LiteRT: 온-디바이스 AI를 위한 범용 프레임워크
Source: Google Developers Blog
JAN. 28, 2026
2024년에 처음 LiteRT를 소개한 이후, 우리는 TensorFlow Lite (TFLite) 기반에서 현대적인 온‑디바이스 AI 프레임워크로 ML 기술 스택을 발전시키는 데 집중해 왔습니다. TFLite가 고전적인 ML의 표준을 정립했듯이, 우리의 목표는 개발자들이 과거에 고전적인 ML을 통합하던 것처럼 오늘날 최첨단 AI를 온‑디바이스에 손쉽게 배포할 수 있도록 지원하는 것입니다.
Google I/O ‘25에서 우리는 이 진화의 프리뷰를 공유했습니다: 고급 하드웨어 가속을 위해 특별히 설계된 고성능 런타임. 오늘 우리는 이러한 고급 가속 기능이 LiteRT 프로덕션 스택에 완전히 통합되었으며, 이제 모든 개발자에게 제공된다는 소식을 전하게 되어 기쁩니다.
이 이정표는 AI 시대를 위한 범용 온‑디바이스 추론 프레임워크로서 LiteRT를 확고히 하며, TFLite에 비해 다음과 같은 큰 도약을 의미합니다:
- 더 빠름 – TFLite 대비 GPU 성능이 1.4배 빨라졌으며, 최신 NPU 가속을 새롭게 도입했습니다.
- 더 간단함 – 엣지 플랫폼 전반에 걸친 GPU와 NPU 가속을 위한 통합되고 간소화된 워크플로를 제공합니다.
- 더 강력함 – Gemma와 같은 인기 오픈 모델을 위한 뛰어난 크로스‑플랫폼 GenAI 배포를 지원합니다.
- 더 유연함 – 원활한 모델 변환을 통해 일류 PyTorch/JAX 지원을 제공합니다.
이 모든 기능은 TFLite 이후 여러분이 신뢰해 온 안정적이고 크로스‑플랫폼 배포를 유지하면서 제공됩니다.
다음은 LiteRT가 차세대 온‑디바이스 AI 구축을 어떻게 지원하는지에 대한 내용입니다.
Source: …
고성능 크로스‑플랫폼 GPU 가속
Android에서 I/O ‘25에 발표된 초기 GPU 가속을 넘어, Android, iOS, macOS, Windows, Linux, 그리고 Web 전반에 걸친 완전하고 포괄적인 GPU 지원을 소개하게 되어 기쁩니다. 이번 확장은 개발자에게 고전적인 CPU 추론을 크게 능가하는 신뢰할 수 있는 고성능 가속 옵션을 제공합니다.
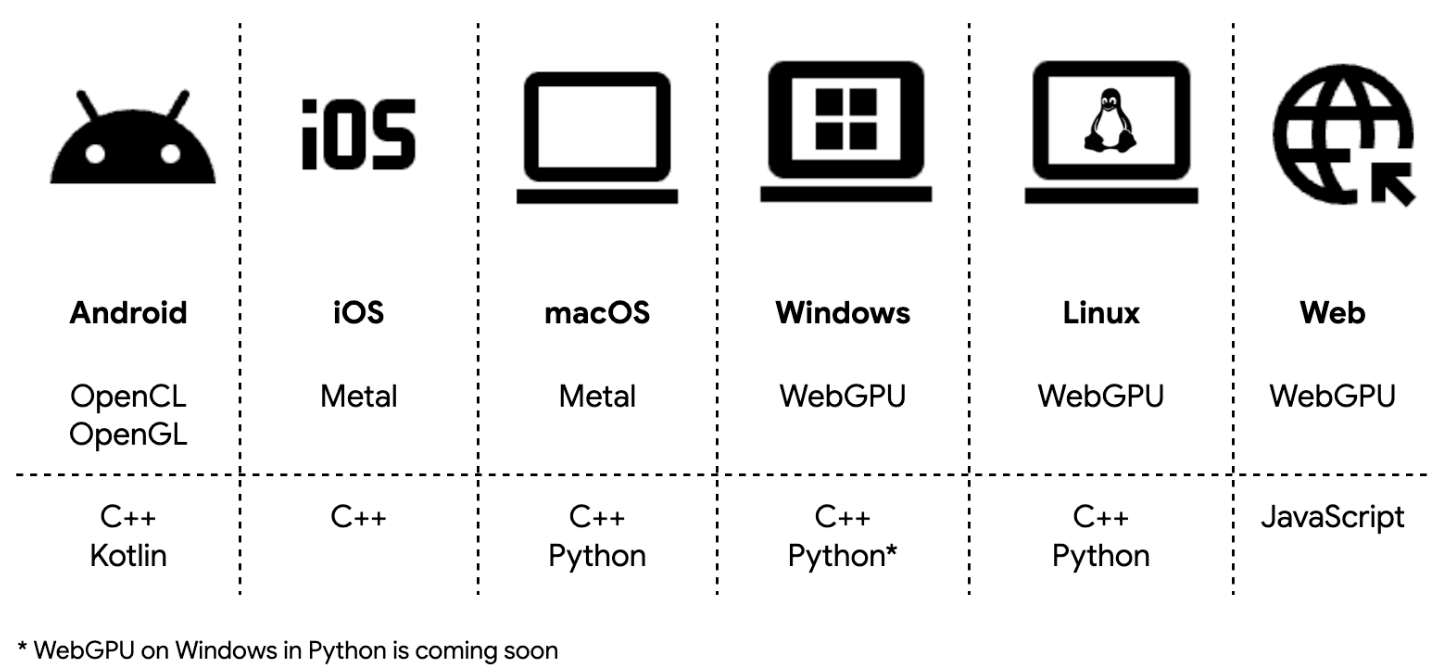
LiteRT는 ML Drift라는 차세대 GPU 엔진을 통해 OpenCL, OpenGL, Metal, 그리고 WebGPU를 지원함으로써 모바일, 데스크톱, 웹 전반에 걸친 효율적인 배포를 가능하게 합니다. Android에서는 LiteRT가 사용 가능한 경우 자동으로 OpenCL을 우선 선택해 최고 성능을 제공하고, 보다 넓은 기기 호환성을 위해 OpenGL로 폴백합니다.
ML Drift에 의해 강화된 LiteRT GPU는 기존 TFLite GPU delegate 대비 평균 1.4배 빠른 성능을 제공하여 다양한 모델에서 지연 시간을 크게 줄입니다. 자세한 벤치마크 결과는 이전 발표를 참고하세요.
고성능 AI 애플리케이션을 가능하게 하기 위해 다음과 같은 핵심 기술 진보를 도입했습니다:
- 비동기 실행
- 제로‑복사 버퍼 상호 운용성
이 기능들은 불필요한 CPU 오버헤드를 제거하고 전체 성능을 끌어올려, 배경 분할 및 음성 인식(ASR)과 같은 실시간 사용 사례를 충족합니다. 실제로는 Segmentation 샘플 앱에서 2배까지 빠른 성능을 보여줍니다. 더 깊이 있는 내용은 기술 심층 분석을 확인하세요.
예시: CompiledModel API (C++)를 이용한 GPU 가속
// 1. Create a compiled model targeting GPU.
auto compiled_model = CompiledModel::Create(env, "mymodel.tflite",
kLiteRtHwAcceleratorGpu);
// 2. Wrap an OpenGL buffer with zero‑copy.
auto input_buffer = TensorBuffer::CreateFromGlBuffer(env, tensor_type,
opengl_buffer);
std::vector<TensorBuffer*> input_buffers{input_buffer};
auto output_buffers = compiled_model.CreateOutputBuffers();
// 3. Execute the model.
compiled_model.Run(input_buffers, output_buffers);
// 4. Access model output (AHardwareBuffer).
auto ahwb = output_buffers[0]->GetAhwb();자세한 내용은 LiteRT 크로스‑플랫폼 개발 및 GPU 가속 문서를 참고하세요.
최고 성능을 위한 간소화된 NPU 통합
CPU와 GPU가 폭넓은 다재다능성을 제공하는 반면, NPU는 현대 애플리케이션이 요구하는 부드럽고 반응성이 뛰어나며 고속 AI 경험을 가능하게 합니다. 수백 가지 NPU SoC 변형에 걸친 파편화는 전통적으로 개발자들을 복잡하고 임시적인 배포 워크플로우로 몰아넣었습니다.
LiteRT는 통합되고 간소화된 NPU 배포 워크플로우를 제공하여 저수준의 공급업체별 SDK를 추상화합니다. 이 프로세스는 간단한 3단계 흐름입니다:
- AOT 컴파일 (선택 사항) – LiteRT Python 라이브러리를 사용해 대상 SoC용
.tflite모델을 사전 컴파일합니다. - Android에서 Google Play를 통한 온‑디바이스 AI (PODAI) 배포 – PODAI는 모델과 런타임을 호환되는 디바이스에 자동으로 전달합니다.
- LiteRT Runtime을 이용한 추론 – LiteRT는 NPU 위임을 처리하고 필요 시 GPU 또는 CPU로의 견고한 폴백을 제공합니다.
전체 가이드와 Colab 노트북, 샘플 앱은 LiteRT NPU 문서에서 확인할 수 있습니다.
LiteRT는 사전 컴파일(AOT) 과 온‑디바이스 컴파일(JIT) 두 방식을 모두 지원합니다:
- AOT – 대상 SoC가 명확한 복잡한 모델에 이상적이며 초기화 시간과 메모리 사용량을 최소화합니다.
- JIT – 많은 플랫폼에 배포되는 작은 모델에 최적이며 사전 컴파일이 필요 없지만 첫 실행 시 비용이 더 높습니다.
우리의 첫 번째 프로덕션‑레디 통합은 MediaTek 과 Qualcomm 과 함께 제공됩니다. 기술 심층 분석을 통해 최고 수준의 NPU 성능을 확인했으며, CPU 대비 최대 100배, GPU 대비 10배 빠른 속도를 달성했습니다:
비디오 데모 자리표시는 생략되었습니다.
우리는 LiteRT의 NPU 지원을 추가 하드웨어로 계속 확장할 예정이니, 향후 발표를 기대해 주세요!
우수한 크로스‑플랫폼 GenAI 지원
오픈 모델은 유연성을 제공하지만 배포 시 마찰이 클 수 있습니다. LiteRT는 이 워크플로를 단순화하기 위한 통합 스택을 제공합니다:
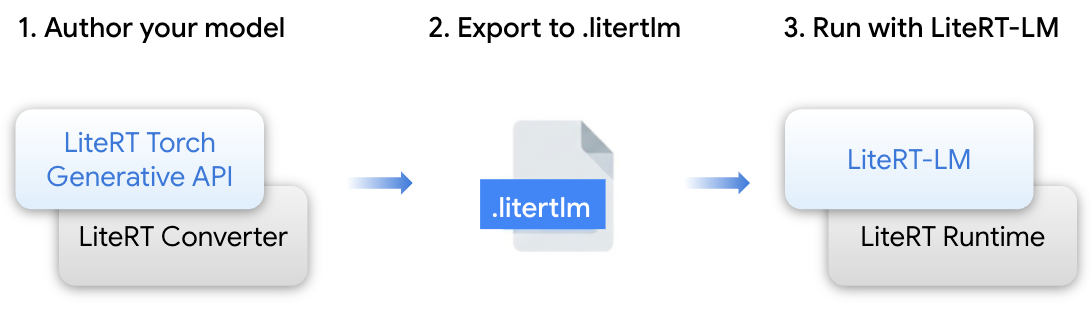
- LiteRT Torch Generative API – PyTorch 트랜스포머 모델을 LiteRT‑LM/LiteRT 포맷으로 작성하고 변환하기 위한 Python 모듈.
- LiteRT‑LM – LiteRT 위에 구축된 오케스트레이션 레이어로, LLM‑특화 복잡성을 관리합니다; Gemini Nano를 Google 제품(Chrome, Pixel Watch) 전반에 배포하는 역할을 담당합니다.
- LiteRT Converter & Runtime – CPU, GPU, NPU 전반에 걸쳐 효율적인 모델 변환, 런타임 실행 및 최적화를 수행하는 핵심 엔진.
벤치마크 예시
우리는 Gemma 3 1B를 Samsung Galaxy S25 Ultra에서 벤치마크했으며, LiteRT와 Llama.cpp를 비교했습니다. LiteRT는 프리필(prefill)과 디코드(decode) 모두에서 CPU와 GPU 모두에서 Llama.cpp보다 우수했으며, NPU 가속을 통해 프리필에서 GPU 대비 추가 **3×**의 성능 향상을 달성했습니다.
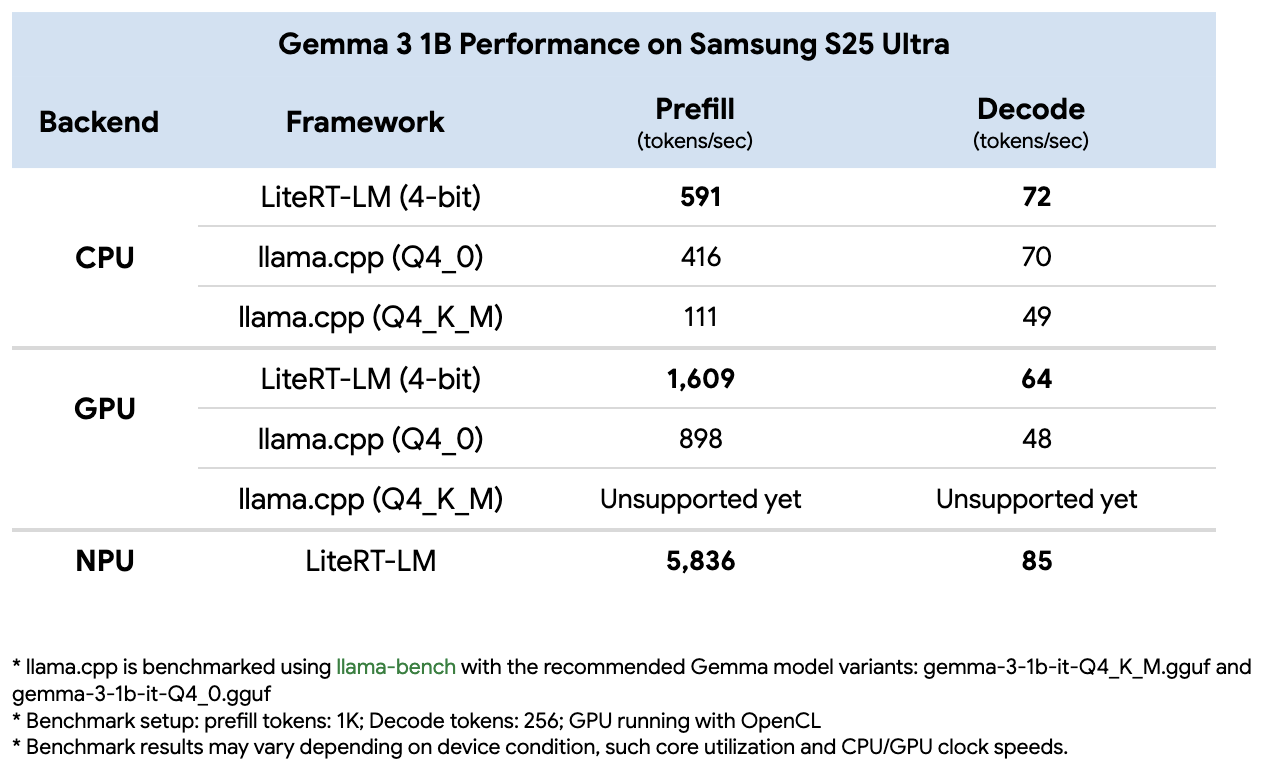
이 결과 뒤에 숨은 엔지니어링을 자세히 살펴보려면 LiteRT의 내부 최적화 기사을 읽어보세요.
LiteRT는 다음과 같은 사전 변환된 오픈‑웨이트 모델 컬렉션을 지속적으로 확대하고 있습니다:
- Gemma family – Gemma 3 (270 M, 1 B), Gemma 3n, EmbeddingGemma, FunctionGemma
- Qwen, Phi, FastVLM 등 기타 모델
이 모델들은 LiteRT Hugging Face Community에서 제공되며, Android와 iOS에서 Google AI Edge Gallery 앱을 통해 탐색할 수 있습니다.
자세한 내용은 LiteRT GenAI 문서를 참고하세요.
다양한 ML 프레임워크 지원

LiteRT는 업계에서 가장 많이 사용되는 프레임워크에서 원활한 모델 변환을 가능하게 합니다:
- PyTorch – LiteRT Torch 라이브러리를 사용하여 PyTorch 모델을 직접
.tflite로 변환합니다. - TensorFlow & JAX – TensorFlow에 대한 최고 수준의 지원과
jax2tf브리지를 통한 JAX 모델 변환을 계속해서 활용할 수 있습니다.
이러한 경로를 통합함으로써, LiteRT는 선호하는 개발 환경에 관계없이 연구‑에서‑생산 단계로의 전환을 가속화합니다. LiteRT Torch Colab으로 시작하거나 이 deep dive에서 기술 세부 정보를 살펴보세요.
신뢰성과 호환성을 믿을 수 있습니다
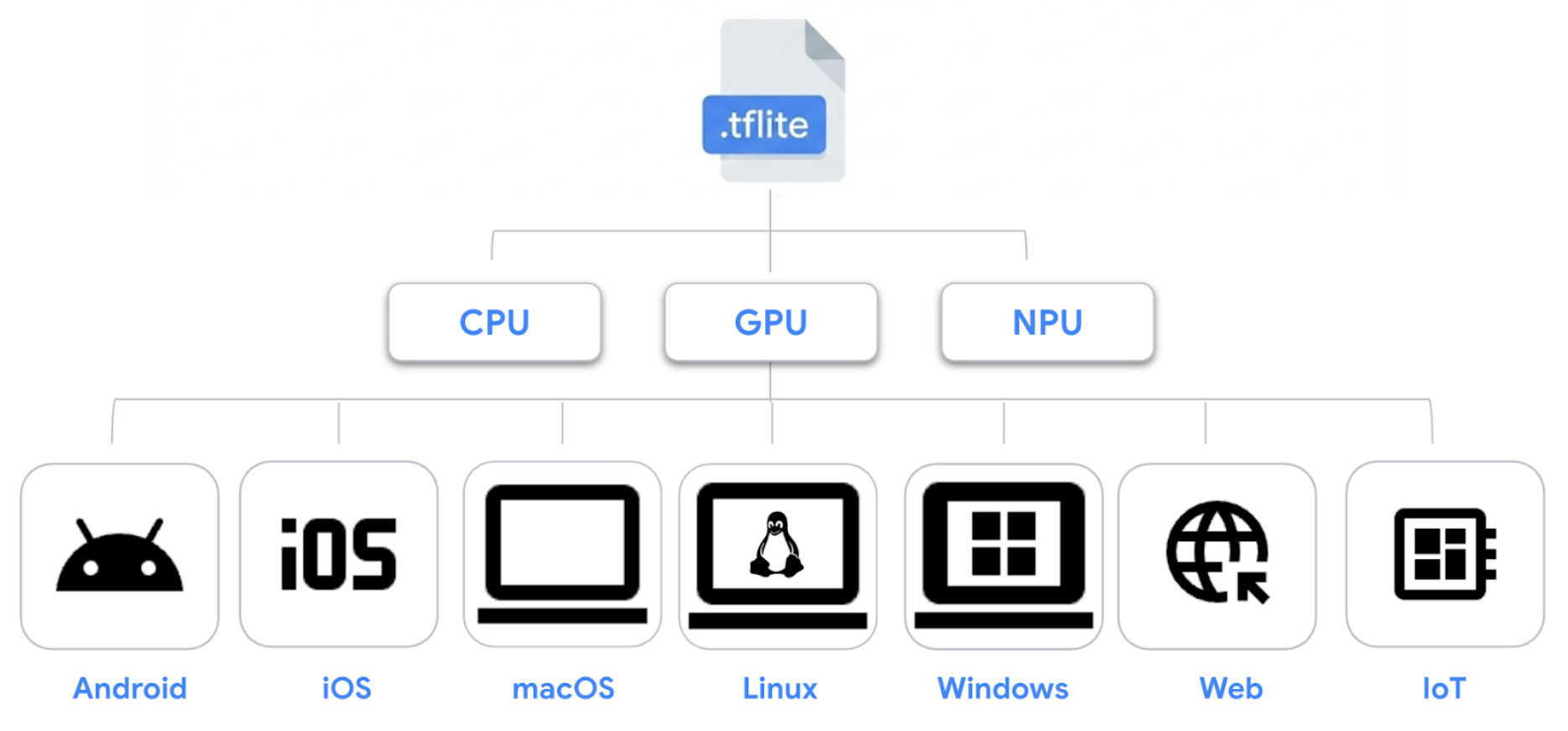
LiteRT는 검증된 .tflite 모델 형식을 기반으로 하여 기존 모델이 Android, iOS, macOS, Linux, Windows, Web, 그리고 IoT 전반에 걸쳐 이동 가능하고 호환성을 유지하도록 합니다.
두 가지 실행 경로를 지원합니다:
- Interpreter API – 기존 프로덕션 모델에 대한 확고한 안정성을 보장합니다.
- CompiledModel API – 차세대 AI 워크로드를 위한 GPU 및 NPU 가속을 완전히 활용할 수 있는 최신 인터페이스입니다. CompiledModel API를 선택해야 하는 이유는 문서에서 확인하세요.
다음 단계
온‑디바이스 AI의 미래를 구축할 준비가 되셨나요? 다음 리소스로 시작해 보세요:
- 포괄적인 가이드를 위해 LiteRT Documentation을 탐색하세요.
- 코드 예제를 위해 LiteRT GitHub와 LiteRT Samples repo를 방문하세요.
- 즉시 사용할 수 있는 오픈 모델을 위해 LiteRT Hugging Face Community를 둘러보고, Google AI Edge Gallery app을 Android 또는 iOS에서 사용해 보세요.
피드백을 제공하거나 기능을 요청하려면 우리 GitHub 채널에 이슈를 열어 주세요. LiteRT로 무엇을 만들지 기대됩니다!
감사의 말씀
이 릴리스를 가능하게 한 기여를 해주신 팀원 및 협력자들에게 감사드립니다: Advait Jain, Andrew Zhang, Andrei Kulik, Akshat Sharma, Arian Arfaian, Byungchul Kim, Changming Sun, Chunlei Niu, Chun‑nien Chan, Cormac Brick, David Massoud, Dillon Sharlet, Fengwu Yao, Gerardo Carranza, Jingjiang Li, Jing Jin, Grant Jensen, Jae Yoo, Juhyun Lee, Jun Jiang, Kris Tonthat, Lin Chen, Lu Wang, Luke Boyer, Marissa Ikonomidis, Matt Kreileder, Matthias Grundmann, Majid Dadashi, Marko Ristić, Matthew Soulanille, Na Li, Ping Yu, Quentin Khan, Raman Sarokin, Ram Iyengar, Rishika Sinha, Sachin Kotwani, Shuangfeng Li, Steven Toribio, Suleman Shahid, Teng‑Hui Zhu, Terry (Woncheol) Heo, Vitalii Dziuba, Volodymyr Kysenko, Weiyi Wang, Yu‑Hui Chen, Pradeep Kuppala, 그리고 gTech 팀.