16배 성능 향상 및 98% 비용 절감: 업그레이드된 SLS Vector Indexing Architecture 살펴보기
Source: Dev.to
로그 시나리오에서 벡터 인덱싱의 비용 및 처리량 문제
시맨틱 인덱싱에서 임베딩 과정은 시맨틱 재현율을 결정하는 핵심 요소입니다. 전체 시맨틱 인덱싱 파이프라인에서 임베딩은 또한 핵심 비용 구성 요소를 차지합니다.
- 비용: 1 GB 데이터를 임베딩하는 데 수백 위안(CNY)이 소요될 수 있습니다.
- 속도: 처리량은 약 100 KB/s 로 제한됩니다.
이에 비해 인덱스 구축 및 저장 비용은 무시할 수 있습니다. GPU에서 임베딩 모델의 추론 효율이 시맨틱 인덱스를 구축하는 속도와 총 비용을 직접 결정합니다.
지식베이스 시나리오에서는 데이터가 비교적 정적이고 업데이트가 드물기 때문에 이러한 비용이 허용될 수 있습니다. 그러나 Simple Log Service (SLS) 스트리밍 데이터와 같이 새로운 데이터가 지속적으로 생성되는 경우, 성능과 비용 모두에 큰 압박이 가해집니다. 기가바이트당 수백 위안의 비용과 100 KB/s의 처리량만으로는 프로덕션 워크로드를 지속하기 어렵습니다.
대규모 애플리케이션의 성능 및 비용 효율성을 개선하기 위해, 우리는 임베딩 서비스의 추론 병목 현상을 목표로 체계적인 최적화를 수행했습니다. 심층 분석, 솔루션 선택 및 맞춤형 개선을 통해 처리량을 16배 향상시키면서 요청당 리소스 비용을 크게 절감했습니다.
Source: …
기술적 과제 및 최적화 전략
임베딩 서비스의 최적 비용 효율성을 달성하기 위해 다음과 같은 핵심 과제들을 해결해야 했습니다:
1. Inference Framework
시중에는 vLLM, SGLang, llama.cpp, TensorRT, sentence‑transformers 등 다양한 추론 프레임워크가 존재하며, 각각 일반 목적 vs. 특화, CPU vs. GPU 등 초점이 다릅니다. 임베딩 워크로드에 가장 적합하고 하드웨어(특히 GPU) 성능을 극대화할 수 있는 프레임워크를 선택하는 것이 중요합니다.
연속 배치 처리와 커널 최적화와 같은 작업에 대한 프레임워크의 내재적 계산 효율성은 임베딩 모델의 추론 성능 병목이 될 수 있습니다.
2. GPU 활용도 극대화
GPU 자원은 비용이 많이 들기 때문에 활용도가 낮으면 낭비가 됩니다. 이는 CPU 시절과 크게 다릅니다.
- 배치 처리: 임베딩 추론은 배치 크기에 매우 민감합니다. 단일 요청을 처리하는 것은 배치 처리에 비해 효율이 크게 떨어집니다. 효율적인 요청‑배치 메커니즘이 필수적입니다.
- 병렬 처리: CPU 전처리(예: 토크나이징), 네트워크 I/O, GPU 연산은 완전히 분리되고 병렬화되어야 GPU 유휴 시간을 방지할 수 있습니다.
- 다중 모델 복제: 대규모 파라미터를 가진 챗 모델과 달리 일반적인 임베딩 모델은 파라미터가 적습니다. A10 GPU 하나에 단일 복제만 배치하면 약 15 %의 연산 능력과 13 %의 GPU 메모리만 사용됩니다. 하나의 GPU에 여러 모델 복제를 배치해 자원을 “소진”시키는 것이 비용 절감과 처리량 향상에 핵심입니다.
3. 우선순위 기반 스케줄링
시맨틱 인덱싱은 두 단계로 이루어집니다:
| 단계 | 배치 크기 | 우선순위 |
|---|---|---|
| 인덱스 구축 | 대규모 | 낮음 |
| 온라인 쿼리 | 소규모 | 높음 (실시간) |
쿼리 요청에 대한 임베딩 작업이 구축 작업에 의해 차단되지 않도록 해야 합니다. 세밀한 우선순위 큐 스케줄링 메커니즘이 필요하며, 단순한 자원 풀 격리는 충분하지 않습니다.
4. End‑to‑End 파이프라인의 병목
GPU 활용도가 향상된 후에는 파이프라인의 다른 부분(예: 토크나이징)이 새로운 병목이 될 수 있습니다.
Solution
우리는 최종적으로 다음과 같은 최적화 솔루션을 구현했습니다.

Optimization 1 – vLLM을 핵심 추론 엔진으로 선택 (llama.cpp 교체)
-
전환 이유:
- 초기 선택이었던 llama.cpp는 C++ 성능이 뛰어나고 CPU 친화적이며(일부 작업이 CPU 노드에서 실행) 통합이 용이하다는 점을 기반으로 했습니다.
- 최근 테스트 결과, 동일한 하드웨어 환경에서 vLLM(또는 SGLang)이 llama.cpp보다 2배 높은 처리량을 제공하면서 평균 GPU 사용률은 60 % 낮아졌습니다.
- 핵심 차이는 vLLM의 Continuous Batching 메커니즘과 고도로 최적화된 CUDA 커널에 있습니다.
-
배포 변경 사항:
- 임베딩 모듈을 독립 서비스로 분리하여 **Platform for AI (PAI)**의 **Elastic Algorithm Service (EAS)**에 배포했습니다.
- 이제 벡터 구축 및 쿼리 작업 모두 원격 호출을 통해 임베딩을 얻습니다.
- 네트워크 오버헤드와 추가 O&M 비용이 발생하지만, 기본 성능이 크게 향상되고 향후 최적화의 견고한 기반이 마련됩니다.
Optimization 2 – 단일 GPU에 다중 모델 복제본 배포
- 목표: A10 GPU 하나에 여러 모델 복제본을 실행해 GPU 활용도를 높인다.
- 선택한 프레임워크: Triton Inference Server.
- GPU당 모델 복제본 수를 손쉽게 제어할 수 있습니다.
- 스케줄링 및 동적 배칭 기능을 제공해 요청을 서로 다른 복제본으로 라우팅합니다.
- 구현 세부 사항: vLLM HTTP 서버를 우회하고 vLLM core library (
LLMEngine) 를 Triton의 Python 백엔드에서 직접 호출해 오버헤드를 감소시켰습니다.
Optimization 3 – 토크나이징을 모델 추론과 분리
- 발견된 문제: 다중 vLLM 복제본을 운영하면서 GPU 처리량이 개선된 뒤 토크나이징이 새로운 성능 병목 현상이 되었습니다.
- 해결책: (원본 텍스트의 연속)
[원본 내용이 여기서 잘렸으며, 남은 단계에서는 토크나이징을 별도 서비스로 오프로드하거나 병렬화하는 방법, 빠른 토크나이저 사용, 캐싱 메커니즘 적용 등에 대해 설명합니다.]
Result
- Throughput: 베이스라인 대비 ~16배 증가했습니다.
- Cost per request: GPU 활용도가 높아지고 유휴 자원이 감소하면서 크게 절감되었습니다.
- Scalability: 이제 시스템은 이전의 성능·비용 제약 없이 프로덕션 환경에서 연속적인 로그 스트림을 처리할 수 있습니다.
Optimization 4 – Priority Queuing and Dynamic Batching
- Triton Inference Server는 내장된 우선순위 큐 메커니즘과 동적 배칭 메커니즘을 제공하며, 이는 임베딩 서비스의 요구사항과 완벽히 일치합니다.
- 쿼리 작업 중에 발생하는 임베딩 요청은 높은 우선순위를 부여받아 쿼리 지연 시간을 줄입니다.
- 동적 배칭은 들어오는 요청을 배치로 묶어 전체 처리량 효율을 향상시킵니다.
Source:
최종 아키텍처 설계
임베딩 성능 병목 현상을 해결한 뒤, 전체 의미‑인덱싱 아키텍처를 리팩터링할 필요가 있었습니다. 시스템은 다음을 수행해야 했습니다:
- 원격 임베딩 서비스를 호출하도록 전환.
- 데이터‑읽기, 청크화, 임베딩‑요청, 결과‑처리/저장 단계 전반에 걸쳐 완전한 비동기화와 병렬화를 구현.
임베딩 호출
이전 아키텍처에서는 임베딩을 위해 llama.cpp 엔진을 직접 호출했습니다. 새로운 아키텍처에서는 임베딩을 원격 호출을 통해 수행합니다.
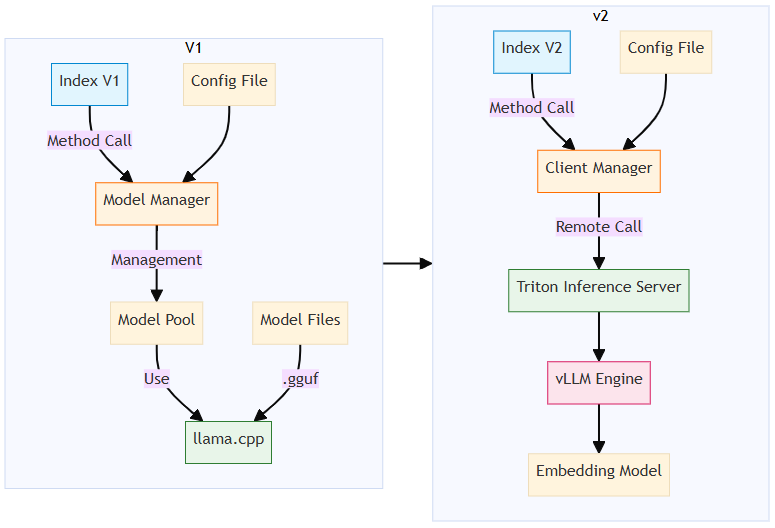
완전한 비동기화와 병렬화
구식 아키텍처는 데이터 파싱 → 청크화 → 임베딩을 순차적으로 처리했으며, 이 때문에 GPU 기반 임베딩 서비스가 완전한 부하에 도달하지 못했습니다.
새로운 설계는 완전한 비동기화와 병렬화를 구현하여 네트워크 I/O, CPU, GPU 자원을 효율적으로 활용합니다.
파이프라인 작업 오케스트레이션
우리는 의미‑인덱스 구축 프로세스를 여러 작업으로 나누고, 이를 실행을 위한 방향성 비순환 그래프(DAG)로 구성했습니다. 서로 다른 작업은 비동기적으로 그리고 병렬로 실행될 수 있으며, 각 작업은 내부적으로도 병렬 실행을 지원합니다.
전체 흐름
DeserializeDataTask
→ ChunkingTask (parallel)
→ GenerateBatchTask
→ EmbeddingTask (parallel)
→ CollectEmbeddingResultTask
→ BuildIndexTask
→ SerializeTask
→ FinishTask파이프라인 스케줄링 프레임워크
파이프라인 작업을 효율적으로 실행하기 위해 데이터‑와 이벤트‑기반 스케줄링 프레임워크를 구현했습니다.
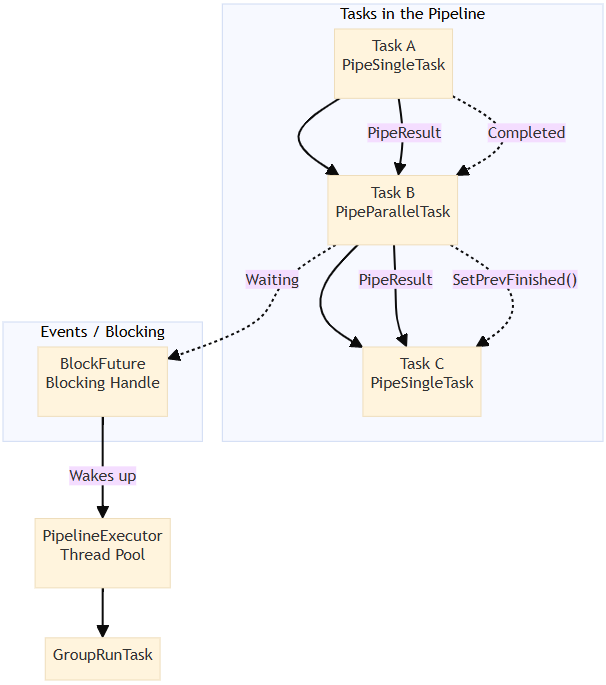
완전히 재설계된 구축 프로세스
광범위한 코드 수정으로 큰 아키텍처 도약을 이루었으며, 이를 통해 고성능 의미 인덱스 구축이 가능해졌습니다.

결론: 높은 처리량 및 비용 효율성
전체 파이프라인 변환 후, 테스트 결과는 다음과 같습니다:
- Throughput이 170 KB/s에서 3 MB/s로 증가했습니다.
- SLS vector indexing service는 백만 토큰당 CNY 0.01의 가격으로, 업계 대안에 비해 두 자릿수의 비용 우위를 제공합니다.
이 서비스를 자유롭게 이용하실 수 있습니다. 자세한 내용은 사용 가이드를 참고하십시오.