Mixture of Experts가 가장 지능적인 Frontier AI 모델에 동력을 제공하고, NVIDIA Blackwell NVL72에서 10배 빠르게 실행됩니다
Source: NVIDIA AI Blog
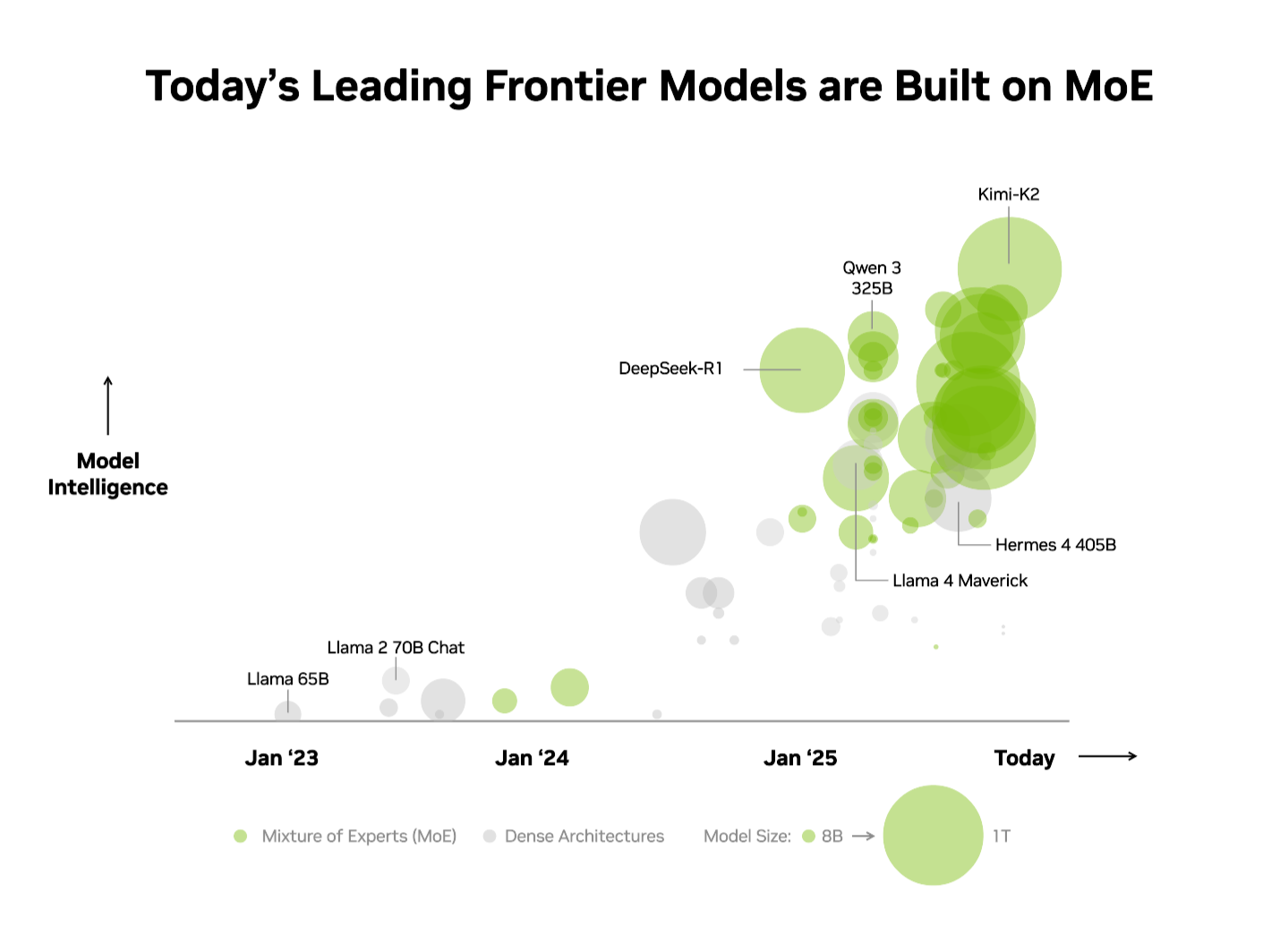
- The top 10 most intelligent open-source models all use a mixture-of-experts architecture.
- Kimi K2 Thinking, DeepSeek‑R1, Mistral Large 3 and others run 10× faster on NVIDIA GB200 NVL72.
오늘날 거의 모든 최첨단 모델의 내부를 들여다보면 인간 두뇌의 효율성을 모방한 mixture‑of‑experts (MoE) 아키텍처가 사용되고 있음을 알 수 있습니다. 뇌가 작업에 따라 특정 영역을 활성화하듯이, MoE 모델은 전문화된 “전문가”들 사이에 작업을 분산시키고 각 AI 토큰에 대해 관련된 전문가만 활성화합니다. 이로 인해 컴퓨팅 비용이 비례적으로 증가하지 않으면서 토큰 생성 속도가 빨라지고 효율성이 높아집니다.
업계는 이미 이 장점을 인식하고 있습니다. 독립적인 Artificial Analysis (AA) leaderboard에서 상위 10개의 가장 지능적인 오픈‑소스 모델은 MoE 아키텍처를 사용하고 있으며, 여기에는 DeepSeek AI의 DeepSeek‑R1, Moonshot AI의 Kimi K2 Thinking, OpenAI의 gpt‑oss‑120B, Mistral AI의 Mistral Large 3 등이 포함됩니다.
생산 환경에서 MoE 모델을 확장하면서 높은 성능을 제공하는 일은 매우 어렵습니다. NVIDIA GB200 NVL72 시스템의 극한 코디자인은 하드웨어와 소프트웨어 최적화를 결합해 최대 성능과 효율성을 제공하므로, MoE 모델을 실용적이고 간단하게 확장할 수 있습니다.
AA 리더보드에서 가장 지능적인 오픈‑소스 모델로 평가받은 Kimi K2 Thinking MoE 모델은 NVIDIA HGX H200에 비해 NVIDIA GB200 NVL72 랙‑스케일 시스템에서 10배 성능 향상을 보였습니다. DeepSeek‑R1 및 Mistral Large 3 MoE 모델에 대해 제공된 성능을 기반으로 한 이번 돌파구는 MoE가 최첨단 모델의 표준 아키텍처가 되고 있음을 강조하며, NVIDIA의 풀‑스택 추론 플랫폼이 그 잠재력을 완전히 발휘하는 핵심임을 보여줍니다.
What Is MoE, and Why Has It Become the Standard for Frontier Models?
최근까지 더 똑똑한 AI를 구축하기 위한 업계 표준은 모든 파라미터를 사용하는 더 크고 조밀한 모델을 만드는 것이었습니다. 오늘날 가장 강력한 모델들은 수천억 개의 파라미터를 사용해 매 토큰을 생성했습니다. 이 접근 방식은 강력하지만 막대한 컴퓨팅 파워와 에너지를 필요로 하며, 확장이 어려운 단점이 있습니다.
인간 두뇌가 언어 처리, 객체 인식, 수학 문제 해결 등 다양한 인지 작업을 담당하는 특정 영역에 의존하듯이, MoE 모델은 여러 전문화된 “전문가”들로 구성됩니다. 토큰 하나당 라우터가 가장 관련성 높은 전문가만 활성화합니다. 따라서 전체 모델이 수천억 개의 파라미터를 보유하고 있더라도 토큰을 생성할 때는 보통 수백억 개 수준의 작은 부분만 사용됩니다.
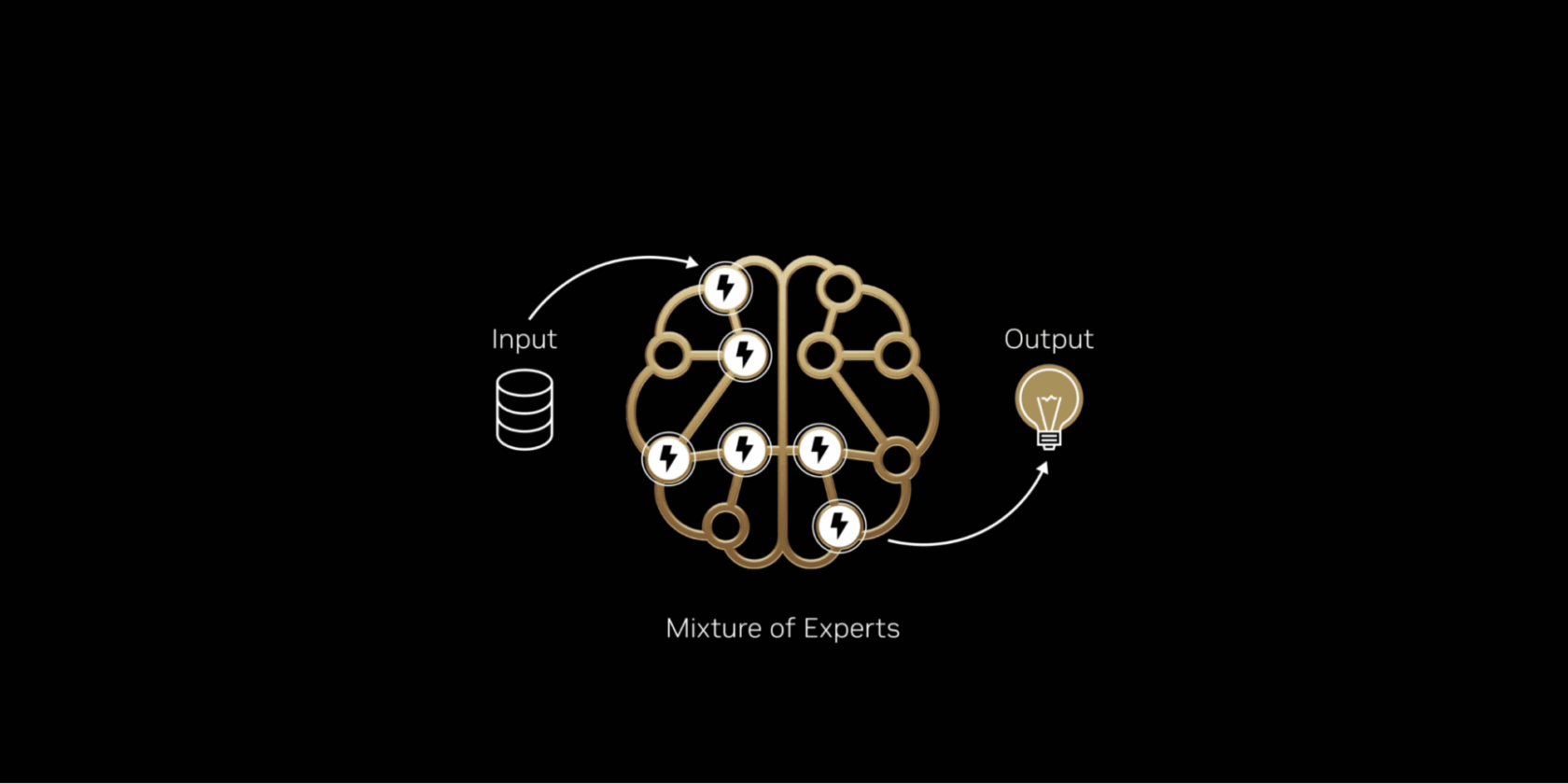
가장 중요한 전문가만 선택적으로 활용함으로써 MoE 모델은 계산 비용이 크게 증가하지 않으면서도 높은 지능과 적응성을 달성합니다. 이는 달러와 와트당 성능을 최적화한 효율적인 AI 시스템의 기반이 되며, 투자된 에너지와 자본당 훨씬 더 많은 지능을 생성합니다.
이러한 장점 덕분에 MoE는 올해 오픈‑소스 AI 모델 릴리즈의 60 % 이상이 채택할 정도로 빠르게 최첨단 모델의 표준 아키텍처가 되었습니다. 2023년 초부터 MoE는 모델 지능을 거의 70배 증가시켰으며, AI 역량의 한계를 크게 넓히고 있습니다.
“Our pioneering work with OSS mixture‑of‑experts architecture, starting with Mixtral 8x7B two years ago, ensures advanced intelligence is both accessible and sustainable for a broad range of applications,” said Guillaume Lample, co‑founder and chief scientist at Mistral AI. “Mistral Large 3’s MoE architecture enables us to scale AI systems to greater performance and efficiency while dramatically lowering energy and compute demands.”
Overcoming MoE Scaling Bottlenecks With Extreme Codesign
최첨단 MoE 모델은 단일 GPU에 배치하기엔 너무 크고 복잡합니다. 이를 실행하려면 전문가들을 여러 GPU에 분산시키는 전문가 병렬화 기법이 필요합니다. NVIDIA H200과 같은 강력한 플랫폼에서도 MoE 모델을 배포하면 다음과 같은 병목 현상이 발생합니다:
- 메모리 제한 – 각 토큰마다 GPU는 선택된 전문가의 파라미터를 고대역폭 메모리에서 동적으로 로드해야 하므로 메모리 대역폭에 큰 압력이 가해집니다.
- 지연 시간 – 전문가들은 최종 답변을 만들기 위해 거의 즉시 전‑전체(all‑to‑all) 통신 패턴을 수행해야 합니다. H200에서 8개 이상의 GPU에 전문가를 분산하면 고지연 스케일‑아웃 네트워킹을 통해 통신해야 하므로 전문가 병렬화의 이점이 제한됩니다.
The solution: extreme codesign
NVIDIA GB200 NVL72은 72개의 NVIDIA Blackwell GPU가 마치 하나처럼 협업하는 랙‑스케일 시스템으로, 1.4 exaflops의 AI 성능과 30 TB의 빠른 공유 메모리를 제공합니다. GPU들은 NVLink 스위치를 통해 단일 거대한 NVLink 패브릭으로 연결되어 130 TB/s의 NVLink 연결성을 구현합니다.
MoE 모델은 이 설계를 활용해 전문가 병렬화를 이전 한계를 훨씬 넘어 확장할 수 있습니다—전문가들을 최대 72개의 GPU에 걸쳐 분산시킬 수 있습니다.
이 아키텍처 접근 방식은 MoE 확장 병목을 직접 해결합니다:
- GPU당 전문가 수 감소 – 최대 72개의 GPU에 전문가를 분산하면 각 GPU의 고대역폭 메모리에 대한 파라미터 로드 압력이 최소화되고, 더 많은 동시 사용자와 더 긴 입력 길이를 위한 메모리가 확보됩니다.
- 전문가 간 통신 가속 – GPU에 분산된 전문가들은 NVLink를 통해 즉시 통신할 수 있습니다. NVLink 스위치는 다양한 전문가의 정보를 결합하는 연산력도 제공해 최종 답변 전달 속도를 높입니다.
