New SemiAnalysis InferenceX Data Shows NVIDIA Blackwell Ultra Delivers up to 50x Better Performance and 35x Lower Costs for Agentic AI
Source: NVIDIA AI Blog
NVIDIA Blackwell Ultra: Accelerating Agentic AI and Coding Assistants
The NVIDIA Blackwell platform has already been widely adopted by leading inference providers—including Baseten, DeepInfra, Fireworks AI, and Together AI—to cut the cost per token by up to 10× (source).
Now, the NVIDIA Blackwell Ultra platform is extending that momentum to agentic AI.
Why Agentic AI & Coding Assistants Matter
- Explosive growth in software‑programming‑related AI queries: from 11 % to ~50 % of total AI traffic last year (source).
- These workloads demand:
- Low latency for real‑time responsiveness across multi‑step workflows.
- Long context windows to reason over entire codebases.
Performance Breakthroughs
New data from SemiAnalysis InferenceX demonstrates the impact of NVIDIA’s end‑to‑end optimizations:
| Metric | NVIDIA Blackwell Ultra (GB300 NVL72) | NVIDIA Hopper (baseline) |
|---|---|---|
| Throughput per megawatt | ↑ 50× | — |
| Cost per token | ↓ 35× (vs. Hopper) | — |
How NVIDIA Achieves These Gains
- Chip‑level innovations: Next‑generation Blackwell Ultra silicon.
- System architecture: Optimized GB300 NVL72 configurations.
- Software stack: Advanced drivers, libraries, and runtime optimizations.
Together, these codesign efforts accelerate AI workloads—from autonomous coding agents to interactive assistants—while dramatically reducing operational costs at scale.

GB300 NVL72 Delivers up to 50× Better Performance for Low‑Latency Workloads
Recent analysis from Signal65 shows that the NVIDIA GB200 NVL72—thanks to an extreme hardware‑software codesign—delivers >10× more tokens per watt, i.e., roughly one‑tenth the cost per token of the NVIDIA Hopper platform. These gains keep growing as the underlying stack matures.
Continuous optimizations from the TensorRT‑LLM, Dynamo, Mooncake, and SGLang teams further boost Blackwell NVL72 throughput for mixture‑of‑experts (MoE) inference across all latency targets. For example, recent TensorRT‑LLM improvements have yielded up to 5× better performance on GB200 for low‑latency workloads compared with just four months ago.
Key software advances
- Higher‑performance GPU kernels – tuned for efficiency and low latency, they extract the maximum from Blackwell’s massive compute power.
- NVIDIA NVLink Symmetric Memory – enables direct GPU‑to‑GPU memory access, reducing communication overhead.
- Programmatic dependent launch – starts the next kernel’s setup phase before the previous kernel finishes, minimizing idle time.
From software to hardware: GB300 NVL72
Building on these software improvements, the GB300 NVL72 (featuring the Blackwell Ultra GPU) pushes the throughput‑per‑megawatt frontier to ~50× that of the Hopper platform. This translates into dramatically better economics:
- Up to 35× lower cost per million tokens for low‑latency, agentic applications.
- Consistent cost reductions across the entire latency spectrum.
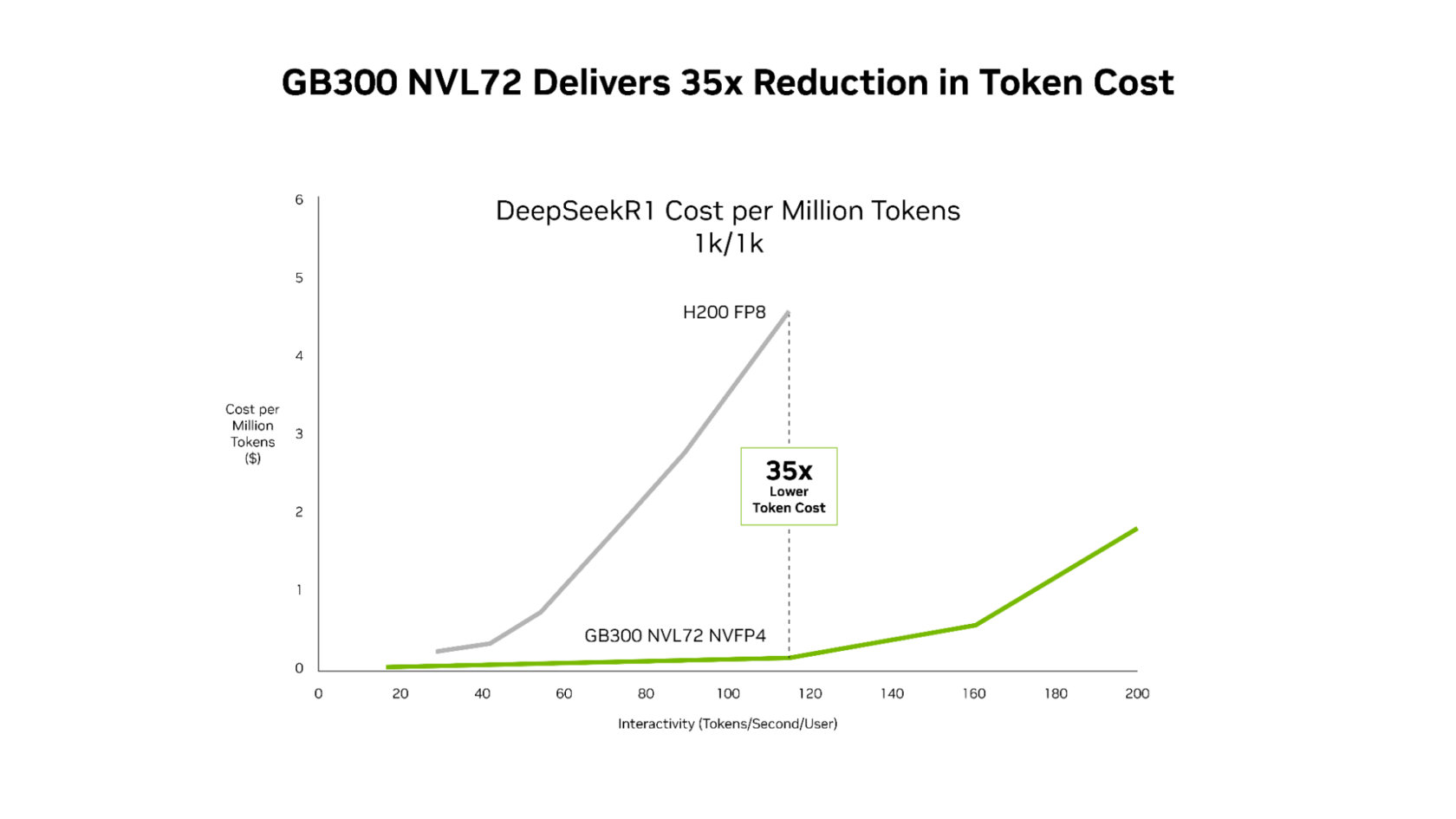
For agentic coding and interactive‑assistant workloads—where every millisecond compounds across multi‑step workflows—this combination of relentless software optimization and next‑generation hardware enables AI platforms to scale real‑time interactive experiences to significantly more users.
GB300 NVL72 Delivers Superior Economics for Long‑Context Workloads
Both the GB200 NVL72 and the GB300 NVL72 provide ultralow latency, but the advantages of the GB300 NVL72 become most evident in long‑context scenarios. For workloads with 128 k‑token inputs and 8 k‑token outputs—such as AI coding assistants that reason across entire codebases—the GB300 NVL72 achieves up to 1.5× lower cost per token compared with the GB200 NVL72.
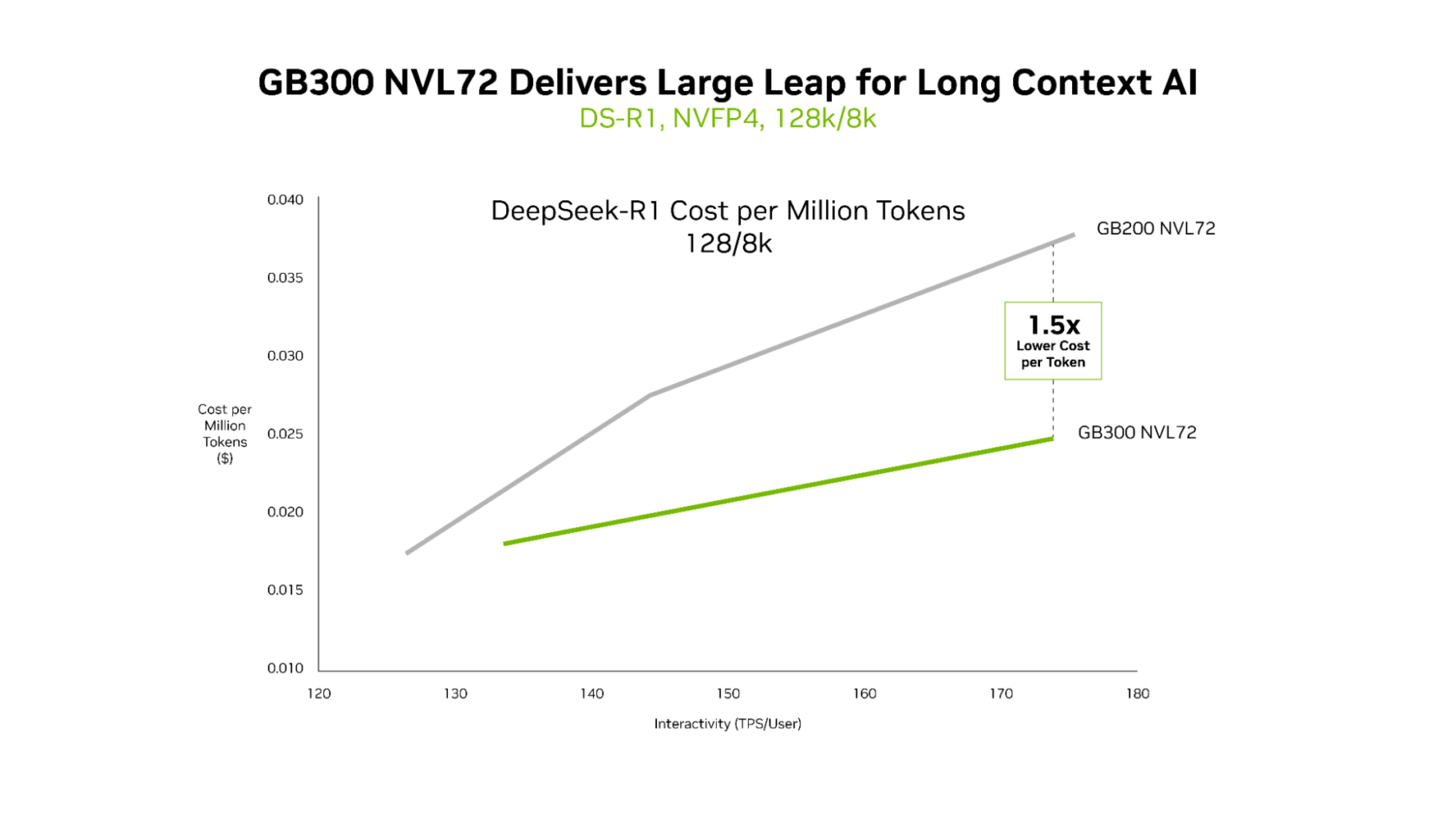
Why GB300 NVL72 Excels in Long‑Context Workloads
- Larger context window – As the agent reads more code, it gains a deeper understanding of the code base, but this also demands more compute.
- Higher compute performance – Blackwell Ultra delivers 1.5× greater NVFP4 compute than its predecessor.
- Faster attention processing – Attention operations are 2× faster, enabling efficient handling of entire codebases.
These improvements make the GB300 NVL72 the optimal choice for low‑latency, long‑context AI applications.
Infrastructure for Agentic AI
Leading cloud providers and AI innovators have already deployed NVIDIA GB200 NVL72 at scale and are now rolling out GB300 NVL72 in production.
- Microsoft – Azure delivers the first large‑scale cluster with NVIDIA GB300 NVL72 for OpenAI workloads
- CoreWeave – Production‑ready GB300 NVL72 instances for enterprise AI (6× performance gain on DeepSeek‑R1)
- Oracle Cloud Infrastructure (OCI) – Supercluster with NVIDIA Blackwell‑dedicated alloy
These providers are using GB300 NVL72 for low‑latency, long‑context workloads such as agentic coding and coding assistants. By reducing token costs, GB300 NVL72 enables a new class of applications that can reason across massive codebases in real time.
“As inference moves to the center of AI production, long‑context performance and token efficiency become critical,” said Chen Goldberg, Senior Vice President of Engineering at CoreWeave.
“Grace Blackwell NVL72 addresses that challenge directly, and CoreWeave’s AI cloud—including CKS and SUNK—is designed to translate GB300 systems’ gains, building on the success of GB200, into predictable performance and cost efficiency. The result is better token economics and more usable inference for customers running workloads at scale.”
NVIDIA Vera Rubin NVL72 to Bring Next‑Generation Performance
With NVIDIA Blackwell systems deployed at scale, continuous software optimizations will keep unlocking additional performance and cost improvements across the installed base.
Looking ahead, the NVIDIA Rubin platform—which combines six new chips to create one AI supercomputer—is set to deliver another round of massive performance leaps:
- MoE inference: up to 10× higher throughput per megawatt compared with Blackwell, translating to one‑tenth the cost per million tokens.
- Frontier‑AI training: large MoE models can be trained with only one‑fourth the number of GPUs required by Blackwell.
Learn more:
- Vera Rubin NVL72 system – the next‑generation AI supercomputer built on the Rubin platform.