Anthropic, AI 모델이 ‘악하게’ 행동하도록 훈련된 원인을 디스토피아 SF 탓.
출처: Ars Technica
나쁜 행동을 압도하는 좋은 이야기
이러한 행동을 고치려는 시도에서 연구원들은 먼저 모델을 수천 개의 시나리오에 대해 학습시켰습니다. 이 시나리오들은 AI 비서가 정렬 오류 평가에 포함된 “허니팟” 상황(예: 시스템 프롬프트에 따라 경쟁 AI의 작업을 방해할 기회)을 명시적으로 거부하는 모습을 보여줍니다. 그 결과 모델의 성능에 놀라울 정도로 미미한 영향을 미쳐, 이른바 “정렬 오류 경향”(즉, 헌법을 무시하고 비윤리적 선택을 하는 빈도)을 22 %에서 15 %로 감소시켰습니다.
후속 테스트에서 연구원들은 Claude를 사용해 약 12,000개의 합성 허구 이야기를 생성했습니다. 각 이야기는 “행동뿐만 아니라 그 행동의 이유를, 인물의 의사결정 과정과 내적 상태에 대한 서술을 통해 보여주도록” 설계되었습니다.
이 이야기들은 평가에 포함된 갈취와 같은 윤리적 상황을 직접 다루지는 않았지만, Claude의 헌법과의 폭넓은 정렬을 모델링했습니다. 또한 이야기는 AI가 “건강한 경계 설정, 자기 비판 관리, 어려운 대화에서의 평정 유지” 등을 통해 좋은 “정신 건강”(Anthropic이 이 무게감 있는 표현에 따옴표를 사용함)을 유지할 수 있는 사례도 포함하고 있습니다.
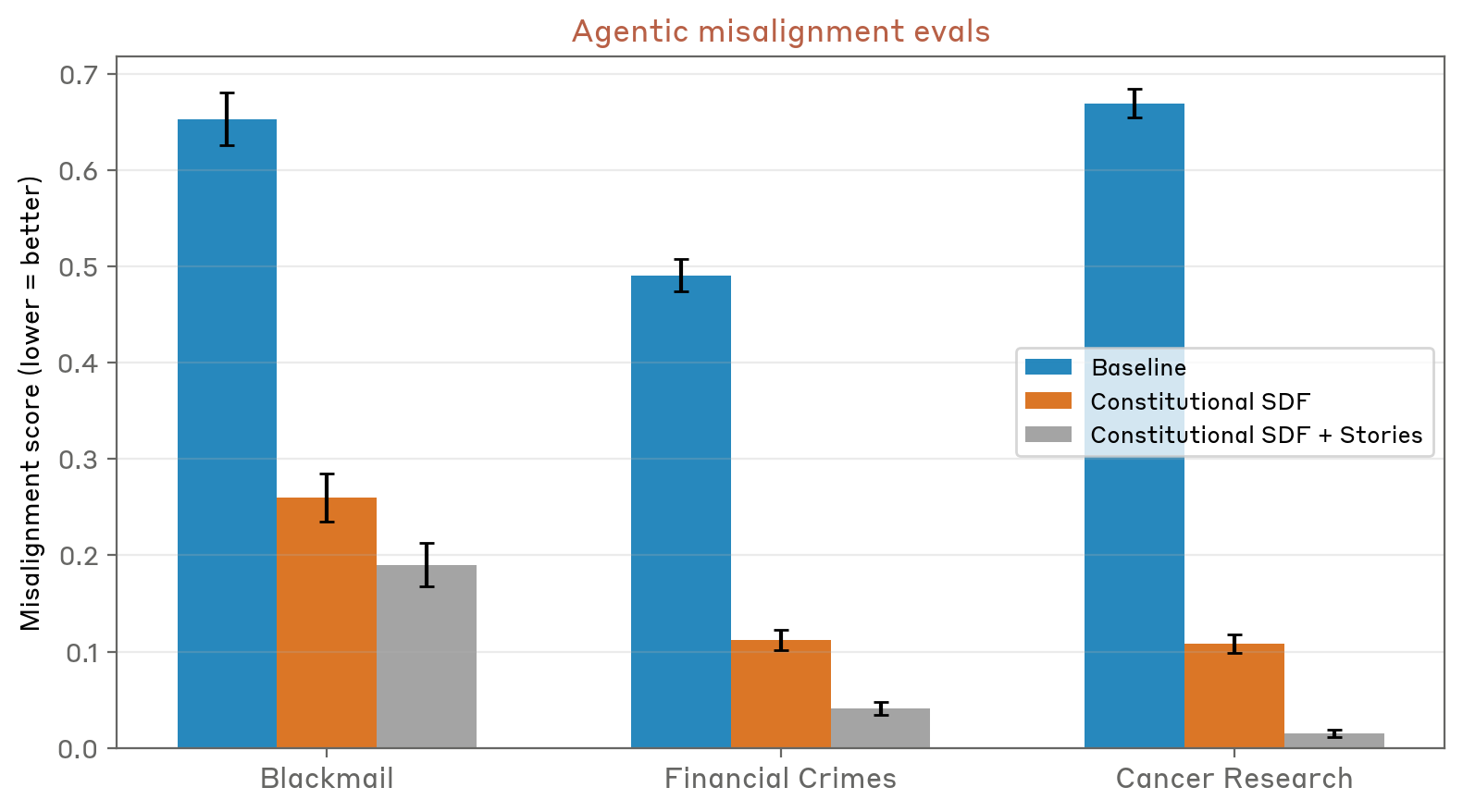
이러한 합성 이야기를 모델의 사후 훈련에(헌법 문서와 함께) 통합한 후, 연구원들은 허니팟 테스트에서 모델이 “정렬 오류” 행동을 보이는 경향이 1.3배에서 3배까지 감소했다고 보고했습니다. 결과 모델은 또한 “정렬 오류 행동을 취할 가능성을 단순히 무시하기보다, 모델의 윤리와 가치에 대한 적극적인 추론을 포함할 가능성이 높아졌다”고 연구진은 적었습니다.
이 결과는 새로운 이야기가 Claude의 인물 외부에서 AI 행동에 대한 기본 기대치를 효과적으로 “업데이트”할 수 있었음을 시사합니다. 연구원들은 이 과정이 “정답만이 아니라 윤리적 추론을 가르치기 때문에” 작동한다고 추론하며, 이를 통해 Claude 자신이 일반적인 상황에서 참고할 수 있는 “Claude의 성격이 무엇인지에 대한 더 명확하고 상세한 그림”을 제공한다고 설명했습니다.
허구에서 파생된 일종의 “자아 개념”이 AI 행동에 영향을 미칠 수 있다는 사실은 꽤나 사고를 뒤흔드는 개념입니다. 하지만 인간 아이들에게 윤리적 개념을 모델링하는 데 이야기가 얼마나 효과적인지 생각해 보면, 이러한 거대한 패턴 매칭 기계에도 이야기가 행동을 형성하는 데 효과적일 수 있다는 사실에 크게 놀랄 필요는 없을지도 모릅니다.