Optimizing Vector Search
Source: Dev.to
Author Introduction
I am Mansi Tibude, an Electronics and Communication Engineer. I have worked in the IT industry for about three years as a Systems Engineer in a previous organization. I have experience with various technologies and consistently delivered results on time. I am a hard‑working, smart worker who can quickly learn new technologies and apply them to build real‑time applications.
Abstract
Vector search is an AI‑powered search technique that offers more advanced features than traditional text search. It can retrieve results not only for text but also for audio, video, and images.
Elasticsearch has a major advantage over other search engines: it provides hybrid search, a combination of semantic search and vector search, delivering more accurate results up to 10× faster. Vector search returns results as vector data rather than plain text, which is beneficial for storing user searches in a tabular format.
We already know many features of Elasticsearch and how it differs from other search engines, but the Blogathon challenge asks us to explore how we can add more features and innovate within the built‑in Elasticsearch engine—especially in the areas of Vector Search, Hybrid Search, and Semantic Search using the ELK stack.
Content Body
Why Vector, Hybrid, and Semantic Search Matter
Vector, hybrid, and semantic search play a major role in delivering results that match user expectations. However, we often need to increase accuracy while adding more capabilities to the search query. In vector search, query results are stored and returned in vector format.
Key question: How can we scale up vector search, especially hybrid search?
Scaling Strategies
- Hybrid scaling – combines multiple scaling techniques.
- Vertical scaling – adds more resources (CPU, memory, storage) to a single node.
Vector search works by:
- Converting documents and queries into vectors (embeddings).
- Storing those vectors to enable efficient vector mathematics.
- Performing fast similarity calculations using various matching functions.
The K‑Nearest Neighbor (KNN) machine‑learning model powers vector searching, while Retrieval‑Augmented Generation (RAG) converts data into numerical vectors. Re‑ranking algorithms then reorder results to improve relevance.
Role of a Vector Database
A vector database is a highly efficient store for high‑dimensional vectors. Its main benefits are:
- Scalability
- Indexing and search performance
- Hybrid‑search support
- Tech‑stack integration
Vector Search Specifications
- Manual configuration
- Self‑embedding (on‑the‑fly generation of embeddings)
- Direct similarity matching on vectors
How vector search works:
- Embedding generation – AI models encode raw data into embeddings.
- Indexing – Embeddings are indexed as vectors.
- Search – The engine matches query vectors against stored vectors, understanding context to return relevant results.
Challenges Overcome by Vector Search
- Semantic understanding – grasps the intent behind queries.
- Multi‑modal capabilities – handles text, audio, video, and images.
- Personalization & recommendations – tailors results to individual users.
Vector Database Overview
A vector database stores high‑dimensional vectors and provides the following features:
- Scalability – handles growing data volumes.
- Efficient indexing & search performance
- Hybrid‑search support (combining keyword and vector queries)
- Seamless integration with existing tech stacks
Scaling Elasticsearch for Vector Search
Elasticsearch can support three primary search types:
- Index & basic search
- Keyword search (e.g., via Python)
- Semantic search
- Vector search
- Hybrid search
Our focus is optimizing vector search. Below are the two main scaling approaches.
Vertical Scaling
Increase the resources of a single Elasticsearch node:
- Add more CPU cores
- Use faster storage (SSD, NVMe)
- Implement caching layers
- Optimize processing pipelines
Caching mechanisms for vector search:
- Storage‑level caching – caches indexed vectors on disk.
- Embedding caching – stores pre‑computed embeddings.
- Query‑level caching – reuses results of identical queries.
- LLM output caching – caches large‑language‑model responses.
Additional options:
- Deploy TPUs or specialized AI accelerators.
- Optimize ML models for lower latency.
Horizontal Scaling
Distribute the workload across multiple nodes and shards:
- Increase the number of data nodes.
- Add shards to spread vector data.
- Leverage a micro‑services‑style architecture to balance load.
Horizontal‑scaling tactics:
- Node scaling – add more Elasticsearch nodes to the cluster.
- Shard scaling – create additional primary and replica shards for better parallelism.

Optimizing vector search improves search efficiency, delivers faster results, and better manages the data collected from user interactions.
Real‑World Applications
Docusign
- Domain: Intelligent Agreement Management (IAM)
- Scale: Millions of users
- Use case: Fast, semantic retrieval of contract clauses, signatures, and related documents across multiple modalities (text, PDF, scanned images).
Businesses create, manage, and analyze contracts. Before the introduction of IAM, users searched across multiple platforms to locate agreements.
Docusign & Vector Search
Docusign uses Elasticsearch together with vector search to handle the billions of new agreements it receives every day and to deliver quick results to its customers.
Vector‑search built on Elasticsearch technology has innovated searching. The search input can be text, image, keywords, audio, or video. We can also add a feature that extracts context from handwriting and artworks (e.g., paintings) to understand their meaning and return relevant results.
Natural Language Processing (NLP) can be used to extract context from handwriting and artworks, providing both desired and near‑similar results.
Optimizing and Adding More Features to Vector Search
Vector‑search basic designs use various technologies, including semantic search, vector databases, Elasticsearch, and more. We can add two additional features to the vector‑search criteria that will be beneficial for other kinds of inputs as context for searching.
Modified Architecture Design
The diagram below illustrates the modified vector‑search architecture, which now accepts images, audio, video, handwriting, and artwork as inputs.
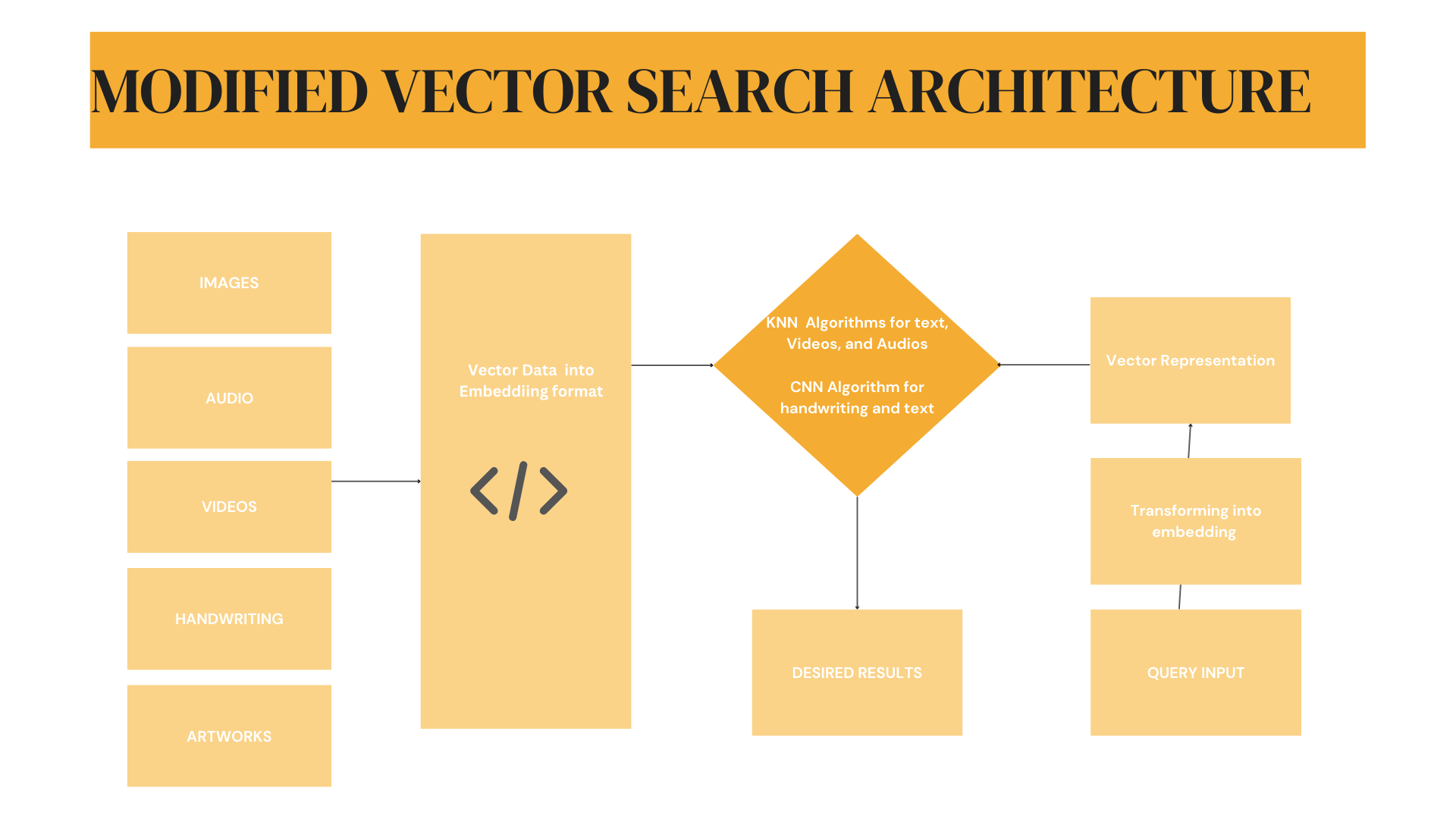
- Images, audio, and video → processed with K‑Nearest Neighbors (KNN)
- Handwriting and artwork → processed with Convolutional Neural Networks (CNN), a component of NLP pipelines
Conclusion / Takeaways
- Vector search and semantic search transform the search experience by handling millions of queries efficiently.
- Semantic search improves results by incorporating richer contexts (text, audio, video) and delivering them faster than traditional search engines.
- Search queries are stored as vector data, which can be leveraged to train machine‑learning models.
- Elasticsearch has not only revolutionized search criteria but also provides more contextual results.
Disclosure: This blog was submitted as part of the Elastic Blogathon.