모든 재실행 중단: DuckDB의 로컬 인크리멘탈 파이프라인
I’m happy to translate the article for you, but I’ll need the full text you’d like translated. Could you please paste the content (or the portion you want translated) here? I’ll keep the source line exactly as you provided and preserve all formatting, markdown, and code blocks.
Incremental Models + Cached DAG Runs (DuckDB‑only)
I love local‑first data work… until I catch myself doing the same thing for the 12ᵗʰ time:
“I changed one model. Better rerun the whole pipeline.”
이 포스트는 incremental models와 cached DAG runs를 활용해 그 습관을 고치는 작은 프로젝트를 가볍게 walkthrough 하는 내용입니다 — 모두 DuckDB만으로 노트북에서 실행됩니다. 예시는 기존 incremental_demo 프로젝트의 DuckDB‑only 버전으로 단순화했습니다.
우리는 세 번 실행합니다:
- seed v1 → 초기 빌드
- 변경 없이 다시 실행 → 대부분 건너뛰기
- seed v2 (업데이트 + 새 행) → incremental merge/upsert
그게 전부입니다. 클라우드도, 복잡한 절차도 없습니다.
한 문장으로 요약한 전체 데모
작은 raw.events 테이블을 CSV에서 시드하고, 스테이징 모델을 만든 뒤, updated_at을 기준으로 “새로운” 행만 처리하는 incremental fact 테이블을 구축하고, event_id를 기준으로 업데이트를 적용합니다.
미니 프로젝트 구성 요소
핵심은 세 가지입니다:
-
두 개의 시드 스냅샷
- v1 – 3개의 행.
- v2 –
event_id = 2가 (새로운updated_at, 다른value) 로 변경되고event_id = 4가 추가됩니다.
-
소스 매핑 – 프로젝트는
seed_events라는 시드 테이블을 가리키는raw.events소스를 정의합니다. -
몇 개의 모델 (SQL + Python)
| Model | Type | Description |
|---|---|---|
events_base | Staging (SQL) | 타임스탬프를 캐스팅하고 컬럼을 정리합니다 |
fct_events_sql_inline | Incremental SQL (inline) | 모델 파일에 정의된 incremental 로직 |
fct_events_sql_yaml | Incremental SQL (YAML) | project.yml에 있는 incremental 설정 |
fct_events_py_incremental | Incremental Python (DuckDB) | pandas에서 value_x10을 추가하고 delta 프레임을 반환합니다 |
위 모든 내용은 내보낸 데모에 포함되어 있습니다.
DuckDB‑only 설정
데모의 DuckDB 프로필은 간단합니다: 로컬 DuckDB 파일에 기록합니다.
profiles.yml (DuckDB 프로필)
dev_duckdb:
engine: duckdb
duckdb:
path: "{{ env('FF_DUCKDB_PATH', '.local/incremental_demo.duckdb') }}".env.dev_duckdb (선택적 편의 설정)
FF_DUCKDB_PATH=.local/incremental_demo.duckdb
FF_DUCKDB_SCHEMA=inc_demo_schema모델들 (재미있는 부분)
Staging: events_base
{{ config(materialized='table') }}
select
event_id,
cast(updated_at as timestamp) as updated_at,
value
from {{ source('raw', 'events') }};Incremental SQL (inline config): fct_events_sql_inline
{{ config(
materialized='incremental',
unique_key='event_id',
incremental={ 'updated_at_column': 'updated_at' },
) }}
with base as (
select *
from {{ ref('events_base.ff') }}
)
select
event_id,
updated_at,
value
from base
{% if is_incremental() %}
where updated_at > (
select coalesce(max(updated_at), timestamp '1970-01-01 00:00:00')
from {{ this }}
)
{% endif %};동작 방식
materialized='incremental'unique_key='event_id'- 워터마크 컬럼:
updated_at
증분 실행 시 대상 테이블에 이미 존재하는 최대 updated_at보다 최신인 행만 선택합니다. 이는 updated_at이 행이 변경될 때마다 증가한다는 가정에 기반합니다(데모용; 실제 파이프라인에서는 지연 도착 처리 등이 필요할 수 있습니다).
Incremental SQL (YAML‑config 스타일): fct_events_sql_yaml
{{ config(materialized='incremental') }}
with base as (
select *
from {{ ref('events_base.ff') }}
)
select
event_id,
updated_at,
value
from base;project.yml에 있는 증분 설정
models:
incremental:
fct_events_sql_yaml.ff:
unique_key: "event_id"
incremental:
enabled: true
updated_at_column: "updated_at"원하는 스타일을 골라 사용하세요.
Incremental Python (DuckDB): fct_events_py_incremental
from fastflowtransform import engine_model
import pandas as pd
@engine_model(
only="duckdb",
name="fct_events_py_incremental",
deps=["events_base.ff"],
)
def build(events_df: pd.DataFrame) -> pd.DataFrame:
df = events_df.copy()
df["value_x10"] = df["value"] * 10
return df[["event_id", "updated_at", "value", "value_x10"]]이 모델의 증분 동작(merge/upsert)은 project.yml에서 설정됩니다.
Source:
세 번 실행하는 워크스루
데모의 정확한 “스토리 아크”를 따라갑니다: 첫 번째 빌드, 변경 없음 빌드, 그리고 시드 변경으로 인한 증분 업데이트.
단계 0: 로컬 시드 폴더 선택
Makefile은 로컬 시드 디렉터리를 사용하며 seed_events.csv를 v1과 v2 사이에 교체합니다.
mkdir -p .local/seeds“증분”임을 증명하는 작은 데이터셋
같은 시드 파일의 두 버전이 제공됩니다. v2는 기존 행 하나를 업데이트하고 새 행 하나를 추가합니다 — 따라서 증분 모델이 **업서트(upsert)**와 **인서트(insert)**를 모두 수행하는 모습을 확인할 수 있습니다.
seeds/seed_events_v1.csv
event_id,updated_at,value
1,2024-01-01 00:00:00,10
2,2024-01-02 00:00:00,20
3,2024-01-03 00:00:00,30seeds/seed_events_v2.csv
event_id,updated_at,value
1,2024-01-01 00:00:00,10
2,2024-01-05 00:00:00,999
3,2024-01-03 00:00:00,30
4,2024-01-06 00:00:00,40v1 → v2 로 전환하고 다시 실행하면 다음과 같은 결과가 나와야 합니다:
event_id = 2가 업데이트됨 (새로운updated_at,value = 999)event_id = 4가 삽입됨 (완전 새로운 행)
1️⃣ 첫 번째 실행 (seed v1 → 초기 빌드)
v1을 제자리로 복사합니다:
cp seeds/seed_events_v1.csv .local/seeds/seed_events.csv시드 + 실행:
FFT_SEEDS_DIR=.local/seeds fft seed . --env dev_duckdb
FFT_SEEDS_DIR=.local/seeds fft run . --env dev_duckdb첫 번째 실행이므로 모든 모델이 처음으로 물질화(materialized)되는 것을 확인할 수 있습니다.
2️⃣ 두 번째 실행 (시드 변경 없음 → No‑op)
같은 명령을 다시 실행합니다:
FFT_SEEDS_DIR=.local/seeds fft run . --env dev_duckdb아무 것도 변경되지 않았으므로 모든 모델이 건너뛰기(캐시)됩니다.
3️⃣ 세 번째 실행 (seed v2 → 증분 병합/업서트)
업데이트된 시드를 교체합니다:
cp seeds/seed_events_v2.csv .local/seeds/seed_events.csv다시 시드하고 실행합니다:
FFT_SEEDS_DIR=.local/seeds fft seed . --env dev_duckdb
FFT_SEEDS_DIR=.local/seeds fft run . --env dev_duckdb다음과 같은 결과를 보게 됩니다:
fct_events_sql_inline와fct_events_sql_yaml은 이미 존재하는updated_at최대값보다 큰updated_at을 가진 행만 처리합니다.- 파이썬 모델(
fct_events_py_incremental) 은 델타 행만 받아value_x10을 곱한 뒤 다시 병합합니다.
최종 테이블을 확인합니다:
select * from inc_demo_schema.fct_events_sql_inline;결과:
| event_id | updated_at | value |
|---|---|---|
| 1 | 2024‑01‑01 00:00:00 | 10 |
| 2 | 2024‑01‑05 00:00:00 | 999 |
| 3 | 2024‑01‑03 00:00:00 | 30 |
| 4 | 2024‑01‑06 00:00:00 | 40 |
…그리고 파이썬 모델에는 곱해진 값이 들어 있는 추가 컬럼 value_x10 이 포함됩니다.
요약
- Incremental models는 새로운/변경된 행만 처리할 수 있게 합니다.
- Cached DAG runs (FastFlowTransform을 통해) 변경 사항이 없을 때 작업을 건너뜁니다.
- 이 모든 것은 DuckDB를 사용해 로컬에서 실행됩니다—클라우드도, 추가적인 절차도 필요 없습니다.
시도해 보고, 워터마크 로직을 조정하거나 늦게 도착하는 데이터 처리 방식을 실험해 보세요. 즐거운 점진적 모델링 되세요!
캐시 옵션(v_duckdb)으로 실행하기
fft run . --env dev_duckdb --cache=rw기대되는 결과
events_base가 일반 테이블이 됩니다.- 증분 모델은 처음으로 대상 테이블을 생성합니다(실제로는 첫 실행 시 전체 빌드와 동일).
No‑op 실행 (seed v1과 동일; 대부분 건너뛰어야 함)
fft run . --env dev_duckdb --cache=rw데모에서는 이를 **“no‑op run… 대부분 건너뛰어야 함”**이라고 부르며, 로컬 데이터 개발에서 가장 좋은 느낌을 줍니다.
시드 변경(v2 스냅샷) 후 증분 실행
# 시드 파일 교체
cp seeds/seed_events_v2.csv .local/seeds/seed_events.csv
# 새로운 시드 로드
FFT_SEEDS_DIR=.local/seeds fft seed . --env dev_duckdb
# 증분 모델 실행
fft run . --env dev_duckdb --cache=rw결과
event_id = 2가 새로운updated_at과value = 999와 함께 들어옵니다.event_id = 4가 처음 등장합니다.
증분 팩트는 unique_key = event_id를 기준으로 event_id = 2 행을 업데이트하고 event_id = 4를 삽입해야 합니다.
DuckDB에서 정상 여부 확인
증분 SQL 테이블 조회
duckdb .local/incremental_demo.duckdb \
"SELECT * FROM inc_demo_schema.fct_events_sql_inline ORDER BY event_id;"v2 이후에는 다음과 같이 보여야 합니다:
event_id = 2에updated_at = 2024-01-05와value = 999가 표시됩니다.event_id = 4에updated_at = 2024-01-06와value = 40인 새로운 행이 추가됩니다.
Python 테이블 조회
duckdb .local/incremental_demo.duckdb \
"SELECT * FROM inc_demo_schema.fct_events_py_incremental ORDER BY event_id;"업데이트된 행에 대해 파생 컬럼 value_x10(예: 9990)도 확인할 수 있어야 합니다.
DAG를 화면에 표시하기
fft docs serve --env dev_duckdb --open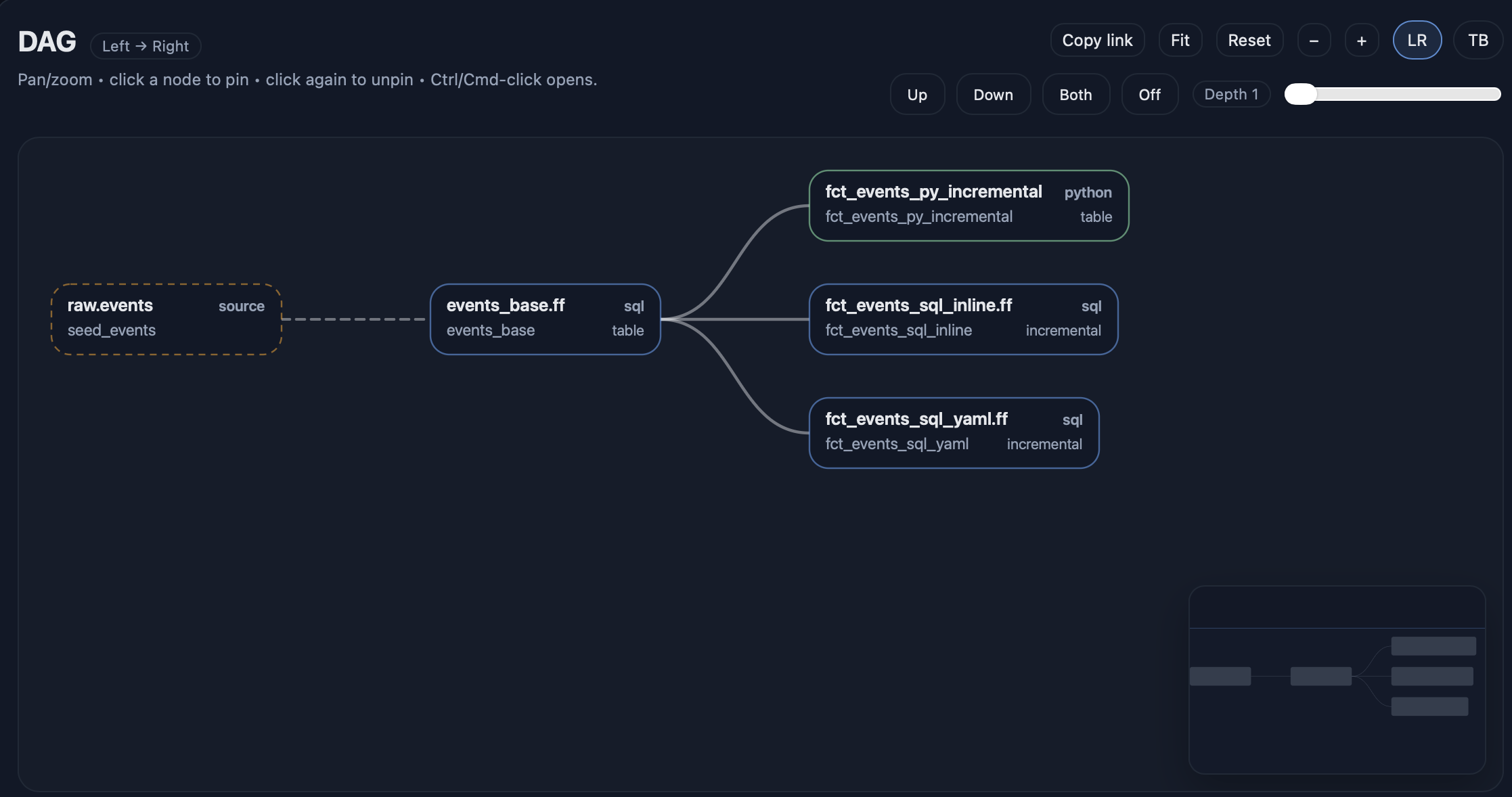
선택적 작은 “품질 검사”
fft test . --env dev_duckdb --select tag:incremental방금 구매한 것
이 설정으로 로컬 개발 루프는 다음과 같이 됩니다:
- 한 번 실행 – 모든 것을 빌드합니다.
- 다시 실행 – 대부분의 작업을 건너뛰고 (no‑op).
- 입력 데이터를 변경 – 필요한 부분만 업데이트합니다.
- 기존 행을 안전하게 업데이트 (via
unique_key) 대신 “추가하고 기도하기”.
이 모든 것이 단일 로컬 DuckDB 파일로 작동하여 실험을 저렴하고 빠르게 만들습니다.