Amazon Bedrock에서 Knowledge Base 생성 (단계별 콘솔 가이드)
I’m happy to translate the article for you, but I need the text you’d like translated. Could you please paste the content (or the portion you want translated) here? I’ll keep the source line exactly as you provided and preserve all formatting, markdown, and code blocks.
사전 요구 사항
시작하기 전에 다음을 확인하십시오:
- Amazon Bedrock, Amazon S3, 그리고 사용하려는 벡터 스토어에 대한 권한이 있는 AWS 계정(일반적으로 OpenSearch Serverless 또는 Aurora PostgreSQL/pgvector, 설정에 따라 다름).
- 소스 문서가 준비되어 있는지(PDF, 텍스트, HTML, 문서 내보내기 등).
- Bedrock Knowledge Bases를 사용할 수 있는 대상 AWS 리전.
- 문서 저장 위치(보통 S3 버킷).
Step 1 — Amazon Bedrock 열고 Knowledge Bases 탐색
- AWS 콘솔에 로그인합니다.
- Amazon Bedrock을 검색합니다.
- Bedrock 왼쪽 탐색 창에서 Knowledge bases를 찾습니다 (예: Builder tools와 같은 적절한 섹션 아래).
- Knowledge bases를 클릭합니다.

Step 2 — 지식 베이스 만들기 시작하기
Knowledge Bases 페이지에서 Create knowledge base를 클릭합니다.
이렇게 하면 가이드형 마법사 스타일 워크플로우가 시작됩니다.
Step 3 — 지식 베이스 설정 유형 선택
In the wizard you’ll typically see options such as:
- 벡터 스토어가 포함된 지식 베이스 (RAG에 권장)
- 계정/지역 기능에 따라 다른 옵션
Select the 벡터 스토어가 포함된 지식 베이스 option.

Note: 지식 베이스는 임베딩을 벡터 인덱스에 저장하므로 Bedrock이 쿼리 시점에 관련 텍스트 조각을 검색할 수 있습니다.
임베딩은 데이터(텍스트, 이미지, 오디오 등)의 의미와 맥락을 수학적 형태로 포착한 수치 표현입니다. 한 줄로 요약하면: 임베딩은 인간 지식을 AI가 검색·비교·추론할 수 있는 수학으로 변환합니다.
Step 4 — 지식 베이스 세부 정보 정의
다음 정보를 제공하십시오:
- Knowledge Base Name (예:
utility-ops-kb) - Description (선택 사항이지만 권장됨)
- Organizational tags (선택 사항)
저는
knowledge-base-dipayan이라는 이름을 사용했지만, 최선의 방법은 도메인 및 환경에 맞게 이름을 맞추는 것입니다. 예:us-outage-kb-dev.

Step 5 — Configure Data Source (Amazon S3)
- Amazon S3를 데이터 소스로 선택합니다.
- 문서가 저장된 S3 버킷 및 프리픽스/폴더를 선택합니다.
- 문서 형식 및 포함 규칙을 확인합니다(프롬프트가 표시되는 경우).

bedrock-dipayanS3 버킷을 사용해 Jeff Bezos의 2022년 주주 서한을 업로드했습니다.
베스트 프랙티스: KB 전용 프리픽스를 유지하세요. 예:s3://my-company-kb/energy-utility/outage-procedures/.


IAM Permissions
Bedrock이 다음 작업을 수행하려면 권한이 필요합니다:
- 읽기: S3 버킷에서 문서를 읽기.
- 쓰기: 선택한 벡터 스토어에 임베딩을 쓰기.
- 실행: 동기화 작업 수행.
마법사에서 다음 중 하나를 선택할 수 있습니다:
- Bedrock이 새 IAM 역할을 생성하도록 허용 또는
- 기존 IAM 역할을 선택.
베스트 프랙티스: 최소 권한 원칙을 적용하세요. 기존 역할을 선택하는 경우 최소한 다음 권한이 포함되어 있어야 합니다:
s3:GetObject(버킷/프리픽스에 대해)- 선택한 벡터 스토어에 필요한 권한.
Step 6 — (선택 사항) 파싱 전략 선택
원본 가이드에는 “S3 데이터 소스 및 파싱 전략”에 대한 이미지가 포함되어 있었습니다. 이미지 URL이 잘려서, 여기 적절한 스크린샷을 삽입해 주세요.
Step 7 — 검토 및 생성
- 최종 요약 페이지에서 모든 설정을 검토합니다.
- Create knowledge base를 클릭합니다.
Bedrock은 이제 다음을 수행합니다:
- S3 버킷을 크롤링하고,
- 지원되는 문서 유형에서 텍스트를 추출하고,
- 임베딩을 생성하고,
- 벡터 스토어를 채웁니다.
상태가 Active(활성)로 변경되면 Bedrock API 또는 콘솔을 통해 지식 베이스에 쿼리를 시작할 수 있습니다.
빠른 요약
| 단계 | 작업 |
|---|---|
| 1 | Bedrock 열기 → Knowledge bases |
| 2 | Create knowledge base 클릭 |
| 3 | Knowledge base with vector store 선택 |
| 4 | 이름, 설명, 태그 설정 |
| 5 | S3 데이터 소스 및 IAM 역할 구성 |
| 6 | (선택 사항) 파싱 전략 선택 |
| 7 | 검토 및 생성 |
이제 Retrieval‑Augmented Generation (RAG) 워크로드에 사용할 수 있는 완전한 기능의 Amazon Bedrock Knowledge Base가 준비되었습니다. 즐거운 구축 되세요!
Source: …
Step 5 – 데이터 소스 구성
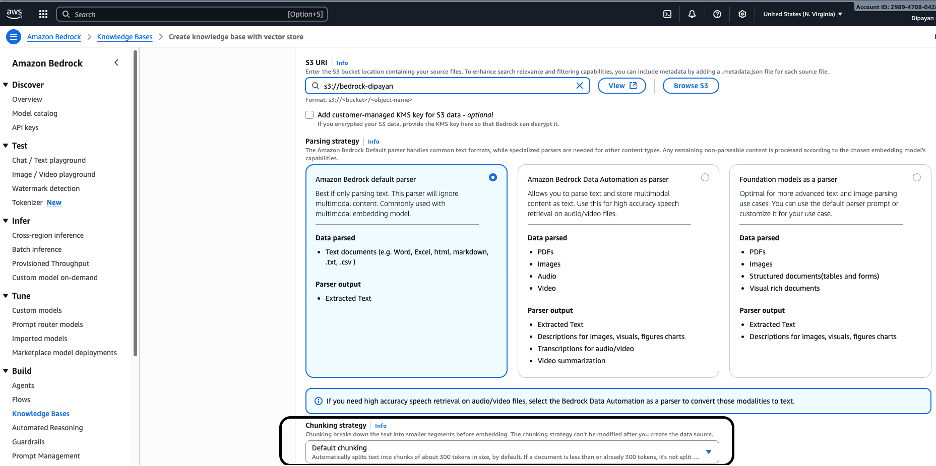
S3 URI 아래에 소스 문서가 들어 있는 Amazon S3 버킷 위치를 입력합니다.
예시
s3://bedrock-dipayan/Browse S3를 클릭하여 버킷을 선택하거나 View를 클릭해 내용을 확인할 수 있습니다.
선택 사항으로, S3 데이터가 CMK로 암호화된 경우 고객이 관리하는 KMS 키를 제공할 수 있습니다.
파싱
파싱은 Bedrock이 임베딩하기 전에 소스 파일에서 내용을 추출하는 방식을 결정합니다. 스크린샷을 기준으로 세 가지 파서 옵션이 제공됩니다:
옵션 1 – Amazon Bedrock 기본 파서 (선택됨)
대부분의 텍스트 기반 지식 베이스에 권장됩니다.
- 대상: 텍스트가 많은 문서(PDF, Word, Excel, HTML, Markdown, CSV, TXT)
- 파서 출력: 추출된 순수 텍스트
- Amazon Titan Embeddings 또는 기타 텍스트 임베딩 모델과 잘 작동합니다.
Typical use cases: 기업 문서, SOP, 보고서, 정책, 서한, 매뉴얼.
옵션 2 – Amazon Bedrock 데이터 자동화 파서
멀티모달 콘텐츠를 위해 설계되었습니다.
- 대상: 복잡한 레이아웃의 PDF, 이미지, 오디오, 비디오 파일
- 파서 출력:
- 추출된 텍스트
- 이미지 설명 및 캡션
- 오디오/비디오 전사 및 요약
텍스트가 아닌 콘텐츠가 포함된 지식 베이스를 검색 가능한 텍스트로 변환해야 할 때 사용합니다.
옵션 3 – 파운데이션 모델을 이용한 파서
파운데이션 모델을 사용해 풍부하거나 복잡한 문서를 파싱합니다.
- 대상: 표, 양식, 구조화된 문서, 시각 요소가 많은 PDF
- 파서 출력:
- 추출된 텍스트
- 그림, 시각 자료, 표에 대한 설명
고급 파싱을 제공하지만 비용 및 처리 시간이 증가할 수 있습니다.
청킹 전략 구성
청킹은 임베딩을 생성하기 전에 문서를 더 작은 세그먼트로 나누는 방식을 제어합니다.
- 기본 청킹 (선택됨)
- 텍스트를 약 500 토큰 크기의 청크로 분할
- 필요에 따라 겹침을 적용해 컨텍스트 유지
- 문서가 청크 크기보다 작으면 청킹을 건너뜀
청킹이 중요한 이유
- 작은 청크는 검색 정확도를 높입니다.
- 겹치는 청크는 의미적 연속성을 보존합니다.
- 적절한 청킹은 환각을 줄이고 근거를 강화합니다.
베스트 프랙티스: 특별히 긴 법률 문서나 고도로 구조화된 데이터와 같이 맞춤형이 필요한 경우가 아니라면 기본 청킹을 사용하세요.
Step 6 — 임베딩 모델 선택
문서를 벡터(임베딩)로 변환하는 데 사용되는 임베딩 모델을 선택합니다. 일반적인 선택 항목은 다음과 같습니다:
- Amazon Titan Embeddings (일반적인 기본값)
- 기타 제공자 임베딩 모델(계정에서 활성화된 모델에 따라 다름)
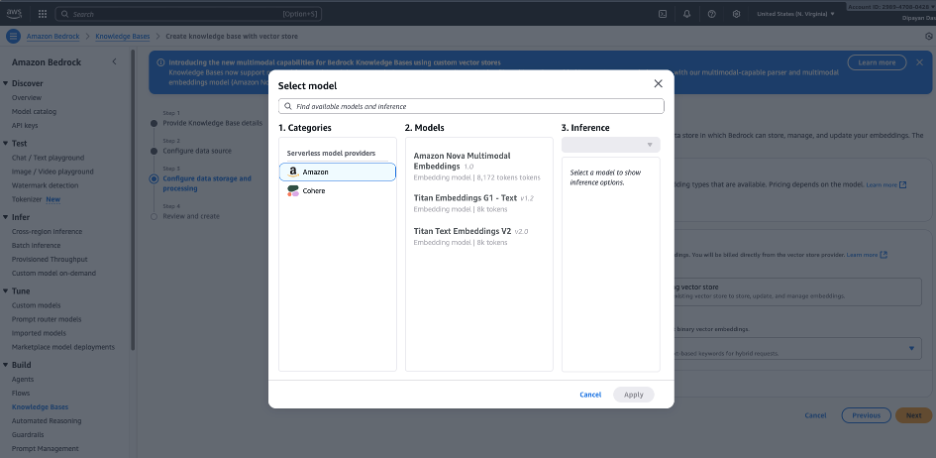
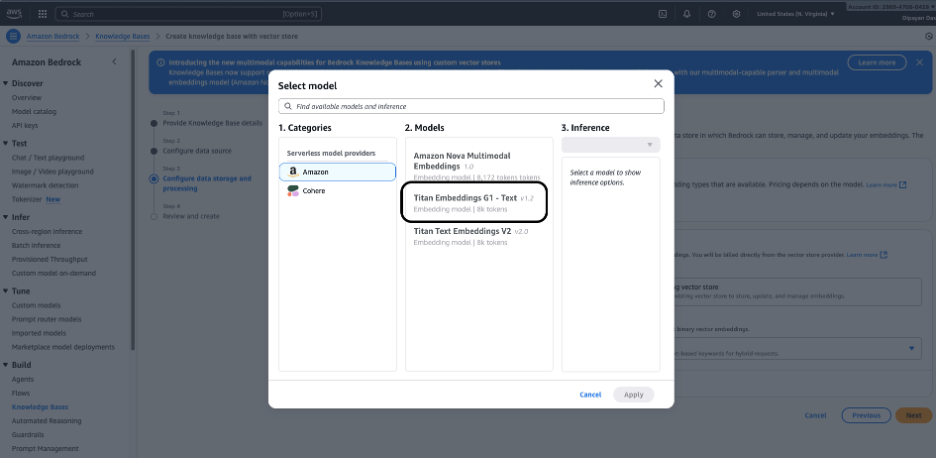
Step 7 – 임베딩 모델 및 벡터 스토어 구성
-
데이터 저장 및 처리 구성 – 임베딩 모델을 선택합니다. Select model을 클릭하고 임베딩 모델(예: Amazon Titan Embeddings)을 선택하여 문서를 벡터 표현으로 변환합니다.
-
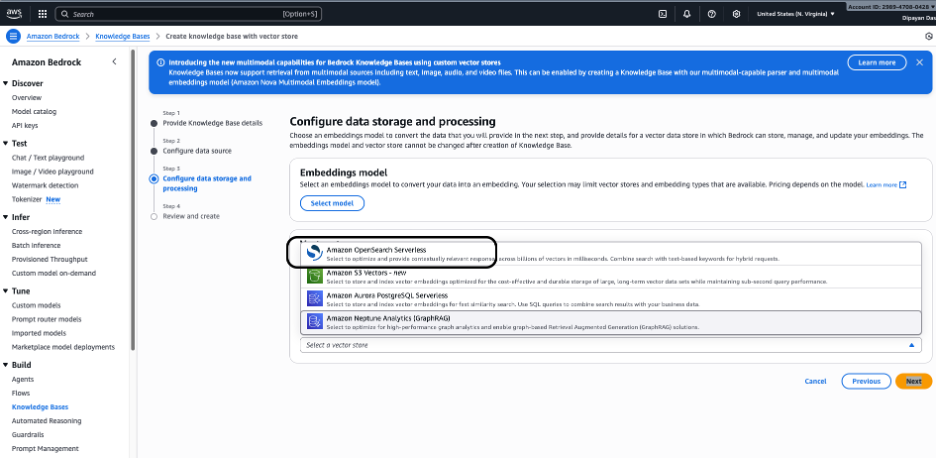
벡터 스토어 선택 – Bedrock이 임베딩을 저장하고 관리할 위치를 선택합니다. 사용 가능한 옵션:
- Amazon OpenSearch Serverless (대부분의 사용 사례에 권장) – 의미론적 및 하이브리드 검색에 최적화된 완전 관리형, 확장 가능한 벡터 검색.
- Amazon Aurora PostgreSQL Serverless (pgvector) – 이미 관계형 데이터베이스를 사용 중이며 SQL 기반 벡터 쿼리를 원할 때 적합.
- Amazon Neptune Analytics (GraphRAG) – 그래프 기반 검색 및 고급 관계 기반 RAG 시나리오에 사용.
고성능 의미 검색에 최적화된 완전 관리형 벡터 데이터베이스인 Amazon OpenSearch Serverless를 (스크린샷에 표시된 대로) 선택합니다. Bedrock이 필요한 벡터 인덱스를 자동으로 생성하고 관리합니다.
Source:
Step 8 — Review and Create
-
전체 구성 요약을 검토합니다:
- 지식 베이스 이름
- 데이터 소스 경로
- 임베딩 모델
- 벡터 스토어 구성
- IAM 역할
-
Create knowledge base를 클릭합니다.
이 시점에서 Knowledge Base 객체가 생성되지만, 문서를 아직 수집/동기화해야 합니다.
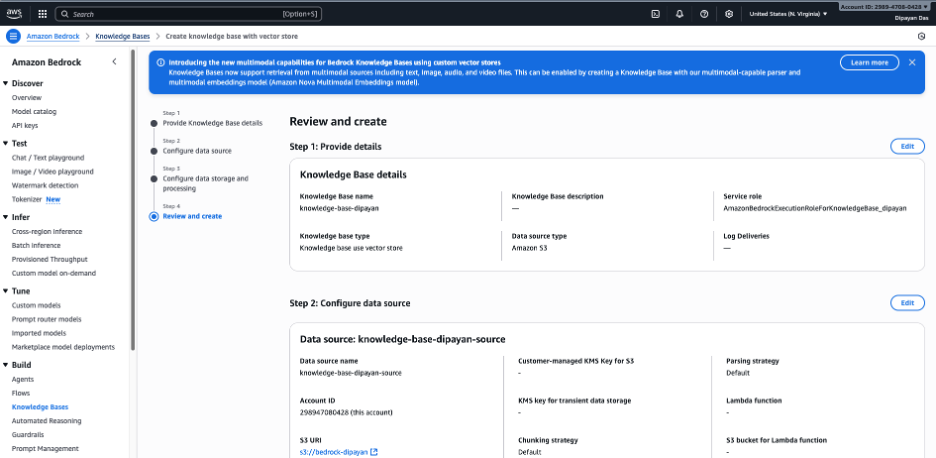

Knowledge Base가 준비되었습니다, 하지만 문서가 동기화되기 전까지는 “Test Knowledge Base” 옵션이 회색으로 표시되어 테스트할 수 없습니다.
9단계 — 문서 동기화 (Ingest)
- 지식 베이스를 엽니다.
- Sync(때때로 Sync data source라고 표시됨)를 시작합니다.
- 동기화 상태가 Completed/Ready(완료/준비됨)으로 표시될 때까지 모니터링합니다.
동기화가 수행하는 작업:
문서를 청크로 나누고, 임베딩을 생성한 뒤, 이를 벡터 인덱스에 저장합니다.

10단계 — 생성된 지식 베이스 테스트
Amazon Bedrock의 Test Knowledge Base 옵션을 사용하면 지식 베이스(KB)가 애플리케이션이나 에이전트에 통합되기 전에 기대대로 작동하는지 대화형으로 검증할 수 있습니다. 이는 내장된 RAG 테스트 콘솔 역할을 합니다.
이 화면에서 할 수 있는 작업:
- 자연어 질문을 할 수 있습니다.
- 검색 및 생성 동작을 제어합니다.
- 답변에 사용된 원본 청크를 검사합니다.
- 근거와 관련성을 확인합니다.
- 구성 설정을 실시간으로 조정합니다.
