When protections outlive their purpose: A lesson on managing defense systems at scale
Source: GitHub Blog
Maintaining Platform Availability
The Problem
Sometimes, protections that were added as emergency responses can outlive their usefulness and start blocking legitimate users. This typically happens when rapid incident response requires broader controls that aren’t intended to be permanent.
What We Learned
- Outdated mitigations can degrade the user experience.
- Observability is as critical for defenses as it is for features.
- Prompt feedback from users is vital for identifying and removing stale protections.
Our Apology
We’re sorry for the disruption. We should have detected and removed these protections sooner.
Next Steps
- Review and retire any emergency mitigations that are no longer needed.
- Enhance monitoring to catch unintended side‑effects of defensive controls.
- Continue gathering user feedback to ensure our defenses remain transparent and effective.
What Users Reported
We saw reports on social media from people receiving “Too many requests” errors during normal, low‑volume browsing—for example, when following a GitHub link from another service or app, or simply browsing without any obvious pattern of abuse.
Users encountered a “Too many requests” error during normal browsing.
These were users making a handful of normal requests that hit rate limits which should not have applied to them.
What We Found
Investigating the reports revealed the root cause: protection rules added during past abuse incidents were left in place. These rules were created from patterns that, at the time, were strongly associated with abusive traffic. Unfortunately, the same patterns also matched some logged‑out requests from legitimate clients.
Composite Signals & False Positives
- The patterns combine industry‑standard fingerprinting techniques with platform‑specific business logic.
- Composite signals can occasionally produce false positives.
Key Statistics
| Metric | Value |
|---|---|
| Requests that matched the suspicious fingerprints and were blocked | 0.5 % – 0.9 % (only when they also triggered business‑logic rules) |
| Requests that matched both criteria | 100 % blocked |
| False‑positive rate relative to total traffic | 0.003 % – 0.004 % (≈ 3‑4 per 100 k requests) |
Note: Only fingerprint matches that also satisfied business‑logic patterns resulted in a block.
Visual Summary
| Description | Image |
|---|---|
| Percentage of fingerprint matches that were blocked (0.5‑0.9 % over 60 min) | 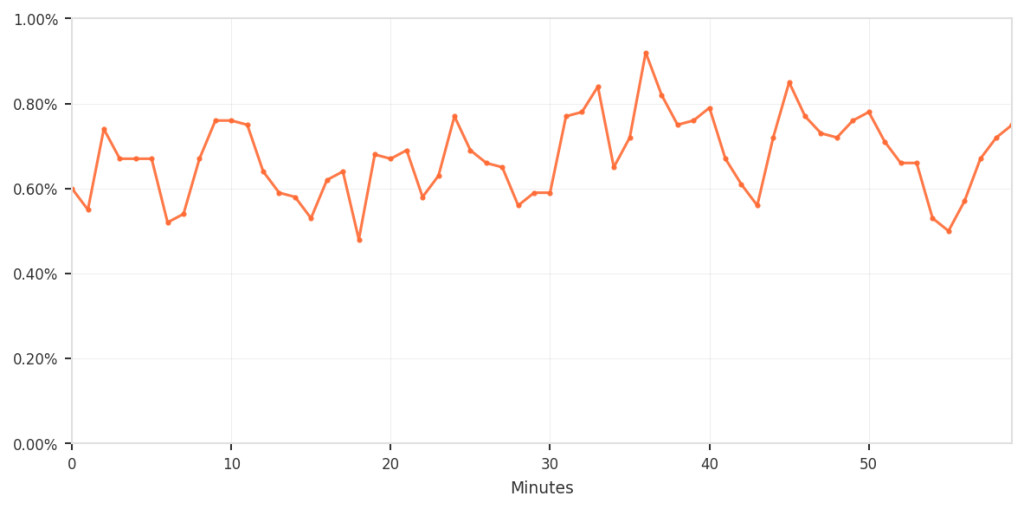 |
| False positives as a share of total traffic (0.003‑0.004 %) | 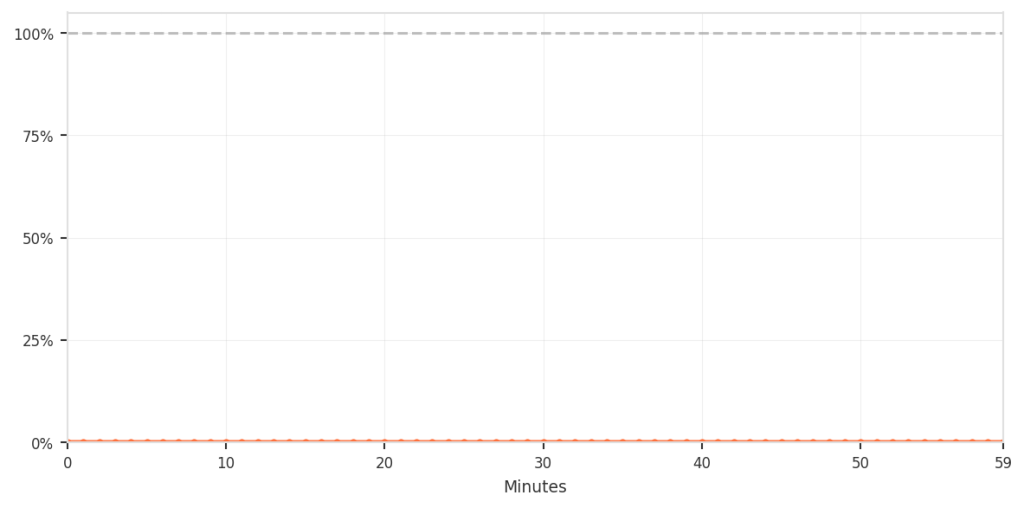 |
| Zoom‑in on the false‑positive pattern over time | 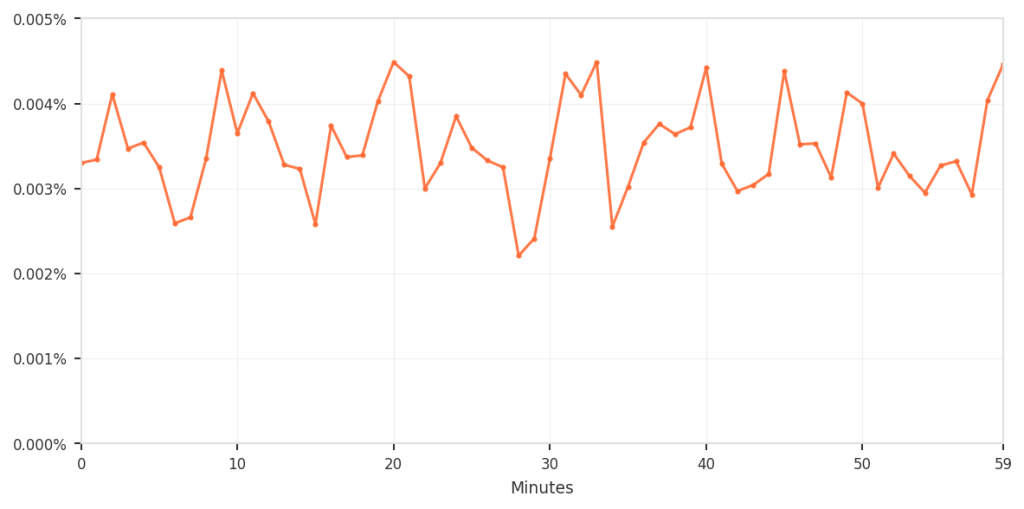 |
Although the percentages are low, any incorrect blocking disrupts real users and is therefore unacceptable.
Why Temporary Mitigations Can Become Permanent
During an active incident we must act quickly, often accepting trade‑offs to keep the service available. Emergency controls are correct at that moment, but they do not age well as threat patterns evolve and legitimate usage changes. Without active maintenance, temporary mitigations become permanent and their side effects compound silently.
Tracing Through the Stack
When users reported errors, we traced the requests across multiple infrastructure layers to pinpoint where the blocks occurred.
Multi‑Layer Protection Overview
GitHub’s custom, multi‑layered protection infrastructure (built on open‑source projects like HAProxy) applies defenses at several points:
- Edge tier – DDoS protection, IP reputation, rate limits.
- Application tier – Authentication, per‑user/service rate limits.
- Service tier – Business‑logic validation, feature‑specific throttling.
- Backend tier – Resource‑level quotas, internal safety checks.
Diagram (simplified to avoid disclosing specific mechanisms):
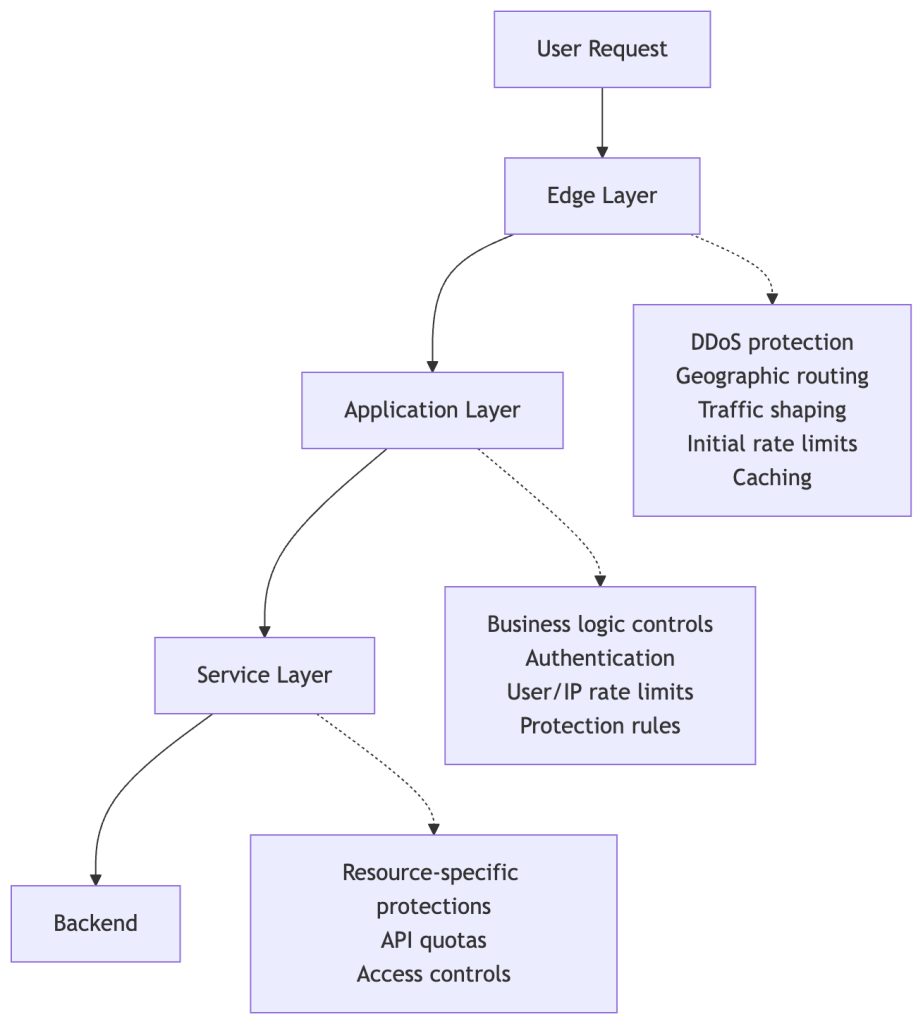
Each layer can independently block or rate‑limit a request. Determining which layer performed the block requires correlating logs that have different schemas.
Investigation Steps
| Step | Source | What We Looked For |
|---|---|---|
| 1️⃣ | User reports | Timestamps, error messages, observed behavior |
| 2️⃣ | Edge tier logs | Arrival of the request at the front‑end |
| 3️⃣ | Application tier logs | HTTP 429 “Too Many Requests” responses |
| 4️⃣ | Protection rule analysis | Which rule(s) matched the request |
By moving backward from the user‑visible error to the underlying rule configuration, we confirmed that the lingering mitigation rules were the source of the false positives.
Lifecycle of Incident Mitigations
The following diagram illustrates how a mitigation can outlive its usefulness:

What Went Wrong
- Controls were added during an incident and functioned as intended.
- No expiration dates, post‑incident reviews, or impact monitoring were applied.
- Over time the rules became technical debt, eventually blocking legitimate traffic.
Recommended Practices
- Set explicit expiration dates for any emergency rule.
- Conduct post‑incident reviews to assess ongoing impact.
- Automate impact monitoring (e.g., alert on unexpected block rates).
- Document ownership so the responsible team can retire or adjust rules.
Applying these practices ensures that temporary defenses remain temporary and that legitimate users are not inadvertently impacted.
What We Did
- Reviewed the mitigations – compared what each rule is blocking today with its original intent.
- Removed outdated rules – eliminated any protections that no longer serve a purpose.
- Retained essential safeguards – kept the controls that continue to defend against ongoing threats.
What We’re Building
Beyond the immediate fix, we’re improving the lifecycle management of protective controls:
- Better visibility across all protection layers to trace the source of rate limits and blocks.
- Treat incident mitigations as temporary by default; making them permanent should require an intentional, documented decision.
- Post‑incident practices that evaluate emergency controls and evolve them into sustainable, targeted solutions.
Defense mechanisms— even those deployed quickly during incidents—need the same care as the systems they protect. They require observability, documentation, and active maintenance. When protections are added during incidents and left in place, they become technical debt that quietly accumulates.
Thanks to everyone who reported issues publicly! Your feedback directly led to these improvements. And thanks to the teams across GitHub who worked on the investigation and are building better lifecycle management into how we operate. Our platform, team, and community are better together!
Tags
- developer experience
- incident response
- Infrastructure
- observability
- site reliability
Written by
Thomas Kjær Aabo – Engineer on the Traffic team at GitHub.

Explore More from GitHub
| Docs – Everything you need to master GitHub, all in one place. | |
| GitHub – Build what’s next on GitHub, the place for anyone from anywhere to build anything. | |
| Customer stories – Meet the companies and engineering teams that build with GitHub. | |
| The GitHub Podcast – Catch up on the podcast covering topics, trends, stories, and culture in the open‑source developer community. |