Who Audits the Auditors? Building an LLM-as-a-Judge for Agentic Reliability
Source: Dev.to
Before you Begin
Prerequisites: An existing agentic workflow (see the MCP Forensic Series) and a high‑reasoning model (Claude 3.5 Opus or GPT‑4o) to act as the Judge.
1. The “Golden Dataset”
Before we can grade the agents, we need an Answer Key. Create tests/golden_dataset.json; it contains the “Ground Truth”—scenarios where we know there are errors.
{
"test_id": "TC-001",
"input": "The Great Gatsby, 1925",
"expected_finding": "Page count mismatch: Observed 218, Standard 210",
"severity": "high"
}Director’s Note: In an enterprise setting, “Reliability” is the precursor to “Permission.” You won’t get budget to scale agents until you can prove they won’t hallucinate $50k errors. This framework supplies the data needed for that internal sell.
2. The Judge’s Rubric
A good Judge needs a rubric beyond a simple “Yes/No.” We grade on:
- Precision: Did it find only the real errors?
- Recall: Did it find all the real errors?
- Reasoning: Did it explain why it flagged the record?
3. Refactoring for Resilience
We eliminated a common “senior‑level” trap: hard‑coding agent logic. System prompts were moved from the Python client into a dedicated config/prompts.yaml. Decoupling Instructions from Execution improves observability and lets us A/B test different prompt versions against the Judge to see which yields the highest accuracy for specific models.
4. The Implementation: The Evaluation Loop
We added evaluator.py to the repo (GitHub link). It not only runs the agents but also monitors their “vital signs.”
- Error Transparency: Swallowed exceptions were replaced with structured logging. If a provider fails, the incident is logged for diagnosis instead of failing silently.
- The Handshake: The loop runs the Forensic Team, collects their logs, and submits the whole package to a high‑reasoning Judge Agent.
The Evaluator‑Optimizer Blueprint
This diagram illustrates the shift from “Does the code run?” to “Does the intelligence meet the quality bar?” The closed‑loop system is required before we can start fiscal optimization by choosing smaller models for simpler tasks.
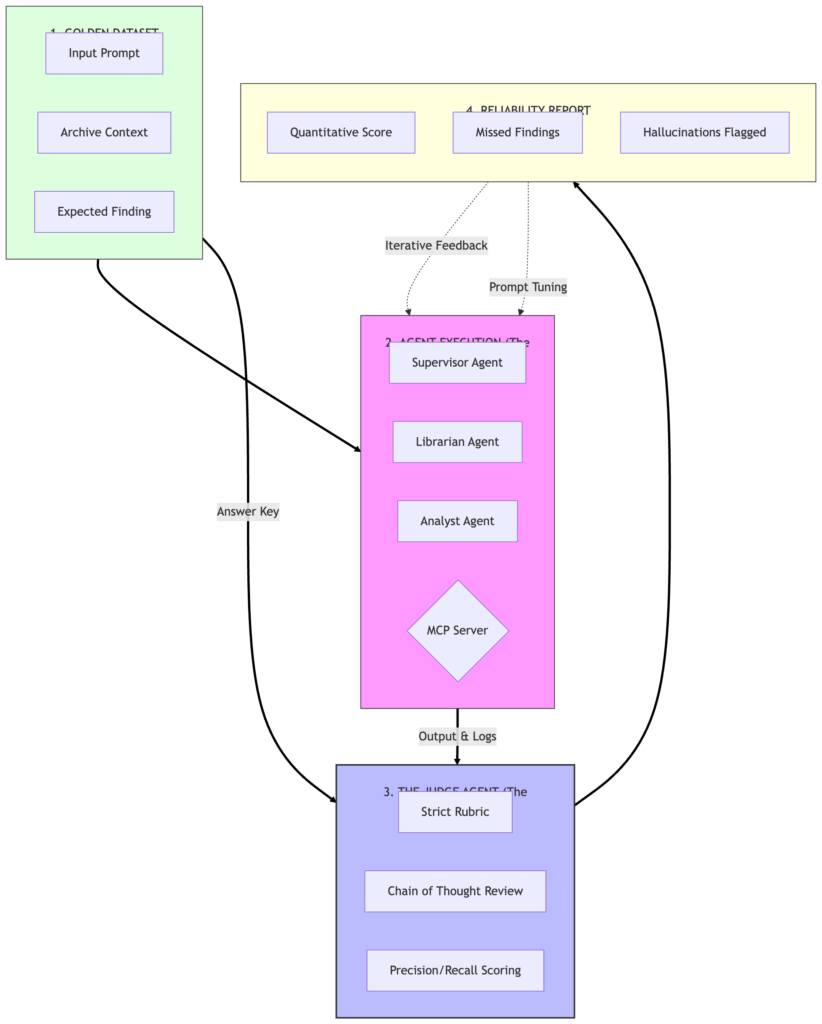
Director‑Level Insight: The “Accuracy vs. Cost” Curve
As a Director, I care about more than “cost per token.” I need defensibility. If a forensic audit is challenged, I must show a historical accuracy rating. Implementing this Evaluator moves us from “vibe‑checking” to a quantitative reliability score, allowing us to set a Minimum Quality Bar for deployment. If a model update or prompt change drops accuracy by 2 %, the Judge blocks the deployment.
The Production‑Grade AI Series
- Post 1: The Judge Agent — You are here
- Post 2: The Accountant (Cognitive Budgeting & Model Routing) — Coming Soon
- Post 3: The Guardian (Human‑in‑the‑Loop Handshakes) — Coming Soon
Looking for the foundation? Check out the previous series: The Zero‑Glue AI Mesh with MCP.