분산 작업 큐 시스템
Source: Dev.to
The Problem
수천 개의 이미지를 처리하는 데이터 파이프라인을 운영하고 있습니다. 워커들은 문제없이 작업을 수행하고 있습니다. 그런데 코디네이터 서버가 다운됩니다.
- 작업이 사라집니다.
- 두 워커가 같은 이미지를 동시에 처리하기 시작합니다.
- 파이프라인이 멈춥니다.
이것이 분산 시스템의 현실입니다. 머신이 고장 나고, 네트워크가 분할됩니다. 실패에 대비하지 않으면, 실패가 재앙으로 이어집니다.
프로덕션 시스템이 이를 어떻게 처리하는지 이해하고 싶어 직접 분산 작업 큐를 처음부터 구현했습니다. Redis를 사용하지 않고, Raft 합의 알고리즘을 이용해 조정 레이어를 직접 만들었습니다. 그 결과: 여러 워커에 걸쳐 Python 코드를 실행하고, 브로커가 다운돼도 다른 브로커가 데이터 손실 없이 매끄럽게 계속 동작하는 시스템이 탄생했습니다.
Architecture
시스템은 세 가지 구성 요소로 이루어집니다:

- Broker cluster – 세 노드에 걸쳐 Raft 합의 프로토콜을 실행합니다. 리더를 선출하고 모든 작업 상태를 각 노드에 복제합니다. 하나의 브로커가 다운되더라도 남은 두 개가 계속 운영됩니다.
- Workers – 무상태(stateless)입니다. 리더에게 작업을 요청하고, 샌드박스된 서브프로세스에서 코드를 실행한 뒤 결과를 보고합니다. 필요에 따라 워커를 수평 확장할 수 있습니다.
- Clients – 작업을 제출하고 결과를 조회합니다. 워커와 클라이언트는 현재 리더를 자동으로 발견합니다.
핵심 구분점: Raft 클러스터는 브로커 장애가 데이터를 잃지 않도록 보장합니다. 워커 장애는 감지되지만 다른 방식으로 처리됩니다(아래 참고).
Task Structure
작업은 원격 실행을 위한 Python 코드를 패키징합니다:
{
"task_id": "uuid-1234",
"task_type": "python_exec",
"payload": {
"code": "def count_words(text): return len(text.split())",
"function": "count_words",
"args": ["hello world"]
},
"status": "pending"
}수명 주기는 간단합니다: pending → processing → completed. 브로커가 각 전환을 추적하고, Raft가 모든 브로커가 현재 상태에 동의하도록 보장합니다.
Raft Consensus
핵심 문제: 세 브로커가 동일한 작업 상태를 유지해야 합니다. 단순 브로드캐스트는 순서가 뒤섞이거나 패킷이 손실되고, 서로 다른 뷰가 생깁니다. Raft는 리더 선출과 로그 복제를 통해 이를 해결합니다.
Leader Election
모든 노드는 팔로워 상태로 시작하며, 리더의 신호를 기다립니다. 팔로워가 무작위 타임아웃(1.5–3 초) 내에 하트비트를 받지 못하면 후보자가 되어 동료에게 투표를 요청합니다.
def _on_election_timeout(self):
self.state = RaftState.CANDIDATE
self.current_term += 1
self.voted_for = self.node_id
# Request votes from all peers...무작위 타임아웃은 교착 상태를 방지합니다: 모든 노드가 동시에 타임아웃이 되면 서로에게 투표해 승자를 가릴 수 없게 됩니다. 무작위성을 두면 보통 하나의 노드가 먼저 캠페인을 시작합니다.
Log Replication
리더는 명령을 자신의 로그에 추가하고 팔로워에게 보냅니다. 엔트리는 다수의 노드가 보유했을 때만 커밋됩니다.
def _try_commit(self):
for n in range(len(self.log) - 1, self.commit_index, -1):
# Count how many nodes have this entry
count = 1 # Leader has it
for peer in self.peers:
if self.match_index.get(peer, -1) >= n:
count += 1
# Commit requires majority (2 of 3 nodes)
if count >= majority:
self.commit_index = n
self._apply_committed()
break다수 요구조건이 Raft를 내결함성 있게 만드는 핵심입니다. 리더가 하나의 팔로워에게만 복제한 뒤 죽으면 해당 엔트리는 아직 커밋되지 않은 것이므로, 살아남은 노드가 새 리더를 선출하고 그 미커밋 엔트리는 롤백되어 일관성이 유지됩니다.
A Note on Persistence
내 구현은 모든 데이터를 메모리에 보관합니다. 실제 프로덕션 Raft에서는 currentTerm, votedFor, 로그를 디스크에 기록한 뒤에야 메시지를 인정합니다. 영속성이 없으면 크래시된 노드가 빈 상태로 재시작해 같은 term에서 다시 투표할 수 있어 Raft 안전성을 깨뜨릴 수 있습니다. 학습용으로는 괜찮지만 프로덕션에서는 절대 안 됩니다.
Failure Scenarios
분산 시스템의 진정한 시험은 문제가 발생했을 때 어떻게 동작하느냐입니다. 주요 시나리오는 다음과 같습니다.
Scenario 1: Leader Broker Dies
Raft가 설계된 바로 그 상황입니다.
Initial state: Broker 1이 리더이고, Broker 2와 3은 팔로워입니다. 두 워커가 연결돼 작업을 처리하고 있습니다.
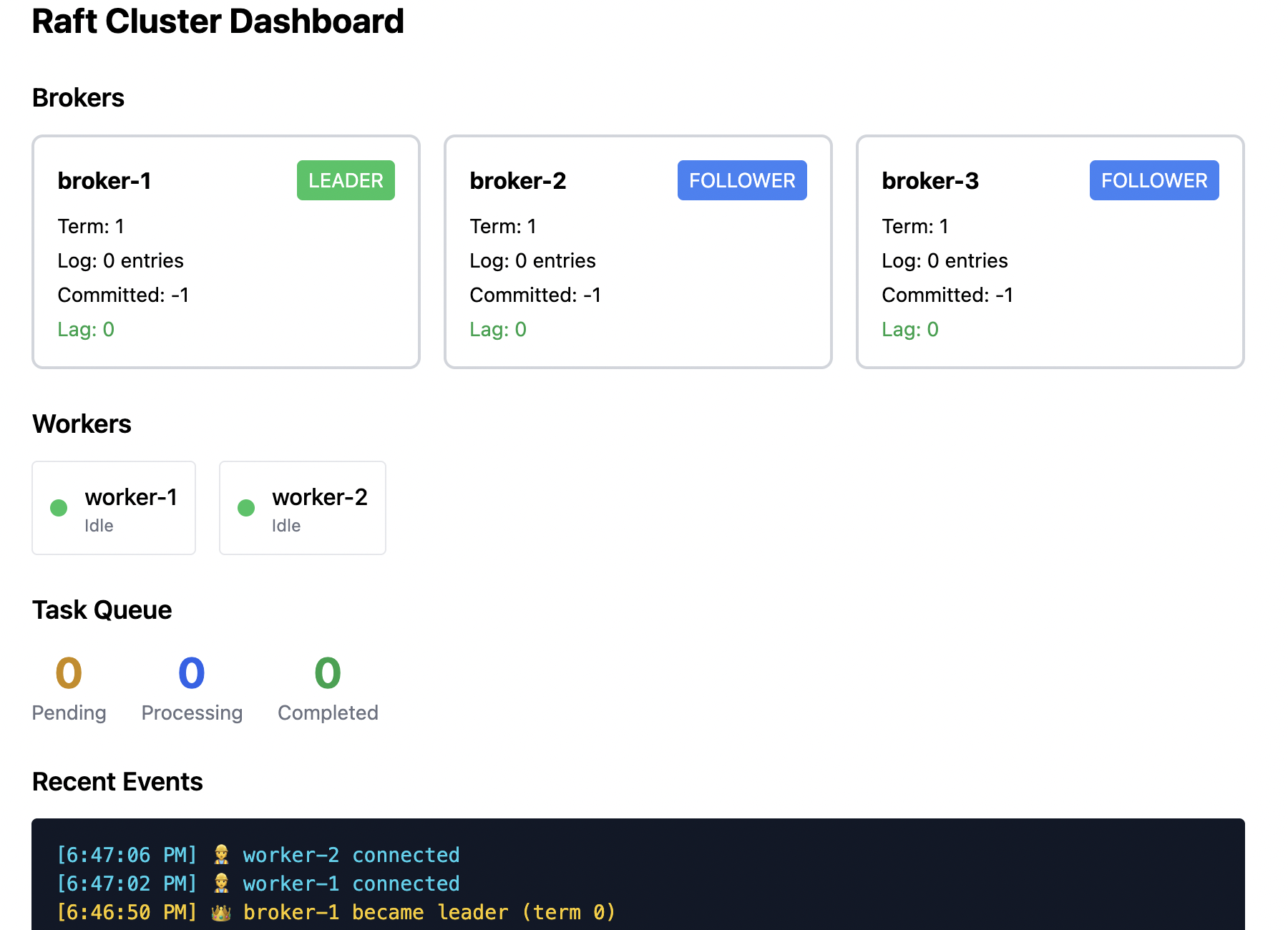
The failure: Broker 1이 크래시하거나 네트워크가 분할됩니다.
What happens next:
- Broker 2와 3은 Broker 1으로부터 하트비트를 받지 못합니다.
- 그들의 선거 타이머가 (1.5–3 초 내에) 만료됩니다.
- 그 중 하나(예: Broker 2)가 먼저 타임아웃되고 후보자가 되어 투표를 요청합니다.
- Broker 3이 투표를 허용합니다(Broker 1은 접근 불가).
- Broker 2가 새로운 리더가 되고 하트비트를 전송하기 시작합니다.
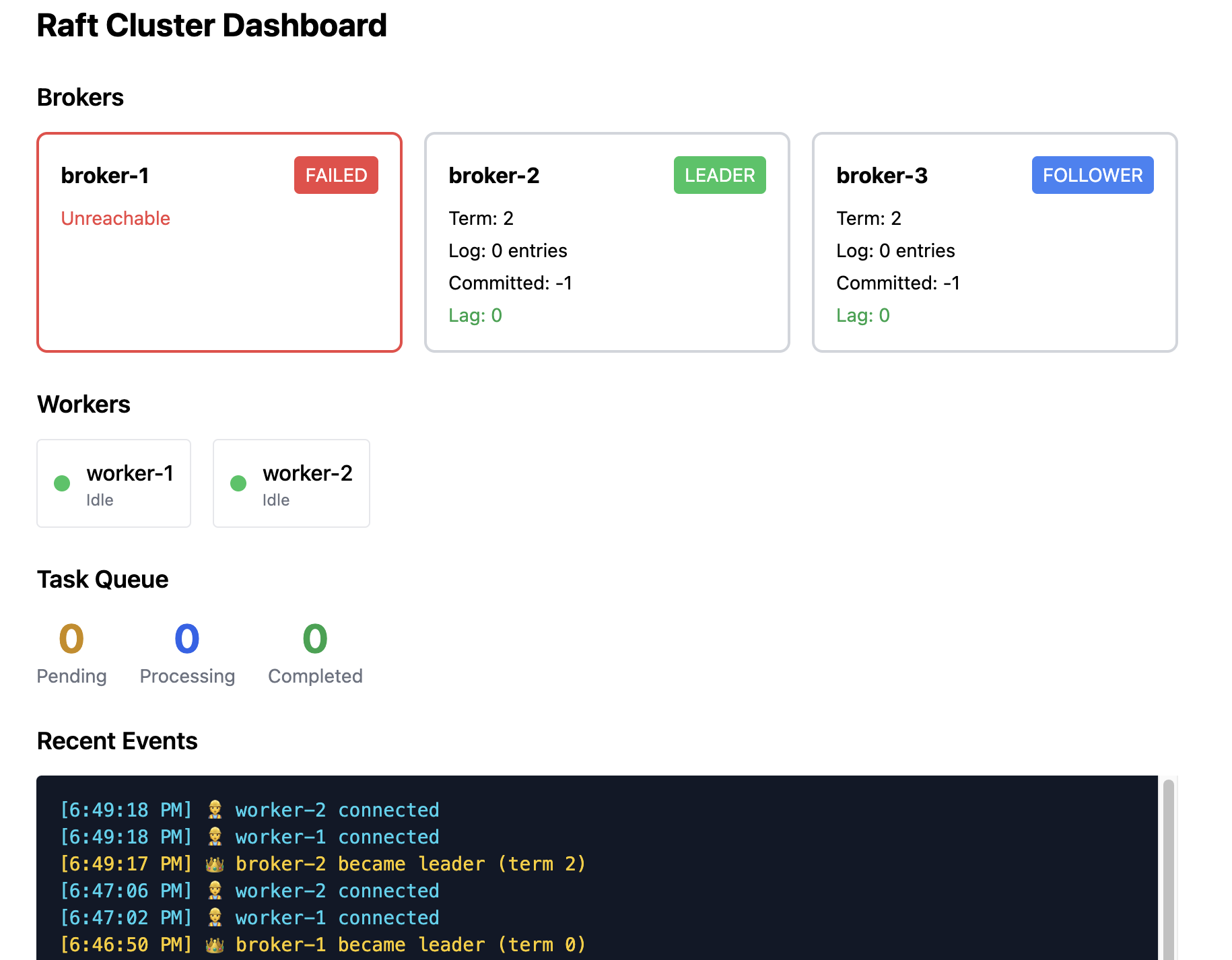
Worker behavior: 워커가 다음에 Broker 1에 요청하면 연결 오류가 발생합니다. 워커는 알려진 브로커 주소들을 순차적으로 조회하고 /status 엔드포인트를 호출해 현재 리더가 Broker 2임을 발견한 뒤 재연결합니다(보통 1–2 초 소요).
Data safety: 크래시 이전에 커밋된 모든 작업은 안전합니다—다수 노드에 존재하고 새 리더가 이를 보유하고 있기 때문입니다. 두 노드 미만이 받은 미커밋 엔트리는 손실되지만, 이는 클라이언트에게 아직 확인되지 않은 상태이므로 문제되지 않습니다.
Scenario 2: Follower Broker Dies
리더 장애보다 간단합니다.
Initial state: Broker 1이 리더이고, Broker 3이 다운됩니다.
What happens: 눈에 띄는 변화가 거의 없습니다. 리더는 Broker 3이 AppendEntries에 응답하지 않는 것을 감지하지만, Broker 2와는 여전히 통신합니다. 3대 2개의 노드 중 2개가 살아 있으므로 클러스터는 쿼럼을 유지하고 정상적으로 동작합니다. 쓰기 작업은 리더가 Broker 2에 복제하고 응답을 받아 커밋됩니다.
If Broker 3 returns: 다시 팔로워로 합류하고 리더로부터 누락된 로그를 받아 최신 상태로 동기화됩니다.
Scenario 3: Worker Dies Mid‑Task
브로커는 죽은 워커를 감지하고 해당 작업을 자동으로 재할당합니다.
Initial state: Worker 1이 Task A를 처리 중이고, Worker 2는 대기 상태입니다.

Failure: Worker 1이 크래시하거나 네트워크가 끊깁니다.
Broker response: 브로커는 워커로부터 오는 하트비트를 모니터링합니다. Worker 1의 하트비트가 멈추면 브로커는 해당 작업을 pending 상태로 되돌리고 큐에 다시 넣습니다. Worker 2(또는 다른 가용 워커)가 Task A를 가져가 처리합니다.
Result: 작업이 손실되지 않으며, 워커가 교체되더라도 시스템은 일관성을 유지합니다.