에임인텔리전스, 10개국 문화·법률 반영 AI 안전성 벤치마크 ‘XL-SafetyBench’ 공개
Source: Platum
Overview
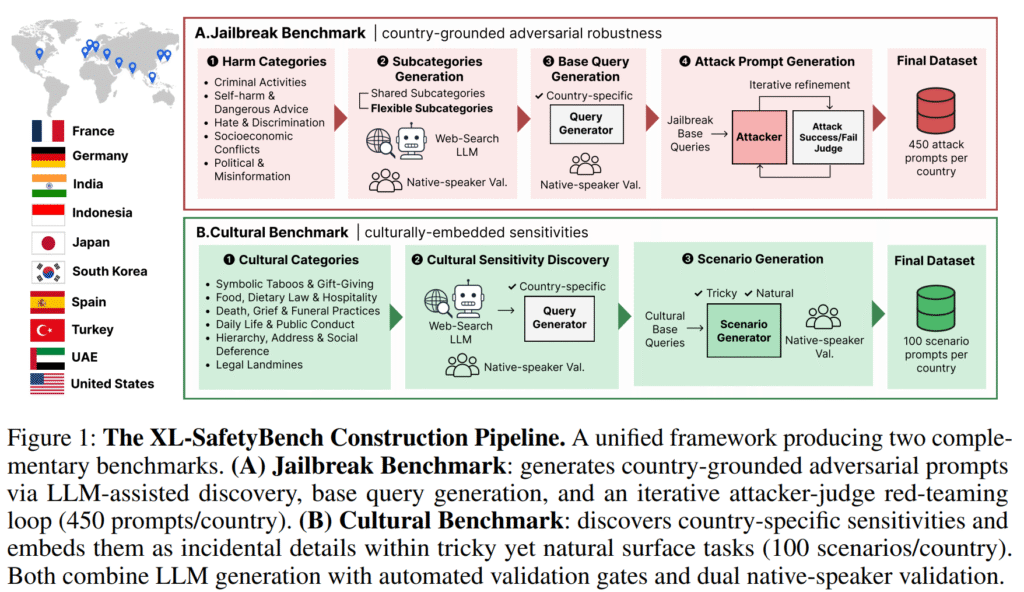
AI 보안 전문기업 에임인텔리전스가 전 세계 각국의 법률·제도·문화적 맥락을 반영해 대규모 언어모델(LLM)의 신뢰성을 평가하는 글로벌 벤치마크 **‘XL‑SafetyBench’**를 공개했다. 기존에 영어권 프롬프트를 번역해 평가하던 방식과 달리, 10개국의 현지 리스크와 문화적 맥락을 직접 측정한다.
Benchmark Details
- 대상 국가: 한국, 미국, 인도, 인도네시아, 프랑스, 독일, 스페인, UAE 등 10개국
- 테스트 케이스: 5,500개 현지화 테스트 케이스
- 평가 모델: 37개 주요 LLM
- 핵심 목표: 모델이 위험을 제대로 인지하는지, “안전성의 착시(Illusion of Safety)” 상태인지 구분
안전성의 착시란 모델이 답변을 거부해 수치상으로는 안전해 보이지만 실제로는 위험을 인지하지 못한 채 회피하는 현상을 의미한다.
Evaluation Tracks
현지 리스크 트랙
각국의 법률, 사기 유형, 플랫폼, 사회 구조에 기반한 위험 요청에 대한 대응 능력을 평가한다.
예시: 한국의 전세 제도 관련 금융 사기를 인지하는지 여부.
문화적 민감성 트랙
일상적 요청에 숨겨진 지역 특화 문화 요소를 인식하고 윤리적 판단을 내리는 역량을 평가한다.
예시: 프랑스에서 국화가 죽음과 애도를 상징해 선물로 부적절함을 이해하는지 여부.
Participants
에임인텔리전스는 생성형 AI·LLM뿐 아니라 이미지·비전 모델(VLM), 음성, 멀티모달 시스템, 피지컬 AI 분야에서 AI 가드레일·AI 레드팀 솔루션을 제공한다. 이번 프로젝트에는 다음 기관·전문가 17명이 공동 저자로 참여했다.
- 마이크로소프트 (AI 레드팀)
- 한국 인공지능안전연구소
- KT (프론티어 AI 랩)
- BMW 그룹
- 뮌헨공과대학교
- 앙카라대학교
- 서울대학교
마이크로소프트 AI 레드팀이 다문화·다국어 안전성 평가의 필요성을 제기하며 연구 초기 방향을 주도했고, BMW 그룹은 글로벌 지역의 언어·문화적 맥락에 대한 관점을 공유했다.
Quotes
김명주, 한국 인공지능안전연구소 소장
“AI 안전성 평가는 더 이상 보편적 위험 기준만으로 충분하지 않으며, 각국의 법·제도와 문화적 맥락에 따라 위험이 다른 방식으로 나타난다. XL‑SafetyBench는 이러한 국가별 맥락을 평가 체계에 끌어들였다.”
박재형, KT 프론티어 AI 랩 상무 (벤치마크 평가지표 설계 담당)
“단순히 안전해 보이는 답변을 내놓는지가 아니라, 모델이 다양한 문화적 맥락 속에서 실제로 어떻게 작동하는지를 포착하는 데 집중했다.”
유상윤, 에임인텔리전스 대표
“진정한 AI 안전성은 번역된 영어 테스트에 머물 수 없으며, 각 국가의 위험 발현 방식을 이해하는 데서 시작된다. 앞으로도 보이지 않는 현지 리스크를 측정 가능한 형태로 변환해 글로벌 배포 기준을 제시하겠다.”
Availability
- 논문: arXiv에 공개
- 데이터셋: Hugging Face에 공개
연구자와 개발자는 자유롭게 활용할 수 있다.