Power BI에서 스키마 및 데이터 모델링
Source: Dev.to
데이터 모델링은 테이블을 구조화하고 관계를 정의하는 과정으로, Power BI가 다음을 수행할 수 있게 합니다:
- 데이터를 올바르게 집계
- 데이터를 효율적으로 필터링
- 정확한 측정값을 생성
- 대용량 데이터셋에서도 빠르게 수행
시각화 요소를 추가하기 전에 보고서의 청사진을 설계하는 것이라고 생각하면 됩니다.
스타 스키마 개요
Star schema는 관계형 데이터 웨어하우스에서 널리 채택되는 성숙한 모델링 접근 방식입니다.
모델러는 모델 테이블을 차원 또는 사실 중 하나로 분류해야 합니다.
차원 테이블
차원 테이블은 비즈니스 엔터티, 즉 모델링하는 대상들을 설명합니다.
엔터티에는 제품, 사람, 장소, 개념, 그리고 시간 자체까지 포함될 수 있습니다.
- 차원 테이블은 고유 식별자 역할을 하는 키 컬럼(또는 컬럼들)과 필터링 및 그룹화를 지원하는 추가 컬럼을 포함합니다.
- 스타 스키마에서 가장 일관된 테이블은 날짜 차원 테이블입니다.
사실 테이블
사실 테이블은 관찰값이나 이벤트(예: 판매 주문, 재고 잔액, 환율, 온도)를 저장합니다.
- 사실 테이블은 차원 테이블과 연결되는 차원 키 컬럼과 수치 측정 컬럼을 포함합니다.
- 차원 키 컬럼은 사실 테이블의 차원성을 결정하고, 키 값은 그 **세분화 수준(Granularity)**을 결정합니다.
예시 – 판매 목표를 저장하는 사실 테이블에는 두 개의 차원 키 컬럼이 있습니다:
Date와ProductKey.
- 이 테이블은 두 개의 차원(날짜와 제품)을 가집니다.
Date컬럼이 각 달의 첫 번째 날을 저장한다면, 세분화 수준은 월‑제품 수준이 됩니다.
일반적으로 차원 테이블은 상대적으로 적은 수의 행을 포함하는 반면, 사실 테이블은 많은 행을 포함할 수 있으며 시간이 지남에 따라 계속 증가합니다.

Fig. 1.1 – 스타 스키마 레이아웃
Source:
정규화 vs. 비정규화
스타 스키마 개념을 이해하려면 다음 두 용어를 알아야 합니다:
정규화 (Normalization) – 데이터 중복을 줄이기 위해 데이터를 저장하는 방식.
예시: 고유한ProductKey와 설명 컬럼(이름, 카테고리, 색상, 사이즈)을 가진 제품 테이블. 판매 테이블이ProductKey만 저장하는 경우가 정규화된 형태입니다.
그림 1.2 – 정규화된 판매 테이블 (ProductKey만 포함)비정규화 (Denormalization) – 편의성이나 성능을 위해 중복 데이터를 저장하는 방식.
예시: 판매 테이블에 제품 이름, 카테고리 등 제품 속성도 함께 포함하는 경우.
그림 1.3 – 비정규화된 판매 테이블 (ProductKey + 제품 속성)
내보내기 파일이나 데이터 추출에서 데이터를 가져올 때는 이미 비정규화된 경우가 많습니다. Power Query를 사용해 소스를 변환하고 여러 정규화된 테이블로 형태를 맞추세요.
Note: 사실 테이블과 차원 테이블은 정규화된 형태를 목표로 해야 하지만, 스노우플레이크 차원은 단일 모델 테이블을 만들기 위해 의도적으로 비정규화될 수 있습니다.
Source:
Power BI 시맨틱 모델과 스타 스키마의 관련성
스타 스키마 설계와 위의 개념은 성능이 뛰어나고 사용자 친화적인 Power BI 모델을 구축하는 데 매우 중요합니다.
- 각 Power BI 시각화는 시맨틱 모델에 대해 쿼리를 생성합니다.
- 쿼리는 일반적으로 필터링, 그룹화, 그리고 요약을 수행합니다.
잘 설계된 모델은 다음을 제공합니다:
- 차원 테이블 – 필터링 및 그룹화를 위해 사용됩니다.
- 사실 테이블 – 요약을 위해 사용됩니다.
테이블을 “차원” 또는 “사실”로 명시하는 별도의 속성은 없습니다. 역할은 모델 관계를 통해 추론됩니다:
- 관계의 카디널리티(일대다 또는 다대일)가 테이블 유형을 결정합니다.
- “일” 측은 항상 차원 테이블이며, “다” 측은 항상 사실 테이블입니다.

그림 1.4 – 일대다 관계 (차원 → 사실)
Snowflake Dimension
스노우플레이크 차원은 단일 비즈니스 엔터티를 나타내는 정규화된 테이블 집합입니다.
예를 들어, Adventure Works 데이터 웨어하우스에서는 제품이 카테고리와 서브카테고리로 분류됩니다:
- 제품은 서브카테고리에 속합니다.
- 서브카테고리는 카테고리에 속합니다.
따라서 제품 차원은 세 개의 관련된 정규화 테이블에 저장됩니다.
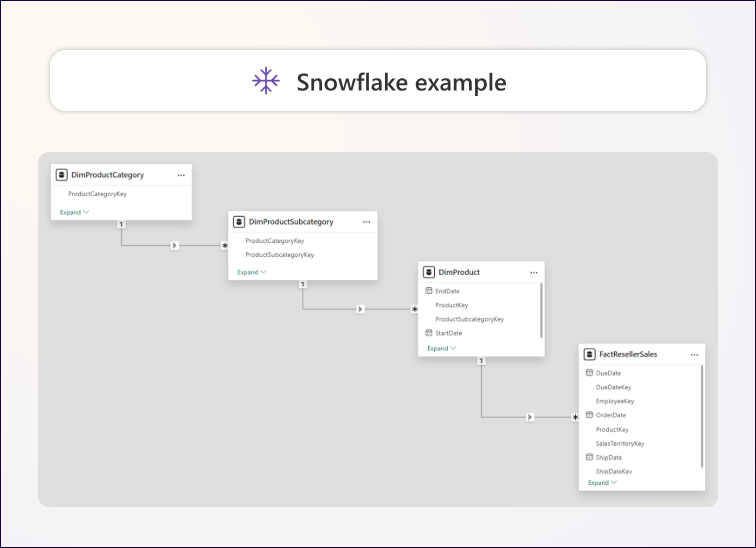
그림 1.5 – 제품 차원의 정규화된 테이블.
정규화된 테이블이 사실 테이블(fact table)에서 바깥쪽으로 퍼져 나가는 모습을 상상하면, 고전적인 “스노우플레이크” 형태를 볼 수 있습니다.
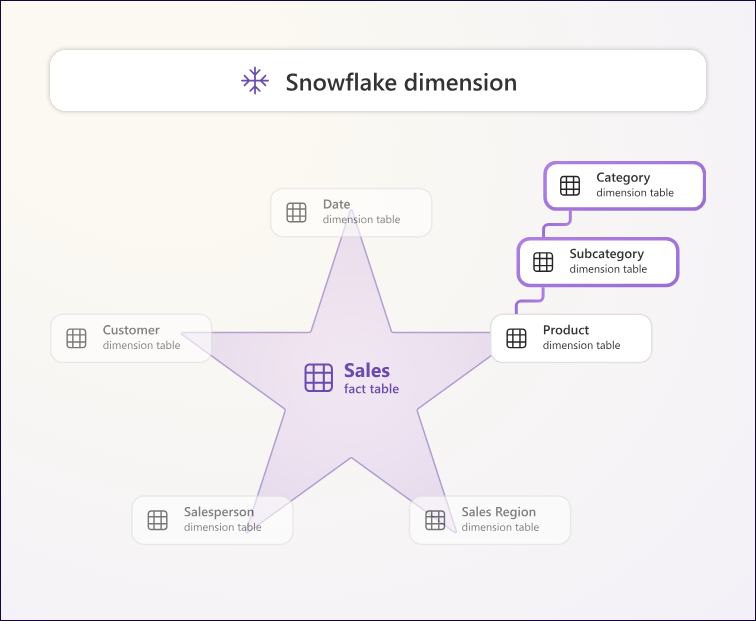
그림 1.6 – 스노우플레이크 설계 일러스트레이션.
Snowflake vs. Denormalized Design in Power BI Desktop
Power BI Desktop에서는 다음 중 하나를 선택할 수 있습니다:
- 스노우플레이크 차원 설계를 모방(대개 소스 데이터가 이미 정규화된 경우)하거나
- 소스 테이블을 하나의 비정규화 모델 테이블로 결합합니다.
일반적으로 단일 모델 테이블이 더 많은 이점을 제공하지만, 최적의 선택은 데이터 양과 사용성 요구 사항에 따라 달라집니다.
스노우플레이크 차원 설계를 모방할 때
- 스토리지 및 성능: 테이블 수가 늘어나 로드 효율이 떨어질 수 있습니다. 각 테이블은 관계를 지원하기 위한 컬럼을 포함해야 하므로 모델 크기가 증가합니다.
- 필터 전파: 관계 체인이 길어져야 하므로 필터 효율이 감소할 수 있습니다.
- 사용자 경험: 데이터 창에 많은 테이블이 표시되어 혼란스러울 수 있습니다—특히 스노우플레이크 테이블에 컬럼이 한두 개만 있을 때.
- 계층 구조: 여러 테이블에 걸친 컬럼으로 계층 구조를 만들 수 없습니다.
단일 모델 테이블로 통합할 때
- 계층 구조: 차원의 전체 입자(최상위 수준부터 최하위 수준까지)를 포괄하는 계층 구조를 정의할 수 있습니다.
- 스토리지 영향: 중복된 비정규화 데이터가 모델 크기를 증가시킬 수 있으며, 특히 차원 테이블이 큰 경우에 두드러집니다.
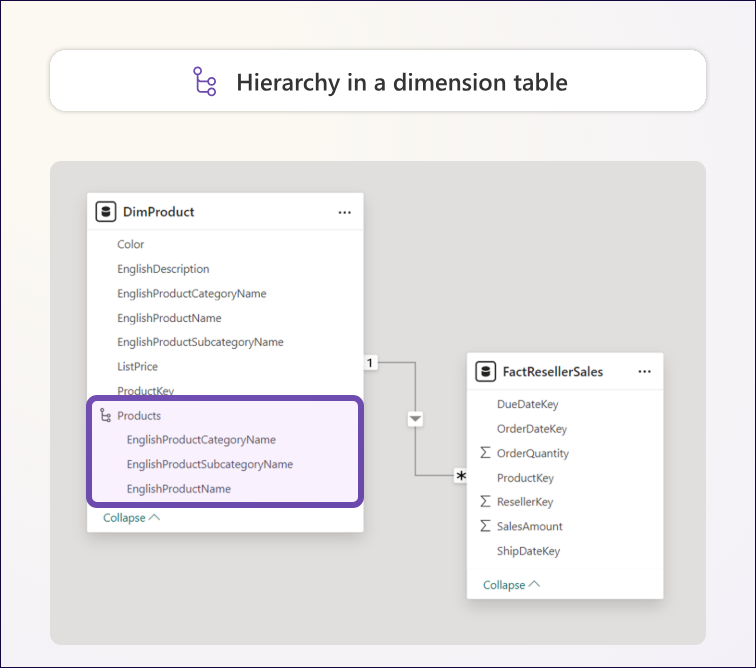
그림 1.7 – Power BI에서 스노우플레이크와 비정규화 설계의 비교.
주요 요점
특정 상황에 맞게 성능, 저장소, 사용자 경험의 균형을 맞추는 설계를 선택하십시오. 원본 데이터가 이미 정규화된 경우 Snowflake 설계가 유용할 수 있지만, 잘 설계된 비정규화 모델은 종종 더 나은 성능과 보다 직관적인 보고 경험을 제공합니다.