 전력 효율 면에서 한 차례 더 빠르고 저렴하며 전력 소모가 적습니다.
Taalas의 작업은 다음과 같은 핵심 원칙에 의해 이끌어집니다:
1. 완전 특화
컴퓨팅 역사를 통틀어 깊은 특화는 중요한 워크로드에서 극한 효율을 달성하는 가장 확실한 길이었습니다. AI 추론은 인류가 직면한 가장 중요한 계산 워크로드이며, 특화로부터 가장 큰 이익을 얻을 수 있는 분야입니다. 그 계산 요구량은 완전 특화를 촉구합니다: 각 개별 모델에 최적화된 실리콘을 생산하는 것입니다.
2. 저장소와 연산의 결합
현대 추론 하드웨어는 인위적인 경계에 의해 제한됩니다: 한쪽은 메모리, 다른 한쪽은 연산, 서로 근본적으로 다른 속도로 동작합니다.
- 역설 – DRAM은 표준 칩 공정과 호환되는 메모리 유형보다 훨씬 밀도가 높고(따라서 비용이 저렴함) 하지만, 칩 외부 DRAM에 접근하는 속도는 칩 내부 메모리보다 수천 배 느립니다. 반대로, 연산 칩은 DRAM 공정을 사용해 만들 수 없습니다.
이 경계는 현대 추론 하드웨어의 복잡성을 크게 만들며, 고급 패키징, HBM 스택, 방대한 I/O 대역폭, 칩당 전력 소비 급증, 액체 냉각 등의 필요성을 초래합니다.
Taalas는 이 경계를 없앱니다. 저장소와 연산을 DRAM 수준의 밀도로 단일 칩에 통합함으로써, 우리의 아키텍처는 이전에 가능했던 한계를 훨씬 뛰어넘습니다.
3. 급진적 단순화
메모리‑연산 경계를 제거하고 각 모델에 맞게 실리콘을 맞춤화함으로써, 우리는 전체 하드웨어 스택을 근본 원리부터 재설계할 수 있었습니다. 그 결과는 HBM, 고급 패키징, 3‑D 스태킹, 액체 냉각, 고속 I/O와 같은 어려운 혹은 이색적인 기술에 의존하지 않는 시스템입니다.
공학적 단순성은 전체 시스템 비용을 한 차례 수준으로 감소시킵니다.
초기 제품
이 기술 철학에 따라, Taalas는 세계에서 가장 빠르고 비용·전력 효율이 가장 높은 추론 플랫폼을 만들었습니다.

Figure 1: Llama 3.1 8B가 하드와이어드된 Taalas HC1.
오늘 우리는 첫 번째 제품을 공개합니다: 하드와이어드된 Llama 3.1 8B 모델이며, 채팅봇 데모와 추론 API 서비스 두 형태로 제공됩니다.
- 성능 – Taalas의 실리콘 Llama는 사용자당 초당 17 K 토큰을 달성하며, 현재 최첨단 대비 거의 10배 빠릅니다.
- 비용 – 구축 비용이 20배 적게 듭니다.
- 전력 – 전력 소비가 10배 적습니다.
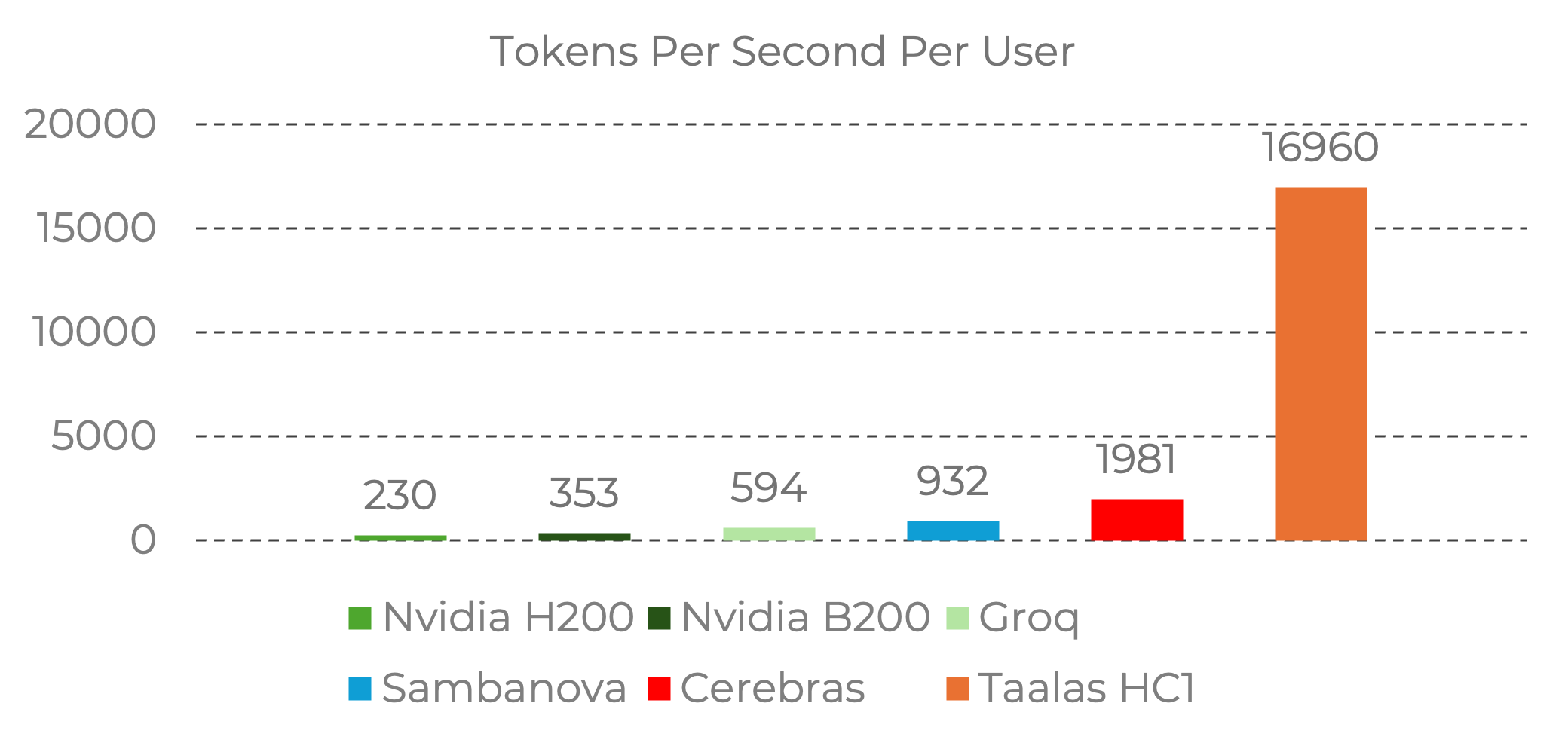
Figure 2: Llama 3.1 8B에서 Taalas HC1이 사용자당 초당 토큰 수에서 선도적인 성능을 보여줍니다.
Llama 3.1 8B에 대한 성능 데이터, 입력 시퀀스 길이 1 k/1 k.
출처: Nvidia Baseline (H200) – Taalas 측정; Groq, Sambanova, Cerebras – Artificial Analysis에서 인용; Taalas Performance – Taalas 연구소 실행.
우리는 실용성을 이유로 첫 번째 제품의 기반으로 Llama 3.1 8B를 선택했습니다. 작은 크기와 오픈소스 공개 덕분에 최소한의 물류 노력으로 모델을 하드엔드화할 수 있었습니다.
속도를 위해 대부분 하드와이어드되어 있지만, Llama는 다음을 통해 유연성을 유지합니다:
- 설정 가능한 컨텍스트 윈도우 크기.
- 저랭크 어댑터(LoRA)를 통한 파인튜닝 지원.
첫 번째 세대 설계 작업을 시작했을 때는 저정밀 파라미터 포맷이 아직 표준화되지 않았습니다. 따라서 초기 실리콘 플랫폼은 맞춤형 3비트 기본 데이터 타입을 사용했습니다. 실리콘 Llama는 3비트와 6비트 파라미터를 결합한 공격적인 양자화를 적용했으며, 이는 GPU 벤치마크에 비해 약간의 품질 저하를 초래합니다.
우리의 두 번째 세대 실리콘은 표준 4비트 부동소수점 포맷을 채택하여 이러한 제한을 해소하면서도 높은 속도와 효율성을 유지합니다.
Source: …
향후 모델
우리의 두 번째 모델은 여전히 Taalas의 1세대 아키텍처를 기반으로 하며, 더 큰 오픈소스 모델(예: Llama 3.1 70B)을 목표로 하고 새로운 4‑bit 부동소수점 포맷을 도입합니다. 이 차세대 하드웨어는 다음을 더욱 개선할 예정입니다:
- 처리량 – 사용자당 초당 30 K 토큰 이상을 목표로 합니다.
- 에너지 효율 – 토큰당 0.5 W 이하를 목표로 합니다.
- 확장성 – 다중 모델 워크로드를 지원하도록 타일링 가능한 모듈식 설계.
연말에 있을 발표를 기대해 주세요.
자세한 내용은 taalas.com 을 방문하거나 info@taalas.com 으로 문의하십시오.
t‑generation 실리콘 플랫폼 (HC1) 은 중간 규모의 추론 LLM이 될 예정이며, 이번 봄에 우리 연구실에서 기대되고 곧 추론 서비스에 통합될 것입니다.
이후, 2세대 실리콘 플랫폼 (HC2) 을 사용해 최첨단 LLM을 제작할 계획입니다. HC2는 훨씬 높은 집적도와 더 빠른 실행 속도를 제공합니다. 배포는 겨울에 예정되어 있습니다.
오늘 바로 손 안에 있는 즉각적인 AI
우리 첫 모델은 분명 선두에 있지는 않지만, 베타 서비스로 출시하기로 했습니다 – 개발자들이 LLM 추론이 서브밀리초 속도와 거의 비용이 들지 않을 때 어떤 것이 가능해지는지 탐험하도록 하기 위해서입니다.
우리는 우리의 서비스가 이전에는 실현하기 어려웠던 다양한 종류의 애플리케이션을 가능하게 한다고 믿으며, 개발자들이 실험하고 이러한 기능을 어떻게 적용할 수 있는지 발견하도록 장려하고 싶습니다.
접근 권한을 **여기**에서 신청하고, 전통적인 AI 지연 시간 및 비용 제약을 없애는 시스템을 경험해 보세요.
실질, 팀 및 장인정신
그 핵심에서, Taalas는 오랜 기간 협업해 온 소규모 그룹으로, 그 중 다수는 20년 이상 함께 일해 왔습니다. 슬림하고 집중된 운영을 위해, 우리는 동등한 역량과 수십 년에 걸친 공동 경험을 가진 외부 파트너에 의존합니다.
팀은 새로운 구성원이 탁월함을 입증하고, 우리의 사명에 부합하며, 기존 관행을 존중할 때 천천히 성장합니다. 여기서는 실질이 화려함을 능가하고, 장인정신이 규모를 능가하며, 엄격함이 중복을 능가합니다.
Taalas는 깊은 기술 스타트업이 중세 군대가 성을 포위하듯 선택한 문제에 접근하는 세상에서 정밀 타격을 가합니다—숫자는 무수히 많고, 벤처 자본은 넘쳐나며, 명확한 사고를 가리는 과대광고가 울려 퍼집니다.
우리의 첫 제품은 24명의 팀이 시장에 내놓았으며, $30 M의 총 지출로 $200 M 이상 모금된 자금 중 일부만 사용했습니다. 이 성과는 정확히 정의된 목표와 규율 있는 집중이 무분별한 힘보다 더 큰 성과를 낼 수 있음을 보여줍니다.
앞으로 우리는 개방형으로 나아갈 것입니다. 우리의 Llama 추론 플랫폼은 이미 여러분 손에 있습니다. 향후 시스템도 성숙해지는 대로 차례로 공개될 것입니다. 우리는 이를 조기에 공개하고, 신속히 반복하며, 거친 부분을 받아들일 것입니다.
결론
혁신은 가정에 의문을 제기하고 어떤 솔루션 공간의 소외된 구석으로 나아가는 것에서 시작됩니다. 그것이 바로 우리가 Taalas에서 선택한 길입니다.
우리 기술은 성능, 전력 효율성 및 비용에서 단계적 향상을 제공합니다. 이는 주류와 근본적으로 다른 아키텍처 철학을 반영하며, AI 시스템이 구축되고 배포되는 방식을 재정의합니다.
파괴적인 혁신은 처음에는 익숙하게 보이지 않는 경우가 많으며, 우리는 업계가 이 새로운 운영 패러다임을 이해하고 채택하도록 돕는 데 전념하고 있습니다.
우리의 첫 번째 제품은 하드와이어드 Llama에서 시작해 보다 강력한 모델로 빠르게 확장되며, 높은 지연 시간과 비용이라는 보편적인 AI의 핵심 장벽을 제거합니다.
우리는 즉각적이고 초저비용의 인텔리전스를 개발자들의 손에 제공했으며, 그들이 이를 통해 무엇을 만들어낼지 기대하고 있습니다.