벡터 검색 최적화
Source: Dev.to
저자 소개
저는 Mansi Tibude이며 전자통신공학 전공자입니다. 이전 조직에서 시스템 엔지니어로 약 3년 동안 IT 산업에서 근무했습니다. 다양한 기술에 대한 경험이 있으며, 항상 제때 결과를 제공했습니다. 저는 새로운 기술을 빠르게 배우고 실시간 애플리케이션을 구축하는 데 적용할 수 있는 근면하고 스마트한 직원입니다.
Abstract
벡터 검색은 전통적인 텍스트 검색보다 더 고급 기능을 제공하는 AI 기반 검색 기술입니다. 텍스트뿐만 아니라 오디오, 비디오, 이미지에 대한 결과도 검색할 수 있습니다.
Elasticsearch는 다른 검색 엔진에 비해 큰 장점을 가지고 있습니다: 하이브리드 검색을 제공하는데, 이는 의미 검색과 벡터 검색을 결합한 것으로, 최대 10× 빠른 더 정확한 결과를 제공합니다. 벡터 검색은 결과를 일반 텍스트가 아니라 벡터 데이터로 반환하므로, 사용자 검색을 표 형식으로 저장하는 데 유리합니다.
우리는 이미 Elasticsearch의 다양한 기능과 다른 검색 엔진과의 차이점을 알고 있지만, Blogathon 챌린지는 ELK 스택을 활용하여 내장된 Elasticsearch 엔진 내에서 추가 기능을 구현하고 혁신을 이루는 방법을 탐구하도록 요구합니다—특히 벡터 검색, 하이브리드 검색, 의미 검색 영역에서 말이죠.
Source: …
내용 본문
벡터, 하이브리드 및 의미 검색이 중요한 이유
벡터, 하이브리드, 의미 검색은 사용자 기대에 부합하는 결과를 제공하는 데 핵심적인 역할을 합니다. 그러나 우리는 종종 정확성을 높이면서 검색 쿼리에 더 많은 기능을 추가해야 합니다. 벡터 검색에서는 쿼리 결과가 벡터 형식으로 저장되고 반환됩니다.
핵심 질문: 특히 하이브리드 검색에서 벡터 검색을 어떻게 확장할 수 있을까?
확장 전략
- 하이브리드 확장 – 여러 확장 기법을 결합합니다.
- 수직 확장 – 단일 노드에 더 많은 리소스(CPU, 메모리, 스토리지)를 추가합니다.
벡터 검색은 다음과 같이 작동합니다:
- 문서와 쿼리를 벡터(임베딩)로 변환합니다.
- 효율적인 벡터 연산을 가능하게 하기 위해 해당 벡터를 저장합니다.
- 다양한 매칭 함수를 사용해 빠른 유사도 계산을 수행합니다.
벡터 검색을 구동하는 K‑Nearest Neighbor (KNN) 머신러닝 모델과, 데이터를 수치 벡터로 변환하는 Retrieval‑Augmented Generation (RAG) 가 있습니다. 재정렬 알고리즘은 결과의 순서를 다시 매겨 관련성을 향상시킵니다.
벡터 데이터베이스의 역할
벡터 데이터베이스는 고차원 벡터를 고효율로 저장하는 시스템입니다. 주요 장점은 다음과 같습니다:
- 확장성
- 인덱싱 및 검색 성능
- 하이브리드 검색 지원
- 기술 스택 통합
벡터 검색 사양
- 수동 구성
- 자체 임베딩(실시간 임베딩 생성)
- 벡터에 대한 직접 유사도 매칭
벡터 검색 작동 방식:
- 임베딩 생성 – AI 모델이 원시 데이터를 임베딩으로 인코딩합니다.
- 인덱싱 – 임베딩을 벡터 형태로 인덱싱합니다.
- 검색 – 엔진이 쿼리 벡터를 저장된 벡터와 매칭하여 컨텍스트를 이해하고 관련 결과를 반환합니다.
벡터 검색이 해결하는 과제
- 의미 이해 – 쿼리 뒤에 숨은 의도를 파악합니다.
- 멀티모달 기능 – 텍스트, 오디오, 비디오, 이미지 등을 처리합니다.
- 개인화 및 추천 – 개별 사용자에게 맞춤형 결과를 제공합니다.
벡터 데이터베이스 개요
벡터 데이터베이스는 고차원 벡터를 저장하고 다음과 같은 기능을 제공합니다:
- Scalability – 데이터 양이 증가해도 처리 가능
- Efficient indexing & search performance
- Hybrid‑search support (키워드 검색과 벡터 검색을 결합)
- Seamless integration with existing tech stacks
Source: …
벡터 검색을 위한 Elasticsearch 확장
Elasticsearch는 세 가지 주요 검색 유형을 지원할 수 있습니다:
- 인덱스 및 기본 검색
- 키워드 검색 (예: Python을 통해)
- 의미 검색
- 벡터 검색
- 하이브리드 검색
우리의 초점은 벡터 검색 최적화에 있습니다. 아래는 두 가지 주요 확장 접근 방식입니다.
수직 확장
단일 Elasticsearch 노드의 리소스를 늘립니다:
- CPU 코어 추가
- 더 빠른 스토리지 사용 (SSD, NVMe)
- 캐싱 레이어 구현
- 처리 파이프라인 최적화
벡터 검색을 위한 캐싱 메커니즘:
- 스토리지 수준 캐싱 – 디스크에 인덱싱된 벡터를 캐시합니다.
- 임베딩 캐싱 – 사전 계산된 임베딩을 저장합니다.
- 쿼리 수준 캐싱 – 동일한 쿼리 결과를 재사용합니다.
- LLM 출력 캐싱 – 대형 언어 모델 응답을 캐시합니다.
추가 옵션:
- TPU 또는 특수 AI 가속기 배치.
- 낮은 지연 시간을 위해 ML 모델 최적화.
수평 확장
작업 부하를 여러 노드와 샤드에 분산합니다:
- 데이터 노드 수 증가.
- 벡터 데이터를 분산시키기 위해 샤드 추가.
- 마이크로서비스 스타일 아키텍처를 활용해 부하 균형을 맞춥니다.
수평 확장 전술:
- 노드 확장 – 클러스터에 Elasticsearch 노드를 더 추가합니다.
- 샤드 확장 – 더 나은 병렬 처리를 위해 추가 기본 및 복제 샤드를 생성합니다.

벡터 검색을 최적화하면 검색 효율성이 향상되고, 결과가 더 빠르게 제공되며, 사용자 상호작용으로 수집된 데이터를 보다 잘 관리할 수 있습니다.
실제 적용 사례
Docusign
- Domain: 지능형 계약 관리 (IAM)
- Scale: 수백만 명의 사용자
- Use case: 텍스트, PDF, 스캔 이미지 등 다양한 형태(모달리티)에서 계약 조항, 서명 및 관련 문서를 빠르고 의미론적으로 검색.
기업은 계약을 생성, 관리 및 분석합니다. IAM 도입 이전에는 사용자가 여러 플랫폼을 통해 계약을 찾아야 했습니다.
Docusign 및 벡터 검색
Docusign은 Elasticsearch와 벡터 검색을 함께 사용하여 매일 수십억 건의 새로운 계약을 처리하고 고객에게 빠른 결과를 제공합니다.
Elasticsearch 기술을 기반으로 한 벡터 검색은 검색 방식을 혁신했습니다. 검색 입력은 텍스트, 이미지, 키워드, 오디오 또는 비디오가 될 수 있습니다. 또한 손글씨와 예술 작품(예: 그림)에서 컨텍스트를 추출하여 의미를 이해하고 관련 결과를 반환하는 기능을 추가할 수 있습니다.
자연어 처리(NLP)를 사용하여 손글씨와 예술 작품에서 컨텍스트를 추출함으로써 원하는 결과와 유사한 결과를 모두 제공할 수 있습니다.
벡터 검색 최적화 및 기능 추가
벡터‑검색 기본 설계는 의미 검색, 벡터 데이터베이스, Elasticsearch 등 다양한 기술을 사용합니다. 검색 컨텍스트로 다른 종류의 입력을 활용할 수 있도록 벡터‑검색 기준에 두 가지 추가 기능을 도입할 수 있습니다.
수정된 아키텍처 설계
아래 다이어그램은 이제 이미지, 오디오, 비디오, 필기 및 아트워크를 입력으로 받아들이는 수정된 벡터‑검색 아키텍처를 보여줍니다.
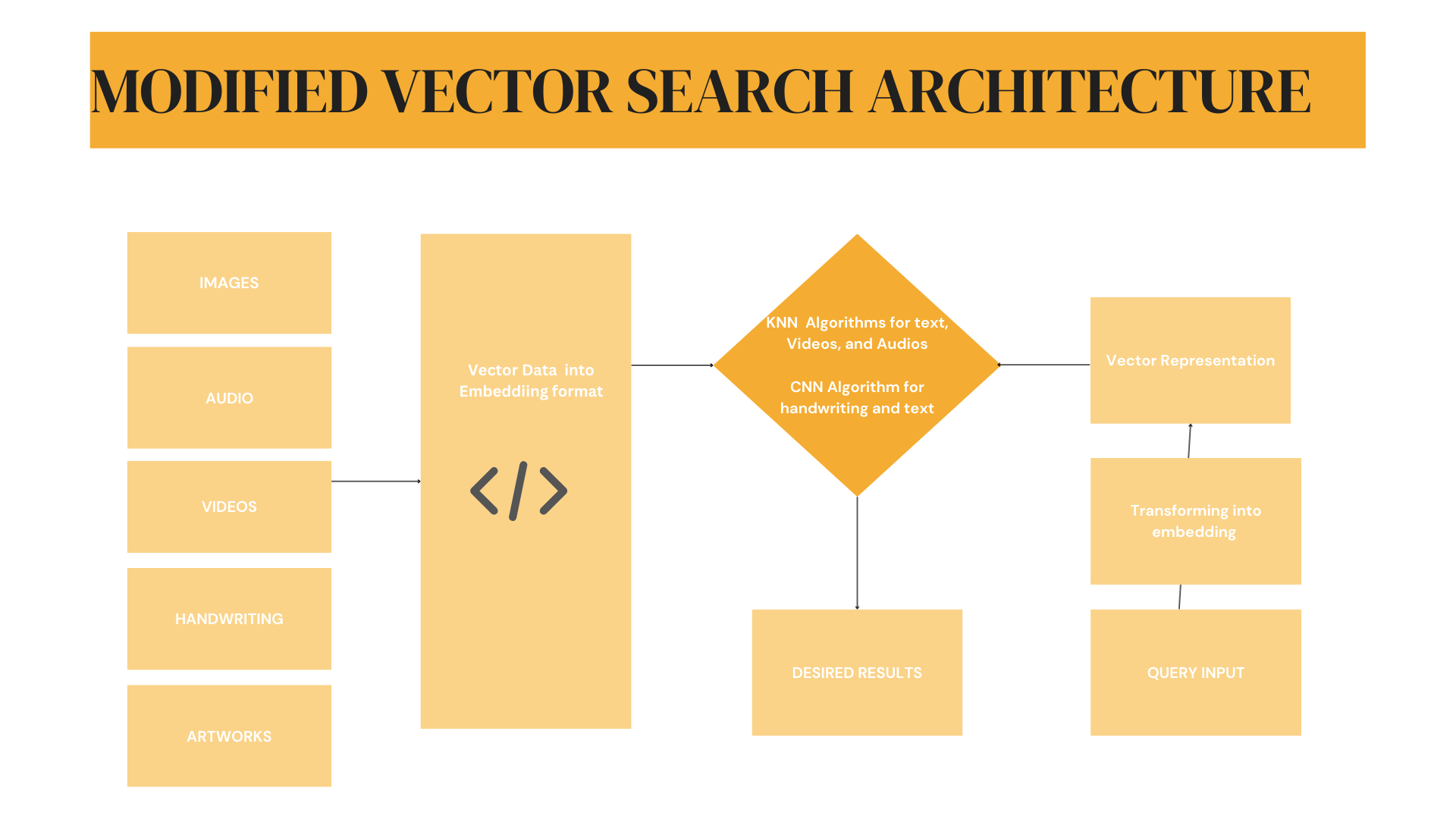
- 이미지, 오디오, 비디오 → K‑Nearest Neighbors (KNN) 로 처리
- 필기 및 아트워크 → Convolutional Neural Networks (CNN), NLP 파이프라인의 한 구성 요소로 처리
결론 / 요점
- Vector search와 semantic search는 수백만 건의 쿼리를 효율적으로 처리함으로써 검색 경험을 혁신합니다.
- Semantic search는 텍스트, 오디오, 비디오와 같은 풍부한 컨텍스트를 통합하여 결과를 개선하고 기존 검색 엔진보다 더 빠르게 제공합니다.
- 검색 쿼리는 벡터 데이터로 저장되며, 이를 활용해 머신러닝 모델을 학습시킬 수 있습니다.
- Elasticsearch는 검색 기준을 혁신했을 뿐만 아니라 보다 컨텍스트가 풍부한 결과를 제공합니다.
Disclosure: 이 블로그는 Elastic Blogathon의 일환으로 제출되었습니다.