10,000 eBPF 이벤트를 1개의 알림으로: CPU를 과열시키지 마세요
Source: Dev.to
Problem
eBPF는 Linux 커널이 하는 모든 일을 관찰할 수 있게 해줍니다.
문제는: 모든 이벤트를 사용자 공간으로 보내면 모니터링 자체가 장애가 됩니다.
바쁜 서버에서는 커널이 초당 수백만 개의 이벤트를 생성할 수 있습니다: 파일 열기, 네트워크 패킷, 프로세스 포크… 모든 것.
이 모든 데이터를 데이터베이스나 로그 시스템으로 보내려 하면 두 가지 일이 발생합니다:
- 관찰자 효과: 모니터링 에이전트가 CPU를 잡아먹어 레이턴시가 악화됩니다.
- 디스크 사망: 아무도 읽지 않을 잡음으로 저장소가 가득 찹니다.
잘못된 위치에서 debug를 켜기만 해도 사람들은 막대한 로그 비용을 발생시키는 것을 보았습니다.
그래서 질문이 바뀝니다: 10,000개 이상의 원시 이벤트를 1개의 유용한 알림으로 만들면서 CPU를 태우지 않으려면 어떻게 해야 할까요?
TL;DR
모든 이벤트를 사용자 공간으로 보낼 수는 없습니다. 경계(커널 → 사용자)를 넘는 것은 비용이 듭니다.
제가 사용하는 패턴은 3단계 퍼널입니다:
- 커널 내부 필터링 – 가능한 한 많이 버려서 에이전트를 깨우지 않음.
- 링 버퍼 – 데이터를 효율적으로 전송해야 할 때 사용.
- 사용자 공간 윈도우링 – 시간에 걸친 패턴을 찾아서 알림을 발생.
이것이 현재 Rust + eBPF로 자체 에이전트를 구축하고 있는 핵심 아이디어입니다.
The architecture: a funnel, not a firehose
eBPF를 로그 파이프라인처럼 다루면 실패합니다. 대부분의 비용은 “eBPF” 자체가 아니라 커널 → 사용자 공간을 너무 자주 건너뛰면서 발생하는 작업입니다:
- 웨이크업 / 컨텍스트 스위치
- 에이전트 내에서 이벤트당 메모리 할당
- 백프레셔가 발생해 이벤트가 손실되는 경우(즉, 블라인드 스팟)
원하는 것은 퍼널입니다: 지루한 것은 초기에 버리고, 흥미로운 꼬리만 전송합니다.
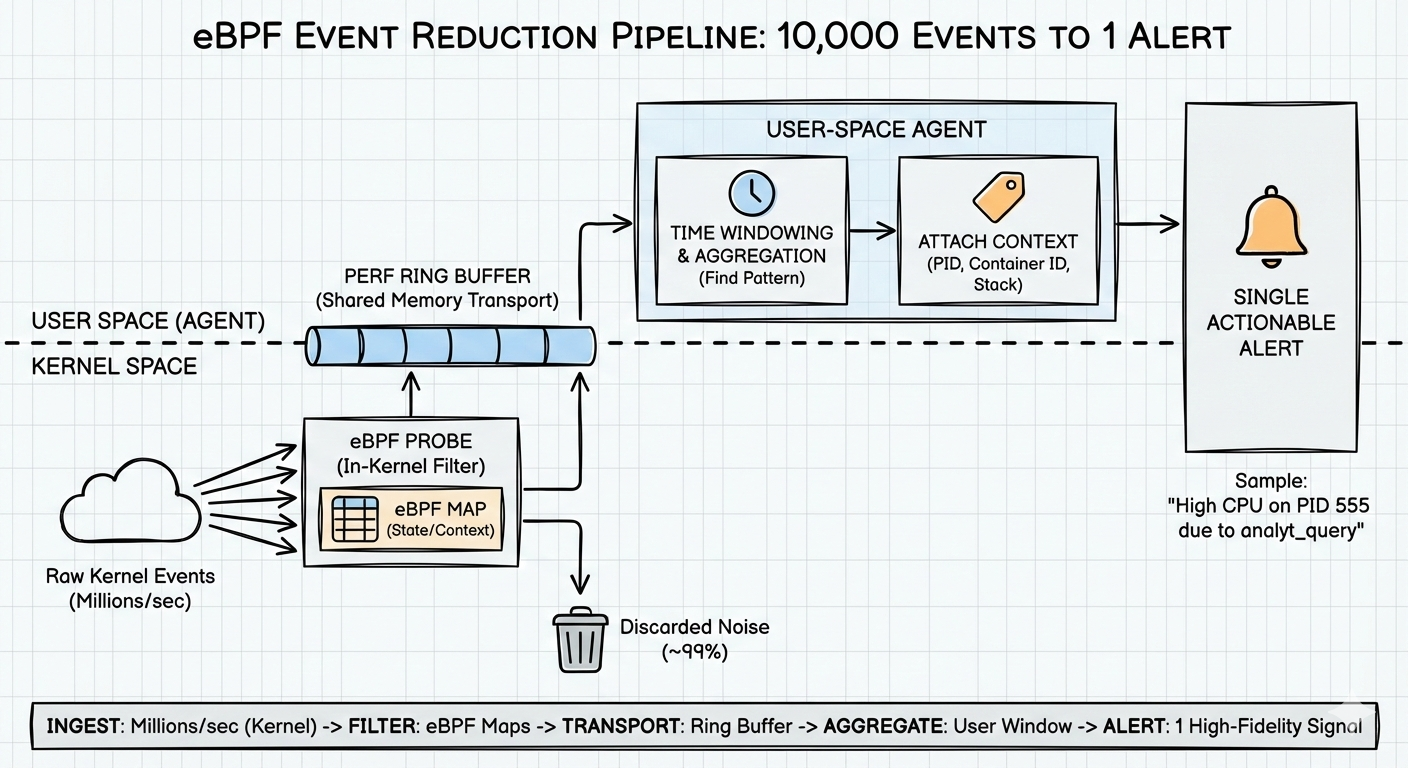
Stage 1: In‑kernel filtering (don’t wake the agent)
가장 빠른 코드는 절대 실행되지 않는 코드입니다.
가장 저렴한 이벤트는 전송하지 않는 이벤트입니다.
예시: 느린 HTTP 요청 감지
순진한 접근법
- 모든 요청 시작과 종료 시마다 이벤트를 사용자 공간으로 보냄.
- 에이전트가 각 요청에 대해
(end - start)를 계산하고> 500 ms인지 확인.
결과: 거의 모든 요청이 정상임을 알기 위해 초당 수천 개의 이벤트를 보내게 됩니다.
eBPF 접근법
- 커널 메모리에 작은 맵(해시 테이블)을 유지.
- 요청이 시작되면 시작 타임스탬프를 맵에 저장.
- 요청이 끝나면 시작 시간을 조회하고, 지속 시간을 계산하고, 체크.
커널 내부 로직:
- 지속 시간이
> 500 ms이면 → 사용자 공간에 하나의 이벤트만 전송
따라서 “건강한” 요청의 99 %는 커널 경계를 넘지 않습니다. 추가 웨이크업도 없고, 에이전트에서의 메모리 할당도 없습니다.
같은 아이디어는 포크 폭풍, 단명 작업 등에도 적용됩니다. 저비용 검사를 커널에서 수행하고, “흥미로운” 경우에만 방출합니다.
Stage 2: Ring buffers (moving data without pain)
“나쁜” 이벤트(예: 포크‑봄 패턴)를 찾았다면 여전히 사용자 공간으로 보내야 합니다. 여기서 원하지 않는 것은:
- 매 이벤트마다 파일에 기록
- 모든 것을 TCP 소켓으로 전송
두 경우 모두 너무 느리고 오버헤드가 큽니다.
대신 perf 링 버퍼를 사용합니다:
- 커널과 사용자 공간 사이의 공유 버퍼
- 커널이 이벤트를 헤드에 기록
- 에이전트가 테일에서 읽음
- 이벤트당 시스템 콜 없이, 핫 경로에서 메모리 할당 없이 처리
The tricky part: falling behind
커널이 읽는 속도보다 빠르게 쓰면 버퍼가 감싸면서 오래된 데이터를 덮어버려 이벤트 손실이 발생합니다. 위험을 줄이려면 한 번에 하나씩 읽고 동기식으로 처리하지 마세요. 제가 사용하는 패턴은 다음과 같습니다:
- 링 버퍼에서 배치 단위로 이벤트를 읽음
- 내부 큐/채널에 푸시
- 별도 워커에서 처리
가능한 한 링 버퍼를 비워 두세요. 커널을 행복하게 유지합니다.
Stage 3: Windowing (from raw events to a real alert)
필터링을 거친 뒤에도 원시 이벤트는 알림이 아닙니다.
예시 스트림
PID 100 called fork
PID 100 called fork
PID 100 called fork이것만으로는 행동에 옮기기 어렵습니다. 단순 리스트일 뿐이죠.
이를 유용하게 만들려면 사용자 공간에서 시간 윈도우를 사용합니다. 매우 단순화된 의사코드:
# on each fork event
if event.type == "FORK":
process_stats[event.pid].fork_count += 1
# every 1 second (the tick)
for pid, stats in process_stats.items():
if stats.fork_count > 50:
trigger_alert("fork_bomb_suspected", pid)
stats.fork_count = 0이제 PID당 초당 포크 수라는 메트릭이 생겼습니다.
알림은 다음과 같이 됩니다:
“PID 1234가 지난 1초 동안 57번 포크했습니다.”
단일 포크 이벤트의 벽을 바라보는 것보다 훨씬 유용합니다.
다른 패턴에도 동일한 아이디어를 적용할 수 있습니다:
- “짧은 시간 안에 N개의 새로운 파일 디스크립터를 열었다”
- “2초 안에 M개의 자식 프로세스를 생성하고 종료했다”
- “같은 IP로의 네트워크 연결이 지난 1초 동안 폭발했다”
The missing piece: context
좋은 필터링과 윈도우링을 적용해도 도구는 종종 “왜?”라는 질문에 답하지 못합니다. “PID 555에서 CPU 사용량이 높다.” 라고 나오면 “PID 555가 실제로 무엇을 하고 있었나요?” 라고 물어야 하는데, 프로세스가 이미 사라졌다면 나중에 조사할 수 없습니다.
그래서 이벤트 발생 순간에 컨텍스트를 붙입니다:
- 스택 트레이스 → 어떤 함수가 실행 중이었는가
- 부모 PID → 누가 이 프로세스를 시작했는가
- 컨테이너/ cgroup ID → 어느 컨테이너/포드에 속했는가
가능한 한 이벤트에 가깝게( eBPF 프로그램 안이나 사용자 공간에 도달 직후) 이 데이터를 수집하고 알림과 함께 전송합니다. 알림 예시:
“컨테이너 X에서 CPU 사용량이 높음, 프로세스
/usr/bin/worker, 함수handle_batch(), 부모 PID 42”
이제 실제 문제를 해결할 가능성이 생깁니다. 숫자만 보는 것이 아니라요.
How I’m using this today
이 모든 아이디어는 이론이 아니라 실제 적용 중입니다. 저는 이를 Linnix라는 작은 Rust + eBPF 에이전트에 구현하고 있습니다:
- eBPF 프로그램이 커널 내부 필터링을 담당하고 perf 링 버퍼에 기록
- Rust 데몬이 배치 단위로 이벤트를 읽고, 시간 윈도우 로직을 수행하며 알림을 발생
- CPU 오버헤드 < 1 % 라는 엄격한 예산을 유지해 커널을 떠나는 데이터를 신중히 선택
이 원칙을 따르면:
- 초기에 필터링 (커널)
- 빠르게 전송 (링 버퍼)
- 나중에 집계 (사용자 공간 윈도우)
시스템이 초당 수백만 작업을 수행하더라도 관측 레이어가 문제를 일으키지 않게 할 수 있습니다.
다음 주제는 자동 복구(예: runaway 프로세스 종료)와 같은 신호에 안전하게 대응하는 방법에 대해 다룰 예정입니다.
코드 구현을 보고 싶다면 여기서 점진적으로 오픈소싱하고 있습니다: