구글 신형 Gemma 4 12B 모델, 16GB RAM 노트북에서도 실행 가능
발행: (2026년 6월 4일 AM 04:10 GMT+9)
3 분 소요
원문: Ars Technica
출처: Ars Technica
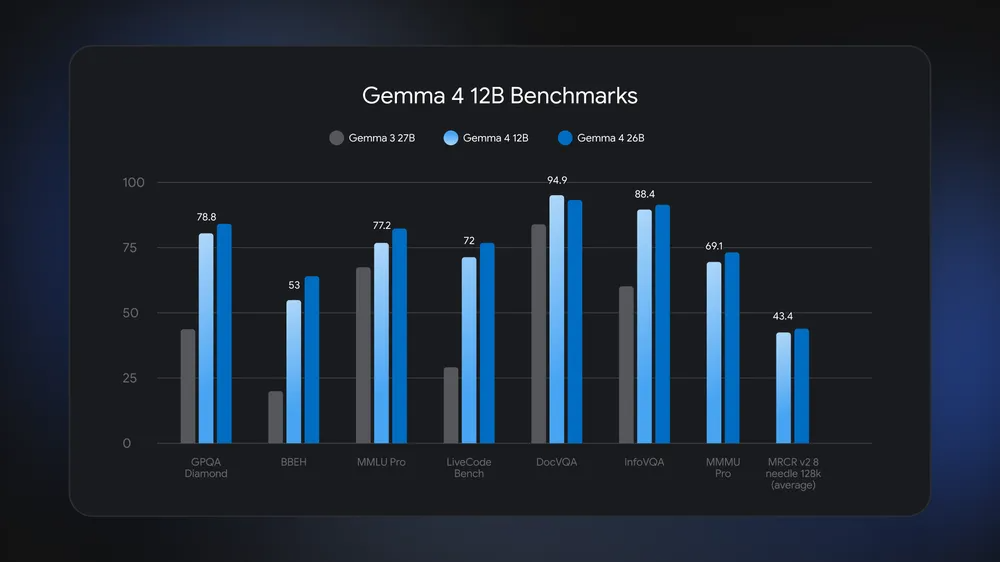
모델 개요
구글에 따르면 새로운 Gemma 4 12B 모델은 이전에 더 큰 Gemma 변형이 필요했던 복잡한 다단계 추론 및 에이전시 워크플로를 수행할 수 있다고 합니다. 파라미터가 120억 개에 불과하지만, 260억 파라미터 버전에 근접하는 성능을 보여줍니다.
다중 토큰 예측 (MTP)
Gemma 4 12B에는 새롭게 고안된 Multi‑Token Prediction (MTP) drafters가 포함되어 있어, 사용되지 않은 처리 사이클을 활용해 가능한 미래 토큰을 계산합니다. 이를 통해 속도와 효율성이 크게 향상됩니다. 다른 Gemma 4 모델에도 선택적 MTP 버전이 존재하지만, 12B 변형은 처음부터 MTP가 활성화된 상태로 제공됩니다.
다중모달 효율성
Gemma 4 시리즈는 본래 다중모달을 지원해 텍스트, 오디오, 이미지 등을 입력으로 받을 수 있습니다. 대부분의 생성 AI 모델은 비텍스트 입력을 위해 별도의 인코더를 사용해 지연 시간과 메모리 오버헤드를 증가시킵니다.
Gemma 4 12B는 이를 다음과 같이 간소화합니다:
- Vision – 위치 임베딩을 포함한 단일 행렬 곱셈 임베딩 모듈로, 이미지 데이터를 공간 인식을 유지한 채 LLM에 직접 전달할 수 있어 무거운 중간 인코더를 없앱니다.
- Audio – 별도의 인코더가 없으며, 원시 오디오 신호를 텍스트 토큰과 동일한 벡터 공간으로 투사합니다.
사용 가능 여부
다음과 같은 도구를 통해 Gemma 4 12B를 다운로드 없이 체험할 수 있습니다:
모델 가중치(≈ 18 GB)는 다음 사이트에서 로컬 다운로드가 가능합니다:
16 GB RAM만 있으면 일반적인 노트북에서도 모델을 실행할 수 있습니다.