작동하는 모델을 만들기 전에 거대한 모델을 만들었다
Source: Dev.to
번역을 진행하려면, 위 링크에 있는 전체 텍스트(코드 블록 및 URL 제외)를 제공해 주시겠어요?
제공해 주시면 해당 내용을 한국어로 번역해 드리겠습니다.
10일 동안 첫 번째 대회 ML 모델을 만들었습니다
트랜스포머, 어텐션 풀링, 다중 입력 브랜치를 포함했습니다.
점수는 0.500.
The Competition
여름이 약 2주 정도 남은 시점에, 나는 처음으로 ML 대회에 도전하기로 결심했다. 나는 언제나 Kaggle 대회를 둘러보며 흥미를 느꼈지만—조금은 위압감도 있었다. 나는 완벽한 기회를 기다렸다. 쉽지만 지루하지 않은 대회를 원했다.
어느 순간, 기다리는 것이 의미 없다는 것을 깨달았다. 실패하게 된다면, 차라리 일찍 실패하는 것이 낫다.
그래서 과감히 뛰어들었다.
나는 BIRDCLEF+ 2026이라는 대회에 참여하기 시작했는데, 목표는 오디오 클립에 어떤 특정 동물/새 소리가 포함되어 있는지를 파악하고, 각 소리가 존재할 확률을 예측하는 모델을 만드는 것이었다. 모든 코드를 직접 작성하려고 하지 않고, 코딩에 AI 도움을 활용하면서 모델을 엔드‑투‑엔드로 완성하는 전체 워크플로우를 이해하고 코드에 익숙해지는 것을 목표로 했다.
Source: …
The Plan
이것은 내가 처음으로 실제 세계에서 다룬 머신러닝 문제였다.
핵심은 모델 자체를 만드는 것이 아니라 그 주변 작업이었다—힘든 데이터 전처리, 환경 불일치 디버깅, 방대한 코드 속에서 문제 찾기, 제한된 GPU 사용 가능성, 그리고 프로세스를 신뢰하는 것 등.
시작할 때는 이 점을 깨닫지 못했다. 나는 순진하게 핵심은 혁신적인 모델이라고 생각했다—시선을 끄는, 인상적인 무언가.
- 다중 입력 브랜치
- 트랜스포머
- CNN
- 어텐션 풀링
뭔가가 고급스럽게 들리면 바로 넣고 싶었다. 이것이 내 강점이 될 거라 생각했다. 곧 복잡한 신경망 아키텍처에 대해 배우는 것과 실제로 구현하는 것은 완전히 다른 일이라는 것을 깨달았다.
아래는 내가 처음 만들려고 시도한 모델이다:
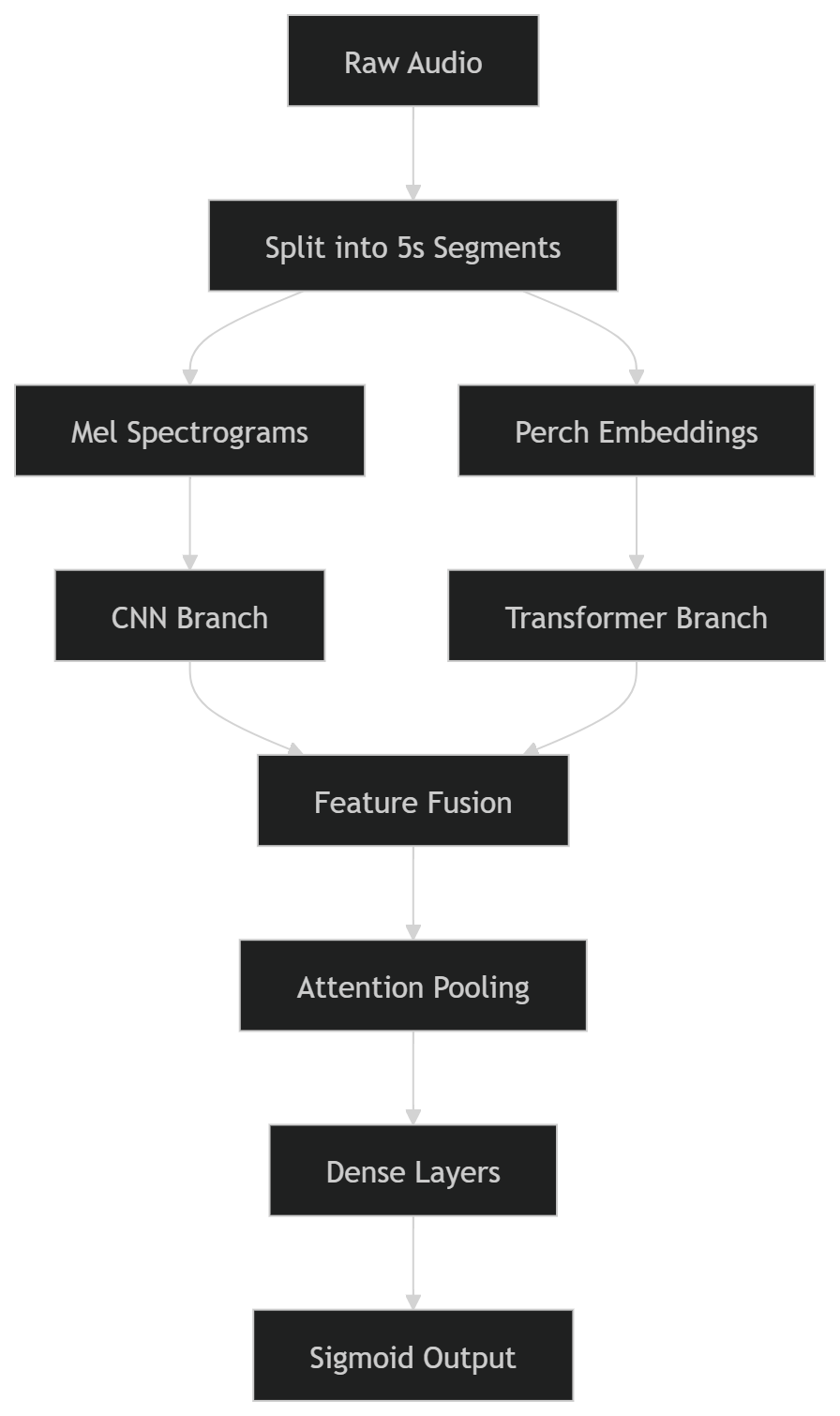
이를 위해 두 개의 학습 데이터셋을 5초 구간으로 나누고, 멜 스펙트로그램과 Perch 임베딩을 생성한 뒤, 기본 라벨과 보조 라벨에 정확히 맞추어야 했다.
예상보다 훨씬 복잡했다. XLA와 PyTorch 환경 간 호환성 문제, Kaggle 캐시 제한이 빠르게 차는 것, 그리고 여러 작은 하지만 짜증나는 버그 등 여러 이슈에 부딪혔다. 하루 이틀 걸릴 거라 생각했던 작업이 결국 일주일 전체가 걸렸다. 하나씩 문제를 해결하면서 파이프라인을 가동시켰다.
그 다음 모델 자체를 설정하는 것은 비교적 간단했다. 전처리된 데이터를 로드하고 학습을 시작했다. 여기서 주요 문제는 CPU RAM이 부족해지는 것이었다. 데이터 로딩은 CPU에서, 학습은 GPU에서 이루어졌기 때문이다. 각 세션은 약 1.5–2시간 정도 실행된 뒤 충돌했으므로, 50 배치마다 진행 상황을 저장하는 체크포인트를 구현했다.
전체적으로 여러 세션에 걸쳐 노트북을 약 12–15시간 정도 실행했으며, 겨우 한 에포크 정도의 학습을 마칠 수 있었다.
0.500 순간
그런 다음 추론 노트북을 설정하고 대회에 제출했습니다. 제출 과정이 어떻게 작동하는지 드디어 이해했습니다. 겨우 두 번 시도만에 성공적으로 실행되었습니다.
점수를 확인하려고 아래로 스크롤했습니다.
0.500

10일 넘게 작업한 뒤, 그 숫자는 예상보다 더 큰 충격을 주었습니다.
그리고 나는 깨달았습니다—내가 복잡함에 스스로를 가두고 있었다는 것을. 1 000 줄이 넘는 코드 어딘가에 버그가 있었지만, 그것을 찾을 방법이 없었습니다.
내가 해야 했던 일
단순함부터 시작했어야 했습니다: 하나의 모델, 하나의 파이프라인, 실제로 디버깅할 수 있는 하나의 요소. 예를 들면 다음과 같습니다:
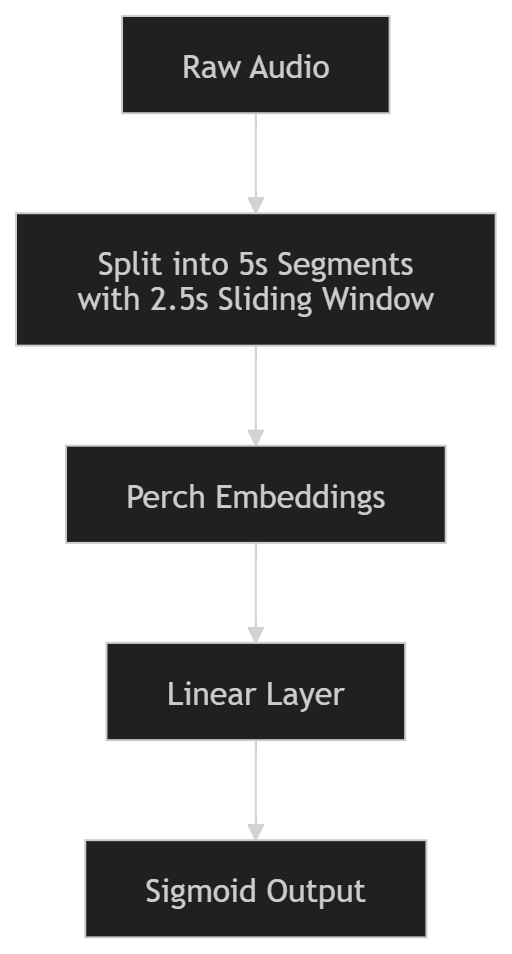
성능 향상의 핵심은 전체 모델을 전면 개편하는 것이 아니라, 높은 ROI를 제공하는 간단한 변화에 있습니다.
데이터셋을 5초 단위로 나눌 때, 겹치지 않는 구간(0–5 s, 5–10 s, …)을 사용하는 대신 2.5 s 슬라이딩 윈도우(0–5 s, 2.5–7.5 s, …)를 사용할 수 있었습니다.
이 한 가지만으로도 데이터셋 규모를 크게 늘릴 수 있었을 것입니다. 이를 < 3–4 일 안에 구현할 수 있었고, 이후 전처리 과정이 자연스럽게 설계되어 있었기 때문에 나중에 어텐션‑풀링 레이어를 추가하더라도 아무것도 깨지 않을 것입니다.
교훈
결과가 그다지 좋지는 않았지만, 이번 시도에서 많은 것을 배웠습니다. 이제 전체 대회 파이프라인을 이해하게 되었고, 환경 문제, 타임아웃, GPU 제한을 다루는 데 더 자신감이 생겼습니다.
놓친 점 하나: 저는 2주밖에 없었기 때문에 대회 토론에 참여하거나 팀을 구성하지 않았습니다. 커뮤니티에서 배울 것이 많습니다—다른 사람들이 이미 겪은 문제 패턴을 파악하면 많은 시간을 절약할 수 있습니다.
결론
내 첫 번째 Kaggle 대회는 풍부한 경험이었으며, 실패를 통해 배울 것이 많았다.
복잡함은 시작점이 아니다.
디버그.
Gable code beats sophisticated code.
Iteration speed matters.
Complex models aren’t bad.
But you don’t start with a monster.
You grow into one.
If you’ve ever overengineered something like this, I’d love to hear your experience!