LLM을 대량의 데이터에서 작동시키는 방법
Source: Dev.to
위에 제공된 Source 링크만 포함되어 있고 번역할 본문 내용이 없습니다. 번역을 원하는 텍스트(본문)를 제공해 주시면 한국어로 번역해 드리겠습니다.
텍스트‑투‑SQL vs. LLM‑기반 접근법
텍스트‑투‑SQL 도구는 대규모 데이터셋에 인텔리전스를 적용하는 시장을 오랫동안 장악해 왔습니다.
대형 언어 모델(LLM)의 부상으로, 다음과 같은 다양한 새로운 기법이 포함되면서 환경이 변했습니다:
- Retrieval‑Augmented Generation (RAG)
- 코딩/SQL 에이전트
- …그 외 하이브리드 솔루션
핵심 과제
LLM은 원시 데이터를 직접 볼 수 없습니다. 대신, 추상화된 뷰만을 받게 됩니다. 예를 들어:
- 요약
- 샘플 행
- 스키마 설명
- 다른 시스템이 생성한 부분 슬라이스
많은 행을 처리해야 할 때, 모든 데이터를 LLM에 전달하는 것은 현실적이지 않습니다.
Datatune으로 해결하는 방법
Datatune은 방대한 데이터 테이블과 LLM 사이의 격차를 메우는 확장 가능한 방식을 제공합니다:
- 청크 및 샘플링 – 데이터셋을 관리 가능한 조각으로 나누거나 대표 샘플을 선택합니다.
- 스키마‑인식 프롬프트 – 간결한 스키마 정보를 포함시켜 LLM이 컬럼 의미를 이해하도록 합니다.
- 반복적 검색 – 모델이 추가 컨텍스트를 요청할 때만 RAG‑스타일 루프를 사용해 추가 행을 가져옵니다.
- 결과 집계 – LLM의 부분 출력을 결합해 최종적인 일관된 답변이나 SQL 쿼리를 만듭니다.
빠른 시작
# Install Datatune
pip install datatune
# Example: Generate a query for a large table
datatune generate \
--table my_large_table.csv \
--prompt "Find the top 5 customers by total purchase amount" \
--max-chunk-size 5000위 명령은:
- 테이블을 5 000행씩 청크로 로드합니다.
- 스키마와 샘플 데이터를 LLM에 전달합니다.
- 전체 데이터셋을 고려한 실행 가능한 SQL 문(또는 파이썬 코드)을 반환합니다.
🎵 Datatune


![]()

행‑레벨 인텔리전스를 통한 확장 가능한 데이터 변환.
Datatune은 단순한 Text‑to‑SQL 도구가 아닙니다. Datatune을 사용하면 LLM과 에이전트가 데이터에 완전하고 프로그래밍 방식으로 접근할 수 있으며, 모든 레코드에 의미론적 인텔리전스를 적용할 수 있습니다.
어떻게 작동하나요
설치
pip install datatune빠른 시작 (Python API)
import datatune as dt
from datatune.llm.llm import OpenAI
import dask.dataframe as dd
llm = OpenAI(model_name="gpt-3.5-turbo")
df = dd.read_csv("products.csv")
# Extract categories using natural language
mapped = dt.map(
prompt="Extract categories from the description and name of product.",
output_fields=["Category", "Subcategory"],
input_fields=["Description", "Name"]
)(llm, df)
# Filter with simple criteria
filtered = dt.filter(
prompt="Keep only electronics products",
input_fields=["Name"]
)(llm, mapped)컨텍스트 길이 문제
LLM은 컨텍스트‑길이 능력 측면에서 점점 커지고 있습니다. 낙관적인 100 M‑토큰 윈도우조차도 일반적인 기업 데이터셋은 단일 요청으로 처리할 수 있는 양을 금방 초과합니다.
예시: 중간 규모 기업
| 항목 | 수량 |
|---|---|
| 트랜잭션 테이블의 행 수 | 10 000 000 |
| 행당 열 수 | 20 |
| 열당 평균 문자 수 | 50 |
10 000 000 rows × 20 columns × 50 characters
= 10 000 000 000 characters
≈ 2.5 billion tokens (≈ 4 characters per token)100 M‑token 컨텍스트 윈도우는 그 데이터의 1/25만 담을 수 있습니다.
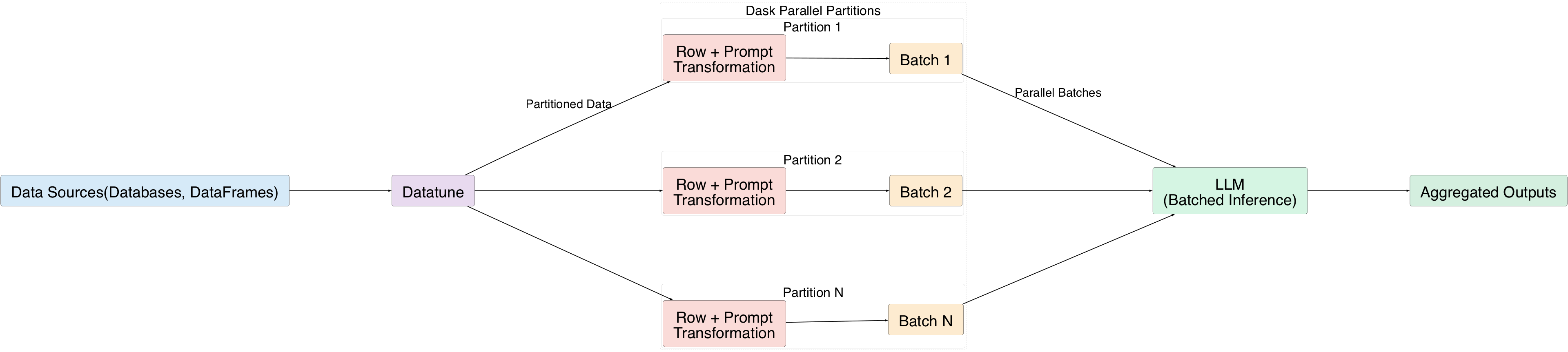
대규모 데이터 처리 해결: Datatune
Datatune은 LLM이 대규모 데이터셋에 완전 접근할 수 있도록 배치 단위로 행을 처리합니다:
- 각 행은 자연어 프롬프트를 사용해 변환됩니다.
- 행들을 배치로 묶어 LLM에 전송합니다.
- Dask의 병렬 실행이 데이터를 파티션으로 나누어 여러 배치를 동시에 처리할 수 있게 합니다.
Understanding Data‑Transformation Operations
Datatune provides four first‑order primitives (also called primitives):
| Primitive | Description |
|---|---|
| MAP | 각 행을 새로운 필드로 변환합니다. |
| FILTER | 조건을 만족하는 행을 유지합니다. |
| EXPAND | 기존 행에서 파생된 새로운 행을 추가합니다. |
| REDUCE | 행을 집계하여 요약 통계량을 생성합니다. |
All primitives can be driven by natural‑language prompts.
MAP Example
mapped = dt.map(
prompt="Extract categories from the description and name of the product.",
output_fields=["Category", "Subcategory"],
input_fields=["Description", "Name"]
)(llm, df)Chaining MAP and FILTER
# 1️⃣ Extract sentiment and topics from each review (MAP)
mapped = dt.map(
prompt="Classify the sentiment and extract key topics from the review text.",
input_fields=["review_text"],
output_fields=["sentiment", "topics"]
)(llm, df)
# 2️⃣ Keep only negative reviews (FILTER)
filtered = dt.filter(
prompt="Keep only rows where sentiment is negative."
)(llm, mapped)Datatune 에이전트
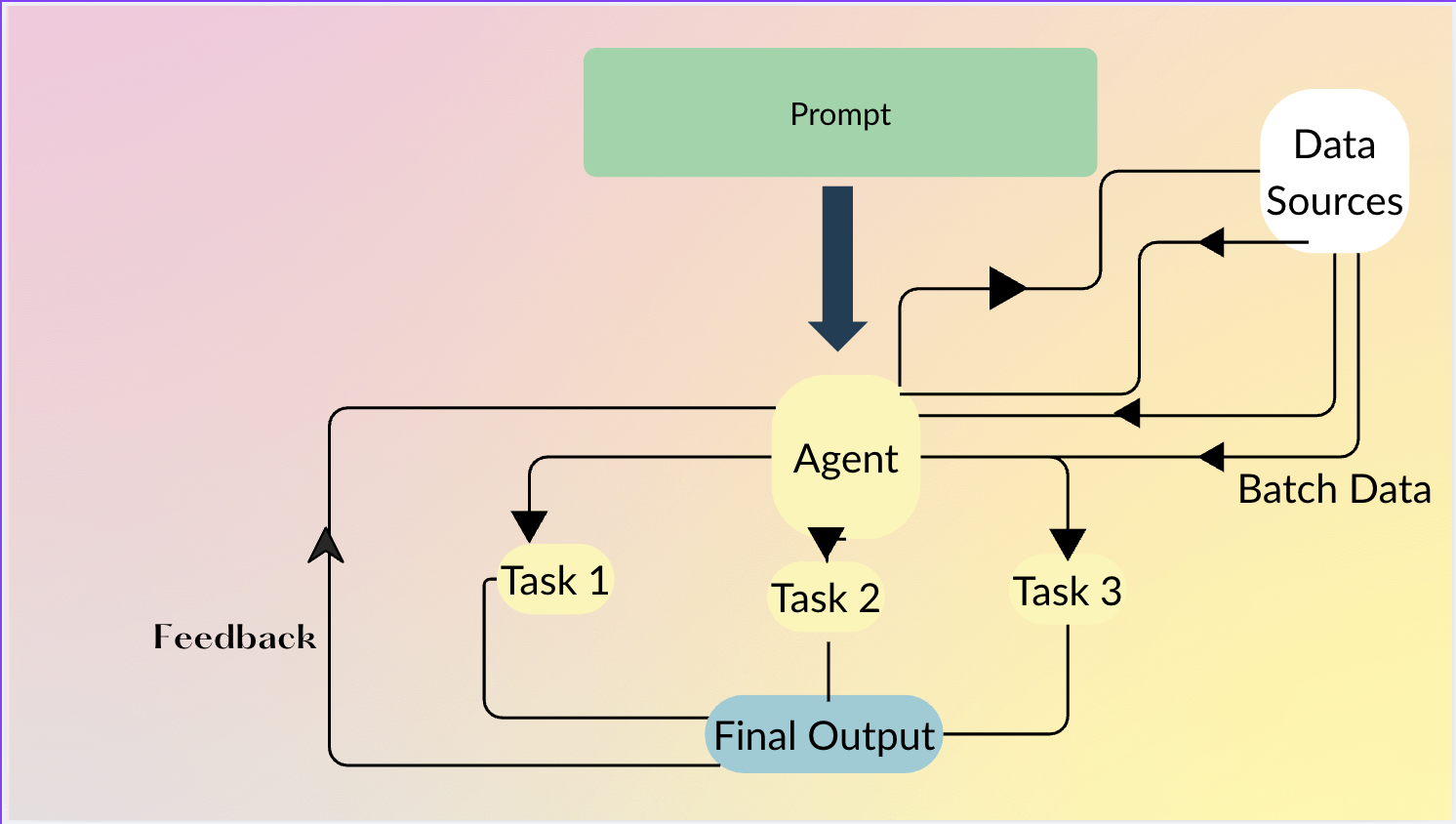
에이전트를 사용하면 사용자는 무엇을 원하는지 자연어로 설명할 수 있고, 에이전트는 어떻게 기본 연산(MAP, FILTER 등)을 연결할지 결정합니다. 행 수준의 지능이 필요하지 않을 때는 파이썬 코드를 직접 생성하기도 합니다.
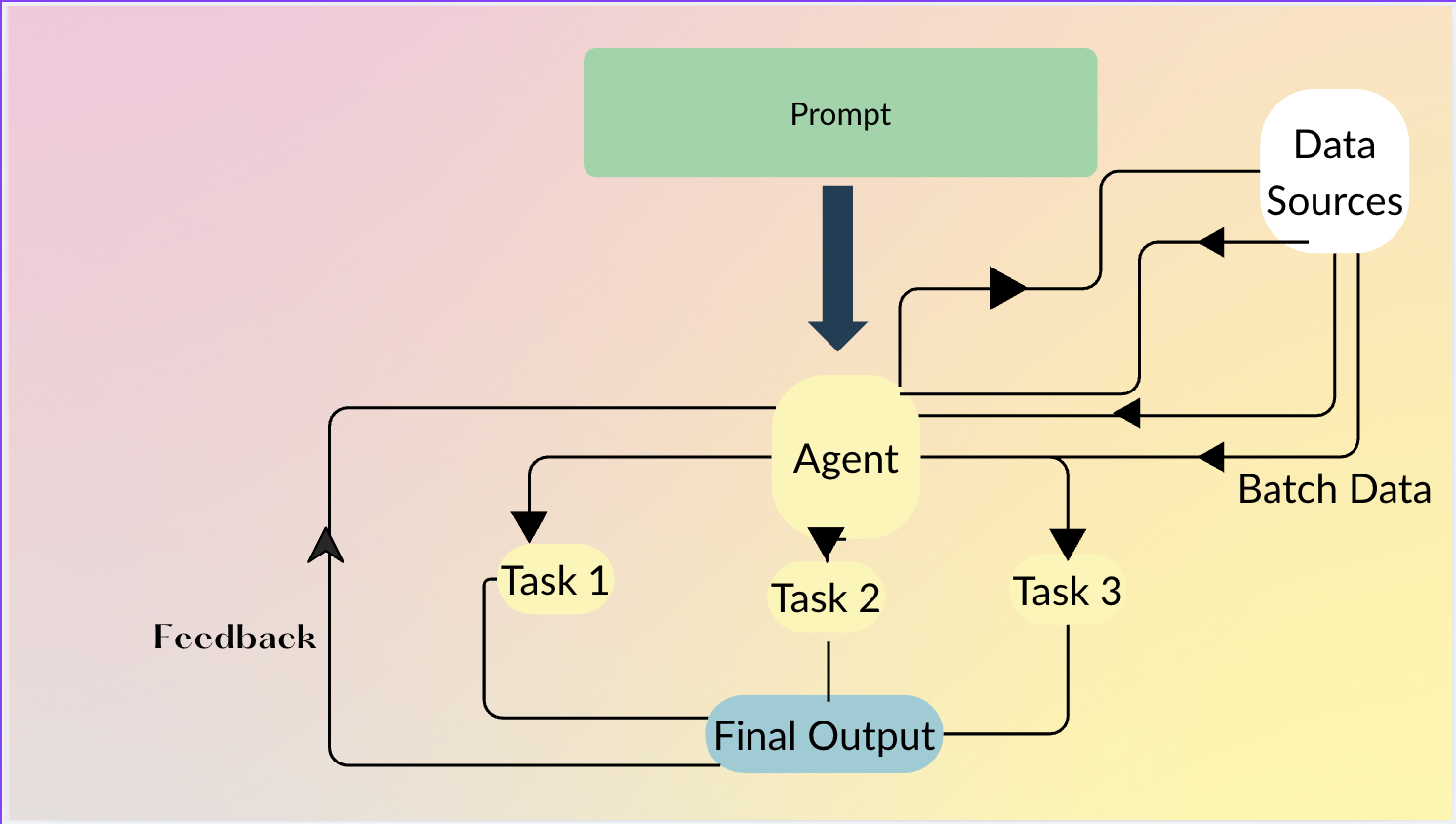
에이전트 예시
df = agent.do(
"""
From product name and description, extract Category and Subcategory.
Then keep only products that belong to the Electronics category
and have a price greater than 100.
""",
df
)에이전트는 자동으로 다음을 수행합니다:
- 제품 이름/설명 →
Category,Subcategory매핑. Category == "Electronics"그리고price > 100인 행을 필터링.
데이터 소스
- DataFrames – Pandas, Dask, Polars 등.
- Databases – Ibis 통합을 통해 (DuckDB, PostgreSQL, MySQL, …).
기여
Datatune은 오픈‑소스이며, 여러분의 기여를 환영합니다!
🔗 Repository: https://github.com/vitalops/datatune