Mixture of Experts Powers the Most Intelligent Frontier AI Models, Runs 10x Faster on NVIDIA Blackwell NVL72
Source: NVIDIA AI Blog
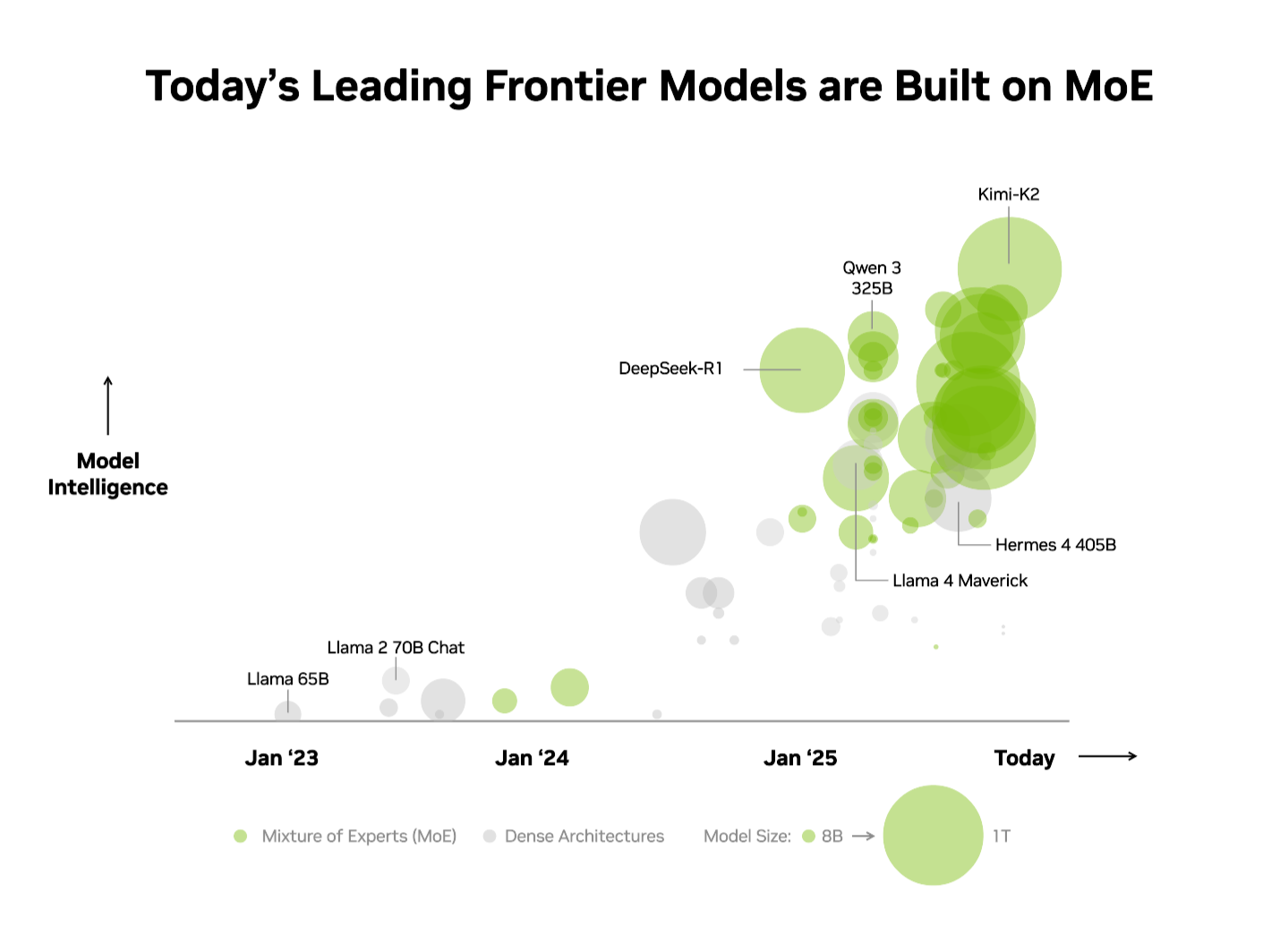
- The top 10 most intelligent open-source models all use a mixture-of-experts architecture.
- Kimi K2 Thinking, DeepSeek‑R1, Mistral Large 3 and others run 10× faster on NVIDIA GB200 NVL72.
A look under the hood of virtually any frontier model today will reveal a mixture‑of‑experts (MoE) architecture that mimics the efficiency of the human brain. Just as the brain activates specific regions based on the task, MoE models divide work among specialized “experts,” activating only the relevant ones for every AI token. This results in faster, more efficient token generation without a proportional increase in compute.
The industry has already recognized this advantage. On the independent Artificial Analysis (AA) leaderboard, the top 10 most intelligent open‑source models use an MoE architecture, including DeepSeek AI’s DeepSeek‑R1, Moonshot AI’s Kimi K2 Thinking, OpenAI’s gpt‑oss‑120B and Mistral AI’s Mistral Large 3.
Scaling MoE models in production while delivering high performance is notoriously difficult. The extreme codesign of NVIDIA GB200 NVL72 systems combines hardware and software optimizations for maximum performance and efficiency, making it practical and straightforward to scale MoE models.
The Kimi K2 Thinking MoE model — ranked as the most intelligent open‑source model on the AA leaderboard — sees a 10× performance leap on the NVIDIA GB200 NVL72 rack‑scale system compared with NVIDIA HGX H200. Building on the performance delivered for the DeepSeek‑R1 and Mistral Large 3 MoE models, this breakthrough underscores how MoE is becoming the architecture of choice for frontier models — and why NVIDIA’s full‑stack inference platform is the key to unlocking its full potential.
What Is MoE, and Why Has It Become the Standard for Frontier Models?
Until recently, the industry standard for building smarter AI was simply building bigger, dense models that use all of their parameters — often hundreds of billions for today’s most capable models — to generate every token. While powerful, this approach requires immense computing power and energy, making it challenging to scale.
Much like the human brain relies on specific regions to handle different cognitive tasks — whether processing language, recognizing objects or solving a math problem — MoE models comprise several specialized “experts.” For any given token, only the most relevant ones are activated by a router. This design means that even though the overall model may contain hundreds of billions of parameters, generating a token involves using only a small subset — often just tens of billions.
By selectively engaging only the experts that matter most, MoE models achieve higher intelligence and adaptability without a matching rise in computational cost. This makes them the foundation for efficient AI systems optimized for performance per dollar and per watt — generating significantly more intelligence for every unit of energy and capital invested.
Given these advantages, it is no surprise that MoE has rapidly become the architecture of choice for frontier models, adopted by over 60 % of open‑source AI model releases this year. Since early 2023, it’s enabled a nearly 70× increase in model intelligence — pushing the limits of AI capability.
“Our pioneering work with OSS mixture‑of‑experts architecture, starting with Mixtral 8x7B two years ago, ensures advanced intelligence is both accessible and sustainable for a broad range of applications,” said Guillaume Lample, co‑founder and chief scientist at Mistral AI. “Mistral Large 3’s MoE architecture enables us to scale AI systems to greater performance and efficiency while dramatically lowering energy and compute demands.”
Overcoming MoE Scaling Bottlenecks With Extreme Codesign
Frontier MoE models are simply too large and complex to be deployed on a single GPU. To run them, experts must be distributed across multiple GPUs, a technique called expert parallelism. Even on powerful platforms such as the NVIDIA H200, deploying MoE models involves bottlenecks such as:
- Memory limitations – For each token, GPUs must dynamically load the selected experts’ parameters from high‑bandwidth memory, creating heavy pressure on memory bandwidth.
- Latency – Experts must execute a near‑instantaneous all‑to‑all communication pattern to exchange information and form a final answer. On H200, spreading experts across more than eight GPUs forces communication over higher‑latency scale‑out networking, limiting the benefits of expert parallelism.
The solution: extreme codesign
NVIDIA GB200 NVL72 is a rack‑scale system with 72 NVIDIA Blackwell GPUs working together as if they were one, delivering 1.4 exaflops of AI performance and 30 TB of fast shared memory. The GPUs are connected via an NVLink Switch into a single massive NVLink fabric, providing 130 TB/s of NVLink connectivity.
MoE models can tap into this design to scale expert parallelism far beyond previous limits — distributing the experts across up to 72 GPUs.
This architectural approach directly resolves MoE scaling bottlenecks by:
- Reducing the number of experts per GPU – Distributing experts across up to 72 GPUs minimizes parameter‑loading pressure on each GPU’s high‑bandwidth memory and frees up memory for more concurrent users and longer input lengths.
- Accelerating expert communication – Experts spread across GPUs can communicate instantly using NVLink. The NVLink Switch also provides compute power to combine information from various experts, speeding up delivery of the final answer.
