Flexora: 대형 언어 모델을 위한 유연한 Low‑Rank Adaptation
발행: (2026년 1월 14일 오전 07:22 GMT+9)
4 분 소요
원문: Dev.to
Source: Dev.to
현재 문제
- 배경: 대규모 언어 모델(LLM)의 파인튜닝은 매우 많은 자원을 소모합니다. 이를 해결하기 위해 LoRA(Low‑Rank Adaptation) 방법이 등장했으며, 원본 모델을 고정하고 소량의 부가 파라미터만 학습합니다.
- LoRA의 한계: 효과적이지만 LoRA는 종종 overfitting(모델이 훈련 데이터에만 과도하게 맞춰 실제 성능이 떨어지는 현상) 문제에 직면합니다. 현재의 해결책은 수동 조정이 필요하거나 작업마다 유연성이 부족합니다.
해결책: Flexora
저자들은 Flexora라는 새로운 방법을 제안합니다. Flexora는 모델 전체를 파인튜닝하거나 무작위로 선택하는 대신, 가장 중요한 레이어를 자동으로 선택하도록 합니다.
작동 메커니즘 (3단계)
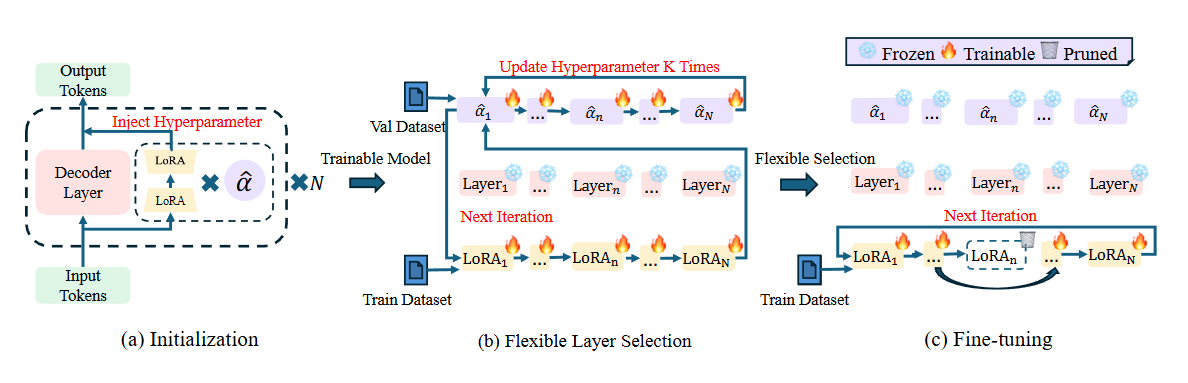
Flexora는 레이어 선택을 초매개변수 최적화(Hyperparameter Optimization – HPO) 문제로 간주합니다. 전체 과정은 3단계로 구성됩니다.
- 초기 단계 – 모델 각 레이어의 LoRA 모듈에 스칼라 가중치(α라고 부름)를 추가합니다.
- 유연한 레이어 선택 단계 (Flexible Selection)
- 작은 검증 데이터셋을 사용해 Unrolled Differentiation 기법으로 α 가중치를 학습합니다.
- 시스템이 자동으로 어느 레이어가 출력에 가장 크게 기여하는지 학습합니다.
- 점수가 높은 레이어는 유지하고, 점수가 낮은 레이어는 제외합니다.
- 파인튜닝 단계 (Fine‑tuning) – 2단계에서 선택된 중요한 레이어만 학습하고, 나머지 레이어는 고정합니다. 이를 통해 자원을 절약하고 핵심 부분에 집중할 수 있습니다.
결과 및 효율성
- 성능 향상: Flexora는 여러 벤치마크(Hellaswag, PIQA, RACE 등)에서 기존 LoRA 및 다른 방법들을 능가합니다.
- overfitting 감소: 불필요한 파라미터를 제거함으로써 모델의 일반화가 개선됩니다(암기 대신 이해).
- 파라미터 절감: Flexora는 LoRA 대비 약 50 % 정도의 파라미터만 사용하면서도 더 좋은 결과를 제공합니다.
- 확장성: 이 방법은 Llama, Mistral, ChatGLM 등 다양한 모델에서 잘 작동합니다.
연구 결과
- LLM의 모든 레이어가 특정 작업에 동일하게 중요한 것은 아닙니다.
- Flexora는 주로 입력 초반 레이어와 출력 최종 레이어를 선택하는 경향이 있습니다. 이는 입력과 출력에 가장 중요한 정보를 담고 있기 때문입니다.
요약: Flexora는 LoRA의 스마트 업그레이드 버전으로, 자동으로 “핵심 레이어만 선택”하여 모델을 더 똑똑하고 가볍게 만들며, 암기를 방지합니다.