Informatica의 Spark 기반 데이터 통합 플랫폼 내부: 매일 250K 엔터프라이즈 파이프라인 실행
Source: Salesforce Engineering
Engineering Energizers Q&A
우리의 Engineering Energizers Q&A 시리즈에서는 Salesforce 전역에서 혁신을 주도하는 엔지니어링 인재들을 조명합니다. 오늘은 Salesforce의 수석 소프트웨어 엔지니어링 디렉터 Shivangi Srivastava를 소개합니다. 그녀는 5,500개 이상의 기업 고객이 매일 약 250,000개의 작업을 관리하는 Informatica 플랫폼을 구동하는 분산 아키텍처인 Cloud Data Integration의 구축 과정을 상세히 설명합니다.
팀이 어떻게 Informatica 데이터 통합 프레임워크를 단일 노드 설정에서 Kubernetes 기반의 확장 가능한 Spark 환경으로 전환했으며, 수천 개의 활성 스트림에 대한 레거시 지원을 유지하고, 대규모 데이터 세트에 대한 처리 속도와 운영 비용을 안정화하기 위해 FinOps 논리를 활용했는지 알아보세요.
Cloud Data Integration (CDI) 구축과 관련된 팀의 미션은 무엇인가요?
우리는 하이브리드 및 멀티‑클라우드 환경 전반에 걸쳐 기업 데이터를 접근 가능하고 신뢰할 수 있게 만드는 것이 목표입니다. Cloud Data Integration은 시스템을 연결하고, 데이터 세트를 변환하며, 정보를 목적지로 이동시키는 엔진 역할을 함으로써 이 미션을 지원합니다.
기업은 SaaS 플랫폼부터 레거시 시스템까지 수백 개의 소스를 관리합니다. CDI는 이러한 환경에 필요한 커넥터를 제공하여 팀이 조직 전반에 걸쳐 데이터를 정제하고 재구성하는 파이프라인을 구축할 수 있게 합니다.
생산성은 우리에게 여전히 핵심 초점입니다. 우리는 CDI 모델 내에서 손으로 작성한 코드보다 그래픽 파이프라인을 우선시합니다. 엔지니어는 매핑을 정의하고 런타임 엔진이 오케스트레이션과 스케일링을 담당합니다. 이 접근 방식은 팀이 인프라를 관리하는 대신 통합을 설계하도록 해줍니다.
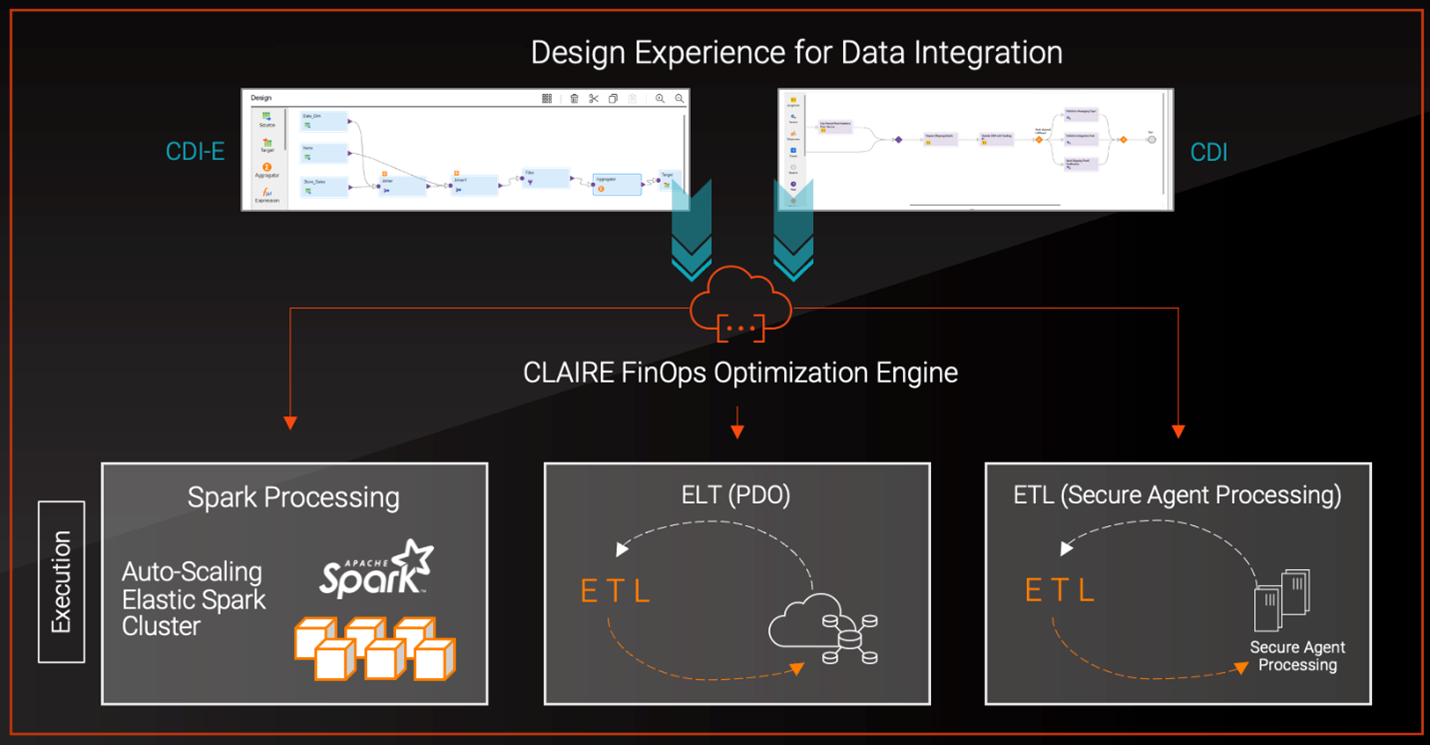
단일 노드 엔진에서 Kubernetes 기반의 분산 Spark 플랫폼으로 CDI가 진화하게 만든 제약 조건은 무엇인가요?
원래의 Informatica 통합 엔진은 데이터 처리의 다른 시대를 위해 설계되었습니다. 이는 기가바이트 수준의 데이터 세트에 적합한 단일 노드 시스템이었습니다.
현대 기업은 이제 거대한 규모로 운영됩니다. SaaS 플랫폼과 디지털 애플리케이션은 테라바이트·페타바이트에 달하는 볼륨을 생성합니다. 이러한 변화는 분산 아키텍처로의 전환을 요구했습니다.
하위 호환성이 전환 과정에서 가장 큰 제약이었습니다. 이미 수천 개의 프로덕션 파이프라인이 플랫폼에 존재했기 때문에 사용자가 이를 모두 재구축하도록 요구할 수 없었습니다. 우리는 파이프라인 설계에 사용되는 논리적 추상화 레이어를 유지함으로써 이를 해결했습니다. 엔지니어는 여전히 그래픽 매핑을 만들지만, 런타임은 이제 이러한 매핑을 분산 Spark 실행 계획으로 변환합니다.
오픈소스 Spark만으로는 라인리지 추적 및 깊은 커넥터 지원과 같은 필수 기업 기능이 부족했습니다. 이를 보완하기 위해 엔진을 **Spark++**로 확장했습니다. 이 버전은 Spark의 분산 처리 모델을 우리 변환 프레임워크와 거버넌스 기능과 결합합니다. 확장된 런타임은 엔지니어가 이미 사용하고 있는 논리적 추상화를 유지하면서도 CDI가 복잡한 통합 파이프라인을 대규모로 실행할 수 있게 합니다.
Informatica 스택의 많은 부분 아래에서 기본 엔진으로서 CDI의 아키텍처를 형성한 신뢰성 제약 조건은 무엇인가요?
CDI는 수많은 데이터 워크플로우의 백본 역할을 합니다. 통합 파이프라인은 분석 시스템과 운영 프로세스를 구동하므로 신뢰성은 핵심 설계 요구 사항으로 남아 있습니다.
안정성을 유지하기 위해 CDI는 세 가지 신뢰성 원칙에 집중합니다:
- 데이터 무결성 – 플랫폼은 행 수준에서 실행을 추적하여 문제 레코드를 파이프라인을 손상시키지 않고 격리할 수 있게 합니다.
- 테넌트 격리 – 컴퓨트 클러스터는 엄격한 VPC 경계 내에서 운영되며, 실행이 끝나면 임시 노드가 사라집니다.
Infrastructure resilience – 고가용성 서비스가 여러 가용 영역에 걸쳐 실행되어 지역적인 장애를 방지합니다.
이 시스템들은 CDI가 안정적인 데이터 통합 백본으로 기능하도록 합니다. 플랫폼은 99.9 % 제어 플레인 가용성 목표를 유지합니다.
엔터프라이즈 데이터 양이 기가바이트에서 테라바이트, 페타바이트로 확대될 때 어떤 확장성 제약이 나타났나요?
CDI를 확장하면 기업 데이터 양이 증가함에 따라 여러 도전 과제가 발생합니다. 클라우드 공급업체가 제공하는 다양한 컴퓨팅 및 스토리지 옵션 때문에 인프라 계획이 복잡해집니다.
엔터프라이즈 배포에서는 다음과 같은 세 가지 구체적인 확장 과제에 직면합니다:
- 인프라 복잡성 – 올바른 인스턴스 유형과 클러스터 구성을 선택하는 것이 여전히 어렵습니다.
- 동적 워크로드 – 파이프라인이 예측할 수 없는 급증과 유휴 기간을 경험합니다.
- 비용‑성능 트레이드오프 – 처리량을 높이면 인프라 비용이 급증하는 경우가 많습니다.
CDI는 FinOps 자동화를 통해 이러한 문제를 해결합니다. 사용자는 클러스터를 수동으로 구성하는 대신 비용 및 성능 목표를 정의합니다. 플랫폼은 워크로드를 분석하고 최적의 인프라 구성을 선택하여 Kubernetes‑관리 클러스터 전반에 걸쳐 컴퓨팅 리소스를 동적으로 확장합니다.
이 접근 방식은 대규모 데이터셋을 효율적으로 처리합니다. 엔지니어는 더 이상 인프라를 직접 관리하지 않아도 됩니다.
데이터 워크로드가 확장됨에 따라 인프라 비용과 성능의 균형을 맞출 때 어떤 엔지니어링 과제가 발생하나요?
하드웨어만 추가하여 분산 시스템을 확장하면 인프라 비용이 급격히 상승하는 경우가 많습니다. CDI는 인프라 최적화를 자동화하여 성능과 비용의 균형을 맞춥니다. 이 아키텍처는 클러스터 관리에 대한 수동 부담을 제거합니다.
FinOps 아키텍처를 구동하는 세 가지 핵심 시스템은 다음과 같습니다:
- Cluster Lifecycle Manager – 작업 수요를 예측하여 클러스터를 자동으로 시작하거나 종료합니다.
- Cluster Tuner – 적절한 클러스터 구성을 선택합니다(예: instan
(Note: the original content ends abruptly at “instan”. The text has been retained unchanged.)
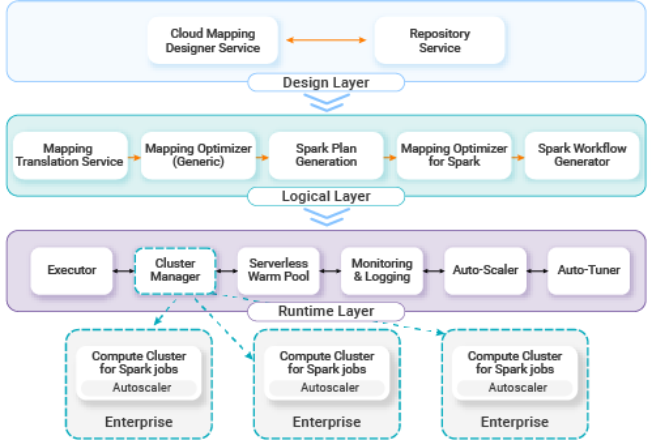
연속 데이터 통합 (CDI) 아키텍처 개요
핵심 구성 요소
- Data Plane – 데이터 변환 및 이동을 위한 Spark 작업을 실행합니다.
- Control Plane – 오케스트레이션, 스케줄링 및 메타데이터 관리를 처리합니다.
- Job Tuner – 과거 성능 데이터를 기반으로 Spark 런타임 매개변수(CPU, 메모리 등)를 조정합니다.
이 시스템은 인프라를 지속적으로 최적화합니다. 실제 배포에서는 이 아키텍처가 성능을 유지하면서 인프라 비용을 약 1.65배 감소시키는 것으로 나타났습니다.
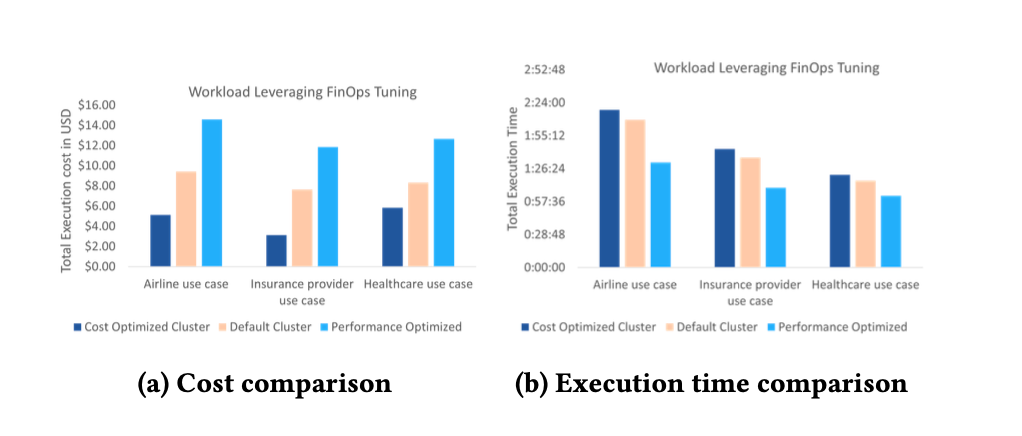
엔터프라이즈 규모의 확장 과제
수천 개 기업과 수십만 개 작업에 걸쳐 CDI를 운영하면 여러 과제가 발생합니다:
- Customer‑environment growth – 급속히 확대되는 테넌트 기반을 관리합니다.
- Job concurrency – 동시에 실행되는 다수의 작업을 처리합니다.
- Data throughput – 대량의 데이터 이동 및 처리를 지속합니다.
CDI는 현재 약 5,500개의 엔터프라이즈 고객을 지원하며, 이들은 일일 약 250,000개의 통합 작업을 실행합니다. 이 규모에서 플랫폼을 안정적으로 유지하는 두 가지 아키텍처 선택이 있습니다:
- Control‑plane separation – 오케스트레이션 및 스케줄링이 데이터‑처리 계층과 분리됩니다.
- Distributed execution – Spark 워크로드가 컨트롤 서비스와 독립적으로 실행됩니다.
이 설계는 컴퓨트 클러스터 급증 시에도 오케스트레이션 서비스가 응답성을 유지하도록 보장하며, 고급 스케줄링은 대규모 작업이 공유 자원을 독점하는 것을 방지합니다. 결과적으로 플랫폼이 확장됨에 따라 일관된 성능을 제공합니다.
자세히 알아보기
- 연결 유지 — 우리의 Talent Community에 참여하세요!
- 우리의 Technology and Product 팀을 탐색하여 어떻게 참여할 수 있는지 확인하세요.
백서