Liferay Commerce 성능: 100k+ SKU 가져오기를 확장한 방법 (JVM 충돌 없이)
Source: Dev.to
만약 여러분이 Liferay Commerce 7.4를 사용해 진지한 B2B 클라이언트를 위한 구현 작업을 해본 적이 있다면, 그 느낌을 잘 알 것입니다.
개발 단계는 순조롭습니다. 500개의 아이템이 들어 있는 CSV로 제품 import 로직을 테스트합니다. 빠르고, 반응이 좋으며, 마법처럼 잘 동작합니다. 그런데 UAT(또는 더 나쁜 상황인 Production)가 시작됩니다. 클라이언트가 실제 마스터‑데이터 파일—예를 들어 50 000, 100 000, 혹은 250 000 SKU—을 넘겨줍니다. Import 버튼을 누르고… 침묵이 찾아옵니다.
- 로그가 더 이상 출력되지 않습니다.
- CPU 사용량이 100 %까지 급등합니다.
- UI가 멈춥니다.
- 결국
java.lang.OutOfMemoryError혹은 트랜잭션 타임아웃이라는 두려운 오류가 발생합니다.
우리는 Nirvana Lab에서 이 상황을 셀 수 없을 만큼 많이 목격했습니다. 현실은 대량 제품 import가 엔터프라이즈 eCommerce에서 가장 과소평가된 성능 과제라는 점입니다.
이 글에서는 마케팅적인 과장은 빼고, 40분 이내에 100 k+ SKU를 안정적이고 반복 가능하며 크래시 없이 처리할 수 있는 정확한 고성능 Import 아키텍처를 여러분께 소개하겠습니다.
“편리함 함정”: OOTB 가져오기가 실패하는 이유
문제를 해결하기 전에, 기본 접근 방식이 왜 깨지는지 이해해야 합니다.
대부분의 개발자(저를 포함해, 초기에는) CSV를 순회하면서 각 행에 대해 CPDefinitionLocalService를 호출하는 간단한 서비스를 작성하는 것으로 시작합니다.
문제는 코드가 아니라 아키텍처적 맥락입니다.
1. 단일 트랜잭션
기본적으로 Liferay는 전체 요청을 하나의 트랜잭션으로 감싸려고 합니다. 항목이 50 k 개라면, 데이터베이스에 50 k 개의 커밋되지 않은 삽입을 롤백 세그먼트에 보관하도록 요구하는 셈입니다.
2. Hibernate 세션 팽창
Hibernate는 캐시를 좋아합니다. 순회하면서 생성되는 모든 CPDefinition 객체가 1차 캐시(힙 메모리)에 남아 있습니다. 트랜잭션이 닫히지 않기 때문에 가비지 컬렉션이 일어나지 않습니다.
3. 인덱싱 폭풍
이것이 조용한 살인자입니다. 제품을 추가할 때마다 Indexer가 깨어나 Elasticsearch/Solr를 업데이트합니다. 이를 100 000 번 동기식으로 수행하면 성능 자살이 됩니다.
결과: 작은 카탈로그에서는 잘 동작하지만, 엔터프라이즈 규모에 도달하자마자 급격히 성능이 떨어지는 시스템.
The Fix: Chunked, Async, and Deferred
고성능 B2B 카탈로그를 실행하기 위해, 우리는 기본 동기식 모델을 철거하고 “Chunk‑Commit‑Defer” 라는 패턴으로 교체했습니다.
아래는 우리 제조업 고객을 위해 배포한 프로덕션 급 아키텍처입니다.
The Architecture (Sequence Diagram)
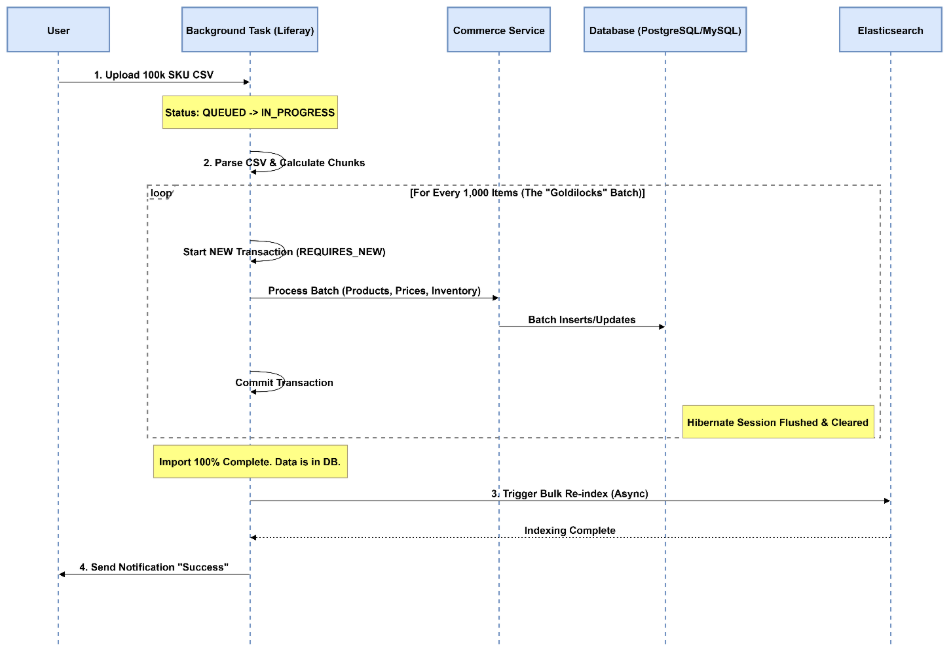
다이어그램은 흐름을 보여줍니다. “거대한 트랜잭션”을 한 입 크기의 조각으로 나누고, 무거운 작업(인덱싱)은 마지막에 수행한다는 점에 주목하세요.
Step‑by‑Step Implementation Guide
1. Get Off the Request Thread
메인 HTTP 스레드에서 대량 가져오기를 실행하지 마세요. 브라우저가 연결을 끊거나 로드 밸런서가 타임아웃되면 가져오기가 좀비 상태로 사라집니다.
우리는 Liferay의 BackgroundTaskExecutor 프레임워크를 사용합니다. 이 프레임워크는 클러스터 안전성을 제공하며(한 노드가 죽으면 다른 노드가 작업을 이어받음) 내장된 상태 보고 기능을 갖추고 있습니다.
@Component(
property = "background.task.executor.class.name=com.nirvanalab.commerce.task.ProductImportTaskExecutor",
service = BackgroundTaskExecutor.class
)
public class ProductImportTaskExecutor extends BaseBackgroundTaskExecutor {
// Implementation logic here...
}2. The “Goldilocks” Chunking Strategy
전체 리스트를 한 번에 처리하지 않고 조각으로 나눕니다.
Liferay DXP 7.4에서 광범위한 벤치마킹을 수행한 결과, 500 – 1 000개의 제품을 한 배치로 처리하는 것이 최적임을 발견했습니다.
| Batch size | Effect |
|---|---|
| ** 5 000** | Hibernate dirty‑checking이 기하급수적으로 느려짐 |
// The "Outer Loop" inside your Background Task
public void executeImport(List allRows) {
int batchSize = 1_000;
for (int i = 0; i batch = allRows.subList(i, end);
// This is where the magic happens
_batchService.processBatchInNewTransaction(batch);
// Help the Garbage Collector
batch.clear();
}
}Note: The Batch Engine is the preferred modern alternative for large‑scale imports.
3. Transaction Isolation (The Secret Sauce)
각 배치는 즉시 데이터베이스에 커밋되어야 합니다. 단순히 메서드를 호출하면 상위 트랜잭션을 상속받을 수 있습니다. Propagation.REQUIRES_NEW를 사용해 새로운 물리적 트랜잭션을 강제하십시오.
@Transactional(propagation = Propagation.REQUIRES_NEW)
public void processBatchInNewTransaction(List batch) {
for (ProductRow row : batch) {
// Create Product, set Price, set Inventory …
}
// When this method exits, the DB commits and Hibernate flushes.
// Memory is released.
}4. Defer the Indexing
100 k개의 제품을 하나씩 인덱싱하려고 하면 가져오기에 5시간이 걸립니다.
가져오는 동안 자동 인덱싱 트리거를 비활성화합니다(IndexerWriterHelper 사용 또는 모델‑별 인덱싱을 지연/배치 모드로 설정). 데이터는 “다크”(검색 불가) 상태로 데이터베이스에 저장됩니다. 루프가 끝난 뒤에 수동으로 최적화된 대량 재인덱싱을 트리거합니다.
// Run this ONLY after the loop finishes
Indexer indexer = IndexerRegistryUtil.getIndexer(CPDefinition.class);
indexer.reindex(new String[] { "companyId" }); // Example – adapt to your scope요약
| 단계 | 수행 내용 |
|---|---|
| 1 | 가져오기를 백그라운드 작업으로 오프로드합니다. |
| 2 | CSV를 500‑1 000행 청크로 나눕니다. |
| 3 | 각 청크를 자체 REQUIRES_NEW 트랜잭션으로 감쌉니다. |
| 4 | 행당 인덱싱을 비활성화하고, 모든 청크가 완료된 후 일괄 재인덱싱을 수행합니다. |
이 Chunk‑Commit‑Defer 패턴을 따르면 수십만 개의 SKU를 Liferay Commerce 7.4에 OOM 오류, 타임아웃 또는 UI 정지 없이 안정적으로 가져올 수 있습니다.
가져오기를 즐기세요!
etIndexer(CPDefinition.class);
indexer.reindex(CPDefinition.class.getName(), companyId);결과: 전과 후
우리는 최근 Liferay Commerce를 사용하여 대형 자동차 부품 유통업체에 이 아키텍처를 배포했습니다. 차이는 밤과 낮처럼 확연했습니다.

문제 해결: 현장의 교훈
이 아키텍처를 사용하더라도 우리는 엣지 케이스에 부딪혔습니다. 다음 두 가지 주의점을 확인하세요:
-
데드락 피해자
청크를 병렬 스레드에서 실행하려고 하면 CPInstance 또는 Inventory 테이블에서 데이터베이스 데드락이 발생할 가능성이 높습니다.우리의 조언: 단일 스레드 순차 청크를 사용하세요. 충분히 빠르고 복잡성은 버그를 낳습니다.
-
미디어 함정
메타데이터와 같은 트랜잭션에서 고해상도 제품 이미지를 가져오려고 하지 마세요. 바이너리 처리 시 힙 메모리를 많이 사용합니다.우리의 조언: 먼저 Data Pass(SKU, 가격, 재고)를 실행하고, 그 다음 별도의 Media Pass를 실행하여 이미지를 첨부하세요.
최종 생각
Scaling Liferay Commerce isn’t about throwing more hardware at the problem. It’s about respecting the physics of the database and the JVM.
By breaking the monolith into chunks and controlling your transaction boundaries, you can turn a fragile import process into a robust, enterprise‑grade data pipeline.
Struggling with Liferay performance? At Nirvana Lab, we specialize in fixing the “unfixable” performance issues in high‑scale manufacturing and retail implementations.