GCC vs Clang: 같은 명령어, 다른 성능 (AGU Insight)
발행: (2026년 3월 28일 오전 03:01 GMT+9)
3 분 소요
원문: Dev.to
Source: Dev.to
Introduction
GCC와 Clang 벤치마크를 실행하면서 흥미로운 점을 발견했습니다.
- 같은 코드. 같은 머신.
- 두 루프 모두 스칼라(벡터화 안 됨).
그럼에도 불구하고 GCC가 일관되게 더 적은 CPU 사이클을 사용했습니다.
처음엔 이해가 되지 않았습니다. 두 컴파일러가
- 거의 같은 명령어를 실행하고
- 벡터화되지 않았다면
왜 성능 차이가 날까요?
The Missing Piece: It’s Not Just Instructions
대부분의 사람들은 다음에만 집중합니다.
- 명령어 수
- 벡터화
하지만 이번 경우는 전체 이야기가 아닙니다.
실제로 더 중요한 것은
- 주소 연산이 어떻게 구성되는가
- 명령어가 어떻게 스케줄링되는가
- 레이턴시가 얼마나 잘 숨겨지는가
다음이 데이터입니다:
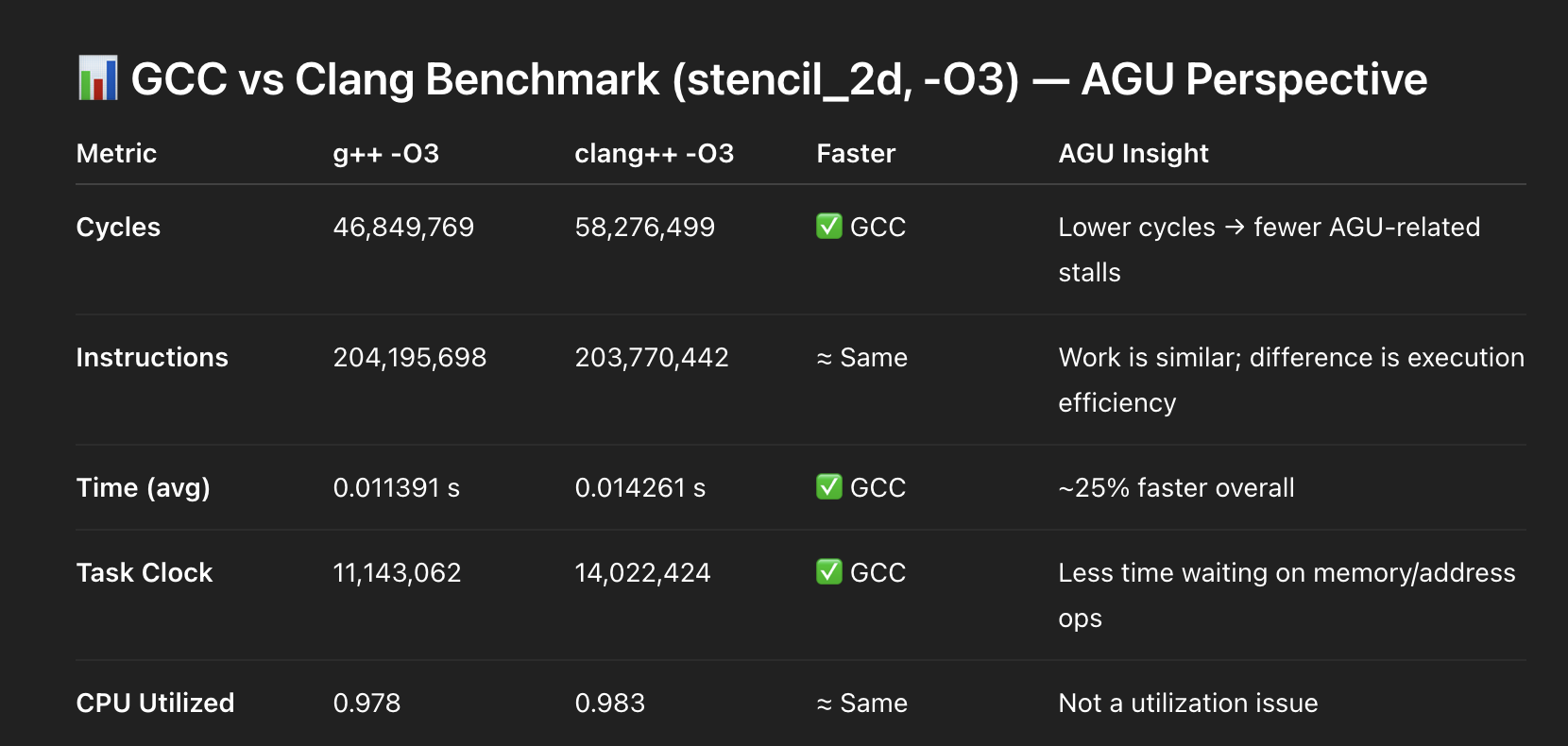
AGU Pressure (Address Generation Units)
x86 CPU에서는 메모리 명령이 AGU(Address Generation Units)에 의존합니다.
다음과 같은 복잡한 주소 지정 패턴은
base + index * scale + offset👉 AGU 압력을 증가시킵니다.
반면에 다음과 같은 단순한 패턴은
pointer++👉 더 저렴하고 CPU가 효율적으로 실행하기 쉽습니다.
What I Observed
GCC
- 더 단순한 주소 지정 패턴을 생성
- AGU 경쟁을 감소
- 실행을 보다 일관되게 유지
Clang
- 더 높은 AGU 압력 표시
- 더 많은 스톨
- (이번 경우) 덜 효율적인 스케줄링
Key Takeaway
중요한 것은 어떤 명령어가 존재하느냐가 아니라 컴파일러가 CPU 파이프라인에 얼마나 효율적으로 명령을 공급하느냐입니다.
같은 명령어 수 ≠ 같은 성능.
Why This Matters
긴밀한 루프에서는 다음 요소들이 벡터화만큼(혹은 그보다) 중요할 수 있습니다.
- AGU 압력
- 주소 지정 패턴
- 명령어 스케줄링
Want to Dive Deeper?
Discussion
비슷한 어셈블리와 동일한 명령어 수에도 불구하고 성능 차이가 크게 나는 경우를 보신 적 있나요? 여러분의 관찰을 듣고 싶습니다.