Project Valhalla, Explained: How a Decade of Work Arrives in JDK 28
출처: 해커 뉴스
6월 15일, 오라클 엔지니어 Lois Foltan 확인 한 부분이 업계의 많은 사람들이 더 이상 믿지 않게 했던 것입니다: **JEP 401: Value Classes and Objects**은 메인 OpenJDK 저장소에 통합될 것이고 JDK 28을 목표로 합니다.
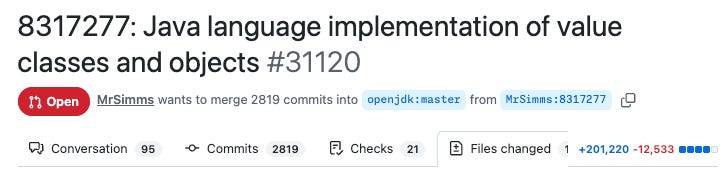
이 변경은 매우 크어서 나머지 커밋터들은 통합 동안 큰 커밋을 삼게 요청받았습니다. **pull request**만으로도 197,000줄 이상의 코드가 1,816개 파일에 추가됩니다.
샴페인을 터트리기 전에: 이것은 preview 로 기본적으로 비활성화되어 있으며, Brian Goetz는 재빨리 모두를 진정시켰고 “Valhalla의 첫 번째 부분만이다.” Goetz는 “they’ll never ship it” 그룹이 이제 부드럽게 “but they didn’t ship the most important part”(그리고 커뮤니티에서는 수년 동안 우리는 프로젝트가 출시되기 전에 Norse-afterlife인 Valhalla에 먼저 도착할 것이니 프로젝트 자체가 출시될 때까지)라는 관찰을 덧붙였습니다.
자신만의 비판가들을 얻어야 한다.
이것은 전체 이야기를 전하기에 좋은 시점입니다. 이 문제는 Valhalla 작업을从未 suivi한 적이 없다는 가정 하에 쓰인 대규모 심층 탐구입니다: 2014년 문제부터 아이디어의 진화(다수의 아이디어가 결국 쓰레기통에 넣어졌음)까지, JDK 28에서 실제로 손에 넣게 될 내용까지. 커피 한 잔 준비하세요. 저는 이 에디션을 오랫동안 보관하고, 정확히 이 okazyon을 위해 저장해 두었습니다.
Valhalla가 시작부터 이어온 슬로건은: “코드는 클래스처럼 보이고, int처럼 작동한다.” 한 문장으로 프로젝트의 전체 목적을 포착합니다: 우리는 정상적인 읽기 쉬운 클래스를 메서드와 생성자 검증, 의미 있는 필드 이름으로 쓸 수 있지만, JVM는 이를 원시 자료형과 같은 효율적으로 다룰 수 있기를 바랍니다.
이 문제를 이해하려면 Java의 근본을 돌아봐야 합니다. 이 언어에서 eight primitives( int, long, double, boolean 등)을 제외하고는 모든 것이 레퍼런스 타입입니다.Point p = new Point(1, 2)를 쓰면 변수 p는 a point가 아니라 포인터, 코트 체크 번호와 같습니다: 힙에 객체가 있으며 당신은 그 주소를 적힌 작은 종이 조각을 들고 있습니다. 필드를 읽고자 할 때마다 JVM은 “코트 체크를 가는다”고 해야 하며, 포인터(pointer indirection)를 통해 이동합니다.
단일 객체라면 문제될 게 없습니다. 문제가 시작되는 곳은 규모입니다. 힙에 있는 모든 객체는 각각 헤더(수십 바이트 정도의 메타데이터: 그 중에는 JVM이 타입을 알 수 있고 누군가가 이를 동기화하고 있는지 여부 등)가 있습니다. 이는 exactamente **Project Lilliput**가 최근에 해결하려는 문제이며, 객체 헤더 크기를 줄이는 데 도움을 줍니다. 하지만 헤더 크기만이 전부는 아닙니다. 모든 객체는 할당되어야 하고 나중에 **수거(GC)**를 받아야 합니다. 그리고 객체가 힙 전체에 흩어져 있기 때문에, 백만 개 포인트(Point) 배열은 실제로 백만 장의 종이 조각이 각각 창고 안을 뒤덮은 상자들을 가리키는 형태가 됩니다.
Brian Goetz는 그의 **“State of Valhalla” 문서**에서 이러한 메모리 레이아웃을 “fluffy”(부풀고 비대한)라고 부릅니다. 우리는 데이터가 나란히 배치된 dense 레이아웃을 꿈꿉니다.
왜 밀도가 중요한가? 하드웨어가 Java보다 더 빠르게 진화했기 때문입니다. 1995년, 메모리 접근 비용이 CPU 연산과 거의 동일했습니다. 오늘날 CPU는 메인 메모리보다 수백 배 빠르고, 이 간극은 캐시로 메워집니다. 프로세서는 cache line(보통 64바이트) 단위로 메모리를 읽습니다. 데이터가 밀집하고 정렬되어 있다면 한 번의 청크가 동시에 많은 유용한 값을 가져옵니다. 포인터를 건너가며 액세스한다면 매번 캐시 미스 위험이 있어, 이는 히트보다 수백 배 느릴 수 있습니다.这就是 참조 지역성, 이 전체 게임의 진정한 이해관계입니다.
“하지만 JVM에는 escape analysis가 있습니다,” 날카로운 사람이 말할 것입니다. 사실은: 가상 머신은 객체가 로컬 코드 조각을 넘어서 ‘도피’하지 않는다고 판단하면 아예 할당하지 않습니다. 프로그래머 입장에서는 객체가 존재하는 것처럼 보이지만, 실제로는 그 필드가 일반 변수나 CPU 레지스터로 분산됩니다. 최선의 경우, 할당 비용과 이후 GC 청소 비용이 거의 제로가 됩니다.
문제는 이 최적화가 예측 불가능하고 취약하다는 점입니다. 이는 JIT 컴파일러가 객체의 전체 흐름을 확신할 때만 작동합니다. 하지만 객체가 다른 클래스의 필드에 들어가거나 배열에 저장되고, 복잡한 메서드로 전달되거나, JIT가 분석할 수 있는 경계를 넘어선다면 이 모든 것이 중단됩니다. 소스 코드는 동일하지만 성능 동작은 극적으로 바뀔 수 있습니다.
이것은 precisamente 경험 많은 JVM 프로그래머들이 escape analysis를 a