ChatGPT에서 Gemini까지: Odoo용 GDPR 준수 CV 파서 구축 방법
Source: Dev.to


Source:
배경
몇 년 전, 프랑스의 한 사업주가 워크‑스테디 프로그램(프랑스에서는 Alternance 라고 함)의 디지털화를 도와달라고 연락했습니다. 이 회사는 Work‑Study Programs(프랑스어로 Alternance)에 참여할 사람들을 모집하는 일을 전문으로 합니다.
Alternance는 학생이 학교와 직장을 병행하는 시스템입니다. 학생에게 매력적인 이유는 다음과 같습니다:
- 학비를 전액 면제받는다
- 실제 업무 경험을 쌓는다
- 프랑스 최저임금(SMIC) 수준의 급여를 받는다
이 에이전시는 전문가 중개인 역할을 하며, 단일 당사자에게는 감당하기 어려운 과정을 처리합니다. 그들의 워크플로는 다음과 같습니다:
- 후보자 찾기 – 워크‑스테디 프로그램에 관심 있는 학생이나 구직자를 발굴합니다.
- 스크리닝 – 지원자가 정부가 정한 공식 기준(연령, 학력 등)을 충족하는지 인터뷰를 통해 확인합니다.
- 고용주와 매칭 – 견습생을 필요로 하는 기업을 찾아 최적의 프로필을 전달합니다.
- 서류 처리 – 복잡한 행정 절차를 관리하고, 기업이 채용을 결정하면 계약서에 서명하도록 합니다.
요컨대, 이들은 견습생과 고용주 사이의 격차를 메워 모두에게 더 원활한 여정을 제공합니다.
병목 현상: 수동 데이터 입력
우리와 연락하기 전, 팀은 노트북과 스프레드시트를 사용했습니다. 우리는 **Odoo Community Recruitment 모듈**을 기반으로 완전한 채용 파이프라인을 구축하고, 그들의 특정 워크플로에 맞게 커스텀 모듈을 확장했습니다.
새 시스템을 통해 회사는 모든 것을 한 곳에서 추적할 수 있게 되었습니다:
- 지원자 및 기업 데이터베이스
- 채용 단계
- 약속 일정
- 자동 메일/문자(SMS) 알림
- 캘린더 연동
- 디지털 계약서 서명
솔루션은 성공적이었지만, 한 가지 큰 문제점이 남아 있었습니다: 데이터 입력. 채용 담당자는 여전히 프로필을 찾아 파이프라인에 수동으로 입력해야만 작업을 시작할 수 있었습니다. 사업주는 좌절했습니다—채용 담당자들이 인재 발굴 대신 수동 입력에 몇 시간을 소비하고 있었습니다.
우리는 이를 AI를 활용해 자동화하기로 결정했습니다.
자동화 워크플로우 설계
우리의 첫 번째 아이디어는 서드파티가 Odoo에 직접 데이터를 보낼 수 있도록 API를 구축하는 것이었지만, 아직 소스가 준비되지 않았습니다. 대신, 모든 지원자 이력서를 이메일(PDF 첨부 파일이 있는 간단한 메시지)로 받기로 합의했습니다. 전용 메일함을 설정한 후, 다음과 같은 워크플로우를 설계했습니다:
- 이메일 읽기 – 이메일 제공자에 로그인하여 읽지 않은 메시지를 가져옵니다.
- 첨부 파일 추출 – 첨부된 이력서(PDF)를 다운로드합니다.
- OCR 처리 – 광학 문자 인식을 수행하여 원시 텍스트를 추출합니다.
- AI 파싱 – LLM을 사용해 원시 텍스트를 구조화된 JSON 형식으로 변환합니다.
- Odoo 연동 – Odoo XML‑RPC를 이용해 채용 모듈에 레코드를 생성하고, 원본 PDF를 참고용으로 첨부합니다.
- 할당 – 자동으로 리드를 사용 가능한 채용 담당자에게 할당합니다.

Iteration 1 – Tesseract + ChatGPT
첫 번째 솔루션은 OCR을 위해 Tesseract 를, LLM 로직을 위해 ChatGPT API 를 결합한 마이크로서비스였습니다.

몇 달 동안은 잘 작동했고 클라이언트도 만족했지만, 곧 기술적인 문제가 나타났습니다:
- Tesseract 가 특정 CV 레이아웃, 특히 스캔된 문서에서 어려움을 겪었습니다.
- VPS에서 너무 많은 RAM을 사용해, 우리가 필요로 하는 고정밀 성능을 방해했습니다.
반복 2 – 더 나은 OCR을 위한 LlamaParse

- LlamaParse는 다양한 PDF 레이아웃을 처리하고 메모리 사용량을 줄입니다.
- 정확도가 크게 향상되어 필요한 수동 교정 횟수가 크게 감소했습니다.
Iteration 3 – Gemini Pro Vision (Current Solution)
The latest version swaps the ChatGPT API for Google Gemini Pro Vision. Gemini’s multimodal capabilities let us send the PDF directly to the model, which then extracts both the raw text and the structured JSON in a single request.
Key advantages
| Feature | Gemini Pro Vision | Previous Stack |
|---|---|---|
| 멀티모달 입력 (PDF) | ✅ | ❌ (PDF → OCR → text) |
| 단계별 추출 (텍스트 + JSON) | ✅ | ❌ (두 개의 별도 호출) |
| 1k 토큰당 비용 | $0.00035 | $0.0015 (ChatGPT) |
| 지연 시간 (평균) | ~1.2 s | ~2.8 s |
| 복잡한 레이아웃 정확도 | 높음 | 보통 |
The new microservice flow:
- Read Emails – same as before.
- Download PDF – fetch the attachment.
- Gemini Pro Vision Call – send the PDF; receive raw text and a JSON payload.
- Odoo XML‑RPC – create the recruitment record and attach the original PDF.
- Assign Lead – automatically allocate to a recruiter.

결과 및 시사점
| 지표 | 자동화 전 | Gemini 통합 후 |
|---|---|---|
| 이력서당 수동 데이터 입력 시간 | 약 4 분 | < 30 초 |
| 채용 담당자 집중 시간 | 하루의 30 % | 하루의 5 % |
| 정확도 (수동 수정) | 12 %의 이력서가 수정 필요 | < 2 % |
| 월 비용 (OCR + LLM) | $120 (Tesseract + ChatGPT) | $28 (Gemini) |
| 시스템 RAM 사용량 | 1.2 GB (Tesseract) | 300 MB (Gemini) |
주요 교훈
- 작업에 맞는 도구 선택 – 최신 멀티모달 LLM은 전체 OCR + LLM 파이프라인을 대체할 수 있습니다.
- 비용이 중요 – Gemini의 토큰당 저렴한 가격 덕분에 작은 에이전시에서도 지속 가능한 솔루션이 되었습니다.
- 아키텍처를 단순하게 유지 – 구성 요소가 적을수록 장애 지점이 줄어들고 유지보수가 쉬워집니다.
- GDPR 준수 – 모든 처리는 안전한 서버에서 이루어지며, PDF는 필요할 때만 저장되고, 개인 데이터는 Gemini(이 서비스는 GDPR‑준수) 외의 제3자 서비스로 전송되지 않습니다.
최종 생각
DIY OCR + ChatGPT 스택에서 단일 호출 Gemini Pro Vision 솔루션으로 전환하면서, 고통스러운 수작업 프로세스를 거의 즉시, 비용 효율적인 파이프라인으로 바꾸었습니다. 이제 채용 담당자는 인재와 기회를 매칭하는 본연의 업무에 집중할 수 있고, 시스템은 데이터 추출 및 입력이라는 무거운 작업을 처리합니다.
비슷한 이력서 파싱 문제를 겪고 있다면, Gemini와 같은 멀티모달 LLM을 고려해 보세요. 아키텍처를 크게 단순화하고 비용을 절감하며 정확성을 높일 수 있습니다—모두 GDPR 친화적인 상태를 유지하면서 말이죠.
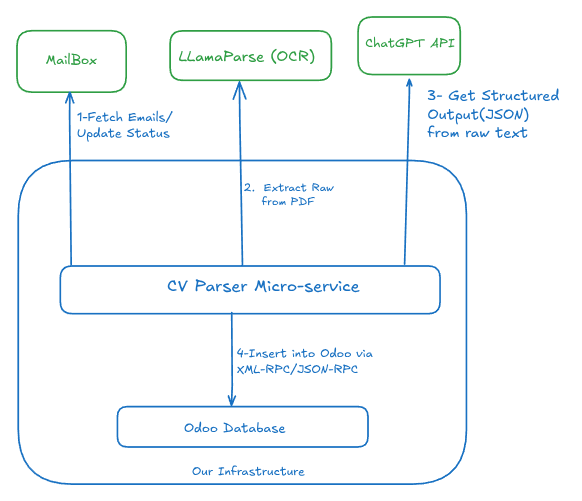
For context, **LlamaParse** is a specialized tool created by [LlamaIndex](https://www.llamaindex.ai/). It is designed specifically to *read* and parse complex documents (like PDFs) so AI models can understand them better.
Switching to LlamaParse was a great decision. It allowed us to process any CV format—scanned or digital—and obtain excellent results from the LLM. We ran this setup for a few months until we hit a new problem. This time, it wasn’t technical; it was financial. **ChatGPT was becoming too expensive.**Source: …
반복 3: DeepSeek 실험
우리 회사는 ChatGPT API에 너무 많은 비용을 쓰고 있다는 것을 눈치채기 시작했습니다. 동시에 **DeepSeek**이 새롭게 등장해 인터넷을 휩쓸고 있었습니다.
우리는 DeepSeek을 한동안 평가했습니다. 실제로 매우 훌륭했습니다. ChatGPT에서 DeepSeek으로 전환했으며, 결과는 즉각적이었습니다: ChatGPT에서 일주일 동안 지속되던 예산이 DeepSeek에서는 한 달 전체에 걸쳐 지속되었고, 결과는 더욱 향상되었습니다.
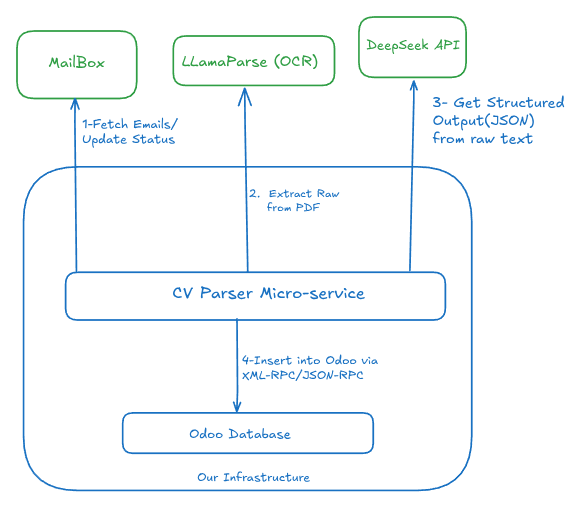
불행히도 우리는 DeepSeek을 단 두 달만 사용하고 **GDPR Compliance**라는 법적 장벽에 부딪혔습니다.
DeepSeek은 유럽 데이터 보호법(GDPR/RGPD)을 준수하지 않았습니다. 프랑스 시민들의 개인 데이터를 처리하고 있었기 때문에, 더 이상 사용할 수 없었습니다.
승리하는 설정: Google Gemini
우리는 이번에 Google Gemini 로 새로운 마이그레이션을 수행했으며, 비용 효율성, 효율성 및 규정 준수의 균형을 찾고자 했습니다.
결과는 기대 이상이었습니다. Gemini는 매우 강력해서 LlamaParse를 완전히 제거할 수 있었습니다. 이제 우리는 Vision/OCR 부분과 데이터 추출 모두에 Gemini를 사용합니다. 과정은 매우 간단합니다: 프롬프트와 PDF 첨부 파일을 직접 Gemini에 전송합니다.
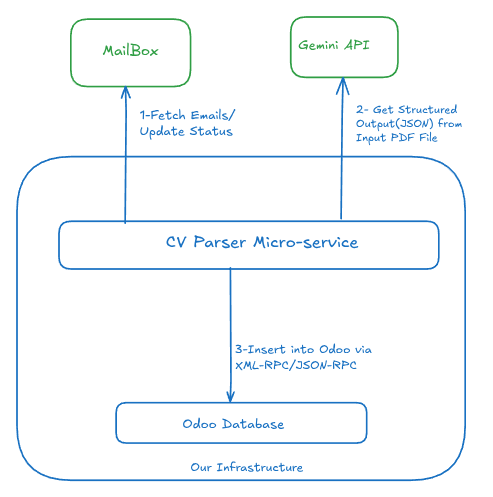
우리는 이 마이크로서비스의 코드를 6개월 넘게 건드리지 않았습니다. 왜냐하면 그대로 잘 작동하기 때문입니다. 모든 것이 원활히 진행되고 있으며, GDPR을 완전히 준수하고 있습니다.
결론
이 여정을 통해 소프트웨어 개발이 반복에 관한 것임을 배웠습니다. 우리는 기본 오픈‑소스 OCR로 시작해, 특화된 파싱 도구로 전환하고, 비용을 최적화했으며, 최종적으로 성능과 규정 준수의 최적 조합을 제공하는 솔루션에 착안했습니다.
오늘날, 클라이언트의 채용 담당자들은 더 이상 데이터 입력에 시간을 낭비하지 않습니다. 그들은 가장 잘 할 수 있는 일, 즉 적합한 학생에게 적합한 직업을 찾는 일에 집중합니다.