제가 DynamoDB TTL와 AWS Lambda를 사용해 제로‑웨이스트, 이벤트 기반 분석 파이프라인을 설계한 방법
발행: (2025년 12월 11일 오전 11:14 GMT+9)
4 분 소요
원문: Dev.to
Source: Dev.to
Problem Statement
Barx가 생성하는 데이터를 가져와 바버샵에 전달할 때가 되었습니다. 처음에는 매주 월요일 오전 3시 UTC에 실행되는 크론 작업을 만들었습니다. Lambda가 트리거되면 DynamoDB에서 모든 바버샵을 검색하고 각각에 대해 분석 계산을 시작합니다.
Issues with the cron‑based approach
- 전체 DynamoDB 테이블을 스캔하는 것은 리소스를 많이 소모하고 비용이 많이 들 수 있습니다.
- 단일 Lambda 함수가 무거운 작업을 처리하므로 성능 및 확장성에 영향을 줄 수 있습니다.
- 매주 월요일마다 프로세스는 활동 상태와 관계없이 모든 바버샵을 가져오려고 시도합니다.
- 분석 계산이 지난 주에 활동이 없었던 바버샵까지 모두 수행되어 불필요한 리소스가 소비됩니다.
목표는 지난 주에 활동이 있었던 바버샵에만 리소스를 사용하고, 지난 7, 30, 60, 90 일에 대한 분석을 다시 계산하는 것입니다.
Architecture Proposal
이를 고민하면서 다음과 같은 아키텍처를 설계했습니다:
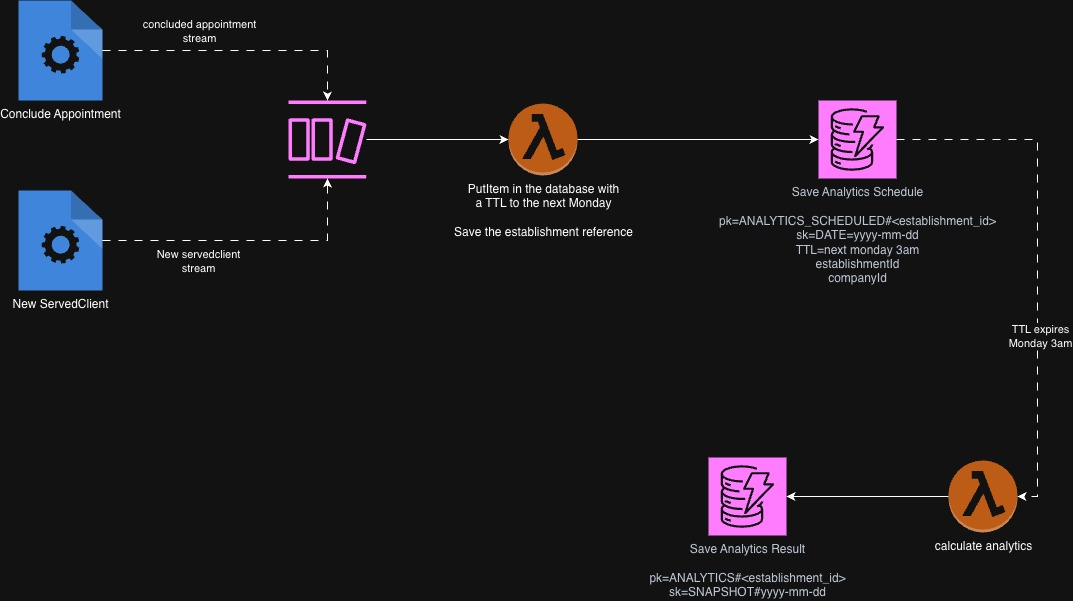
단순해 보이지만, 활동이 있었던 바버샵에만 작업을 예약할 수 있습니다. 활동이 있었던 바버샵에 대한 레코드를 DynamoDB에 생성하고, 해당 레코드는 다음 월요일 오전 3시 UTC에 만료됩니다. TTL 규칙에 의해 레코드가 삭제되면 또 다른 Lambda가 트리거되어 해당 바버샵의 데이터를 전용 Lambda에 전달해 분석을 수행합니다.
이 접근 방식은 데이터를 생성하고 있는 사용자에게만 리소스를 사용하고, 유휴 사용자에게는 리소스를 사용하지 않도록 보장합니다.
Benefits
- 최근에 활동이 있었던 바버샵에 대해서만 분석 계산이 수행되어 리소스 사용이 최적화됩니다.
- DynamoDB에 예약된 레코드는 TTL을 통해 자동으로 정리되므로 수동 유지 관리가 줄어듭니다.
- 아키텍처가 효율적으로 확장되어 추가 복잡성 없이도 사용자 수에 관계없이 지원할 수 있습니다.
Concerns
- 많은 레코드가 동시에 만료되면 다수의 Lambda가 동시에 트리거되어 동시 실행량 급증이 발생할 수 있습니다. (DynamoDB Stream 배치 크기와 병렬화 계수를 조정하면 완화할 수 있습니다.)
- DynamoDB Streams 서비스의 부하에 따라 예약된 만료 시간과 실제 Lambda 트리거 사이에 지연이 발생할 수 있습니다. (분석이 실시간일 필요가 없기 때문에 내 사용 사례에서는 허용됩니다.)
이 아이디어를 공유하여 커뮤니티의 피드백을 받고자 합니다. 개선 방안이나 대안적인 접근 방법이 있다면 댓글로 알려 주세요!