LiteRT: The Universal Framework for On-Device AI
Source: Google Developers Blog
JAN. 28, 2026
Since we first introduced LiteRT in 2024, we have focused on evolving our ML tech stack from its TensorFlow Lite (TFLite) foundation into a modern on‑device AI framework. While TFLite set the standard for classical ML, our mission is to empower developers to deploy today’s cutting‑edge AI on‑device just as seamlessly as they integrated classical ML in the past.
At Google I/O ‘25, we shared a preview of this evolution: a high‑performance runtime designed specifically for advanced hardware acceleration. Today, we are excited to announce that these advanced acceleration capabilities have fully graduated into the LiteRT production stack, available now for all developers.
This milestone solidifies LiteRT as the universal on‑device inference framework for the AI era, representing a significant leap over TFLite for being:
- Faster – delivers 1.4× faster GPU performance than TFLite and introduces new, state‑of‑the‑art NPU acceleration.
- Simpler – provides a unified, streamlined workflow for GPU and NPU acceleration across edge platforms.
- Powerful – supports superior cross‑platform GenAI deployment for popular open models like Gemma.
- Flexible – offers first‑class PyTorch/JAX support via seamless model conversion.
All of this is delivered while maintaining the same reliable, cross‑platform deployment you trust since TFLite.
Here is how LiteRT empowers you in building the next generation of on‑device AI.
High‑performance cross‑platform GPU acceleration
Moving beyond the initial GPU acceleration on Android announced at I/O ‘25, we are excited to introduce full, comprehensive GPU support across Android, iOS, macOS, Windows, Linux, and Web. This expansion provides developers with a reliable, high‑performance acceleration option that scales significantly beyond classical CPU inference.
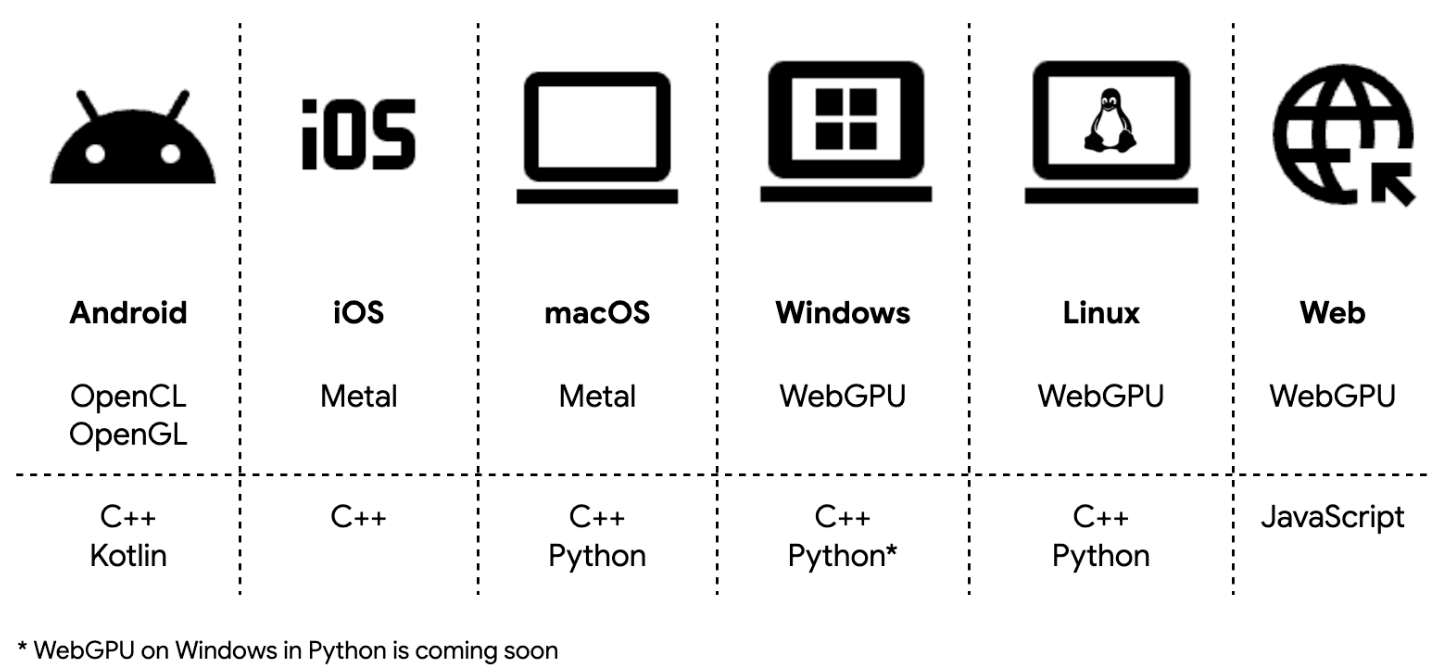
LiteRT maximizes reach by supporting OpenCL, OpenGL, Metal, and WebGPU via ML Drift, our next‑generation GPU engine, allowing efficient deployment across mobile, desktop, and web. On Android, LiteRT automatically prioritizes OpenCL when available for peak performance, falling back to OpenGL for broader device coverage.
Empowered by ML Drift, LiteRT GPU delivers average 1.4× faster performance over the legacy TFLite GPU delegate, significantly reducing latency across a broad range of models. See more benchmark results in our previous announcement.
To enable high‑performance AI applications, we introduced key technical advancements:
- Asynchronous execution
- Zero‑copy buffer interoperability
These features cut unnecessary CPU overhead and boost overall performance, meeting real‑time use cases like background segmentation and speech recognition (ASR). In practice, they can yield up to 2× faster performance, as demonstrated in our Segmentation sample app. For a deeper look, see our technical deep dive.
Example: GPU acceleration with the CompiledModel API (C++)
// 1. Create a compiled model targeting GPU.
auto compiled_model = CompiledModel::Create(env, "mymodel.tflite",
kLiteRtHwAcceleratorGpu);
// 2. Wrap an OpenGL buffer with zero‑copy.
auto input_buffer = TensorBuffer::CreateFromGlBuffer(env, tensor_type,
opengl_buffer);
std::vector<TensorBuffer*> input_buffers{input_buffer};
auto output_buffers = compiled_model.CreateOutputBuffers();
// 3. Execute the model.
compiled_model.Run(input_buffers, output_buffers);
// 4. Access model output (AHardwareBuffer).
auto ahwb = output_buffers[0]->GetAhwb();See more instructions on LiteRT cross‑platform development and GPU acceleration.
Streamlined NPU integration with peak performance
While CPU and GPU offer broad versatility, the NPU unlocks the smooth, responsive, high‑speed AI experience modern applications demand. Fragmentation across hundreds of NPU SoC variants has traditionally forced developers into complex, ad‑hoc deployment workflows.
LiteRT solves this with a unified, simplified NPU deployment workflow that abstracts low‑level, vendor‑specific SDKs. The process is a simple three‑step flow:
- AOT compilation (optional) – Use the LiteRT Python library to pre‑compile your
.tflitemodel for target SoCs. - Deploy with Google Play for On‑device AI (PODAI) on Android – PODAI automatically delivers the model and runtime to compatible devices.
- Inference using LiteRT Runtime – LiteRT handles NPU delegation and provides robust fallback to GPU or CPU if needed.
Full guide, including Colab notebooks and sample apps, is available in the LiteRT NPU documentation.
LiteRT supports both ahead‑of‑time (AOT) and on‑device (JIT) compilation:
- AOT – Ideal for complex models with known target SoCs; minimizes initialization time and memory footprint.
- JIT – Best for small models distributed across many platforms; requires no pre‑compilation but incurs higher first‑run cost.
Our first production‑ready integrations with MediaTek and Qualcomm are live. Technical deep‑dives show best‑in‑class NPU performance, reaching up to 100× faster than CPU and 10× faster than GPU:
- MediaTek NPU and LiteRT: Powering the next generation of on‑device AI
- Unlocking Peak Performance on Qualcomm NPU with LiteRT
Video demo placeholders omitted.
We continue expanding LiteRT’s NPU support to additional hardware—stay tuned for future announcements!
Superior cross‑platform GenAI support
Open models provide flexibility but deploying them can be high‑friction. LiteRT offers an integrated stack to simplify this workflow:
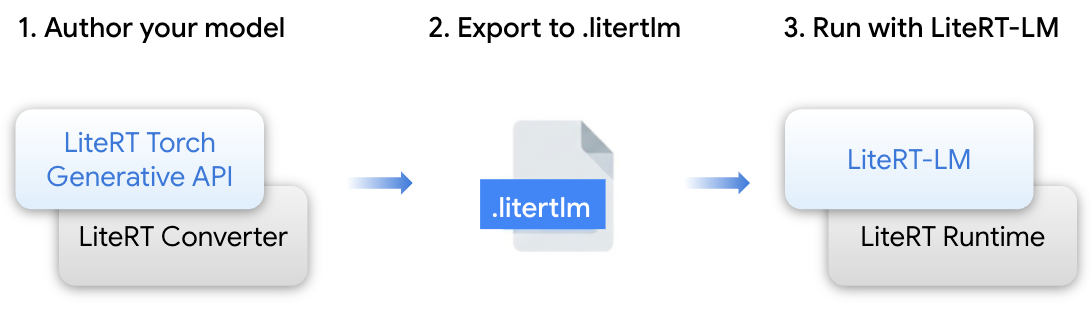
- LiteRT Torch Generative API – Python module for authoring and converting PyTorch transformer models into LiteRT‑LM/LiteRT formats.
- LiteRT‑LM – Orchestration layer built on LiteRT to manage LLM‑specific complexities; powers Gemini Nano deployment across Google products (Chrome, Pixel Watch).
- LiteRT Converter & Runtime – Core engine for efficient model conversion, runtime execution, and optimization across CPU, GPU, and NPU.
Benchmark example
We benchmarked Gemma 3 1B on a Samsung Galaxy S25 Ultra, comparing LiteRT with Llama.cpp. LiteRT outperformed Llama.cpp on both CPU and GPU for prefill and decode, and its NPU acceleration added an extra 3× gain over GPU for prefill.
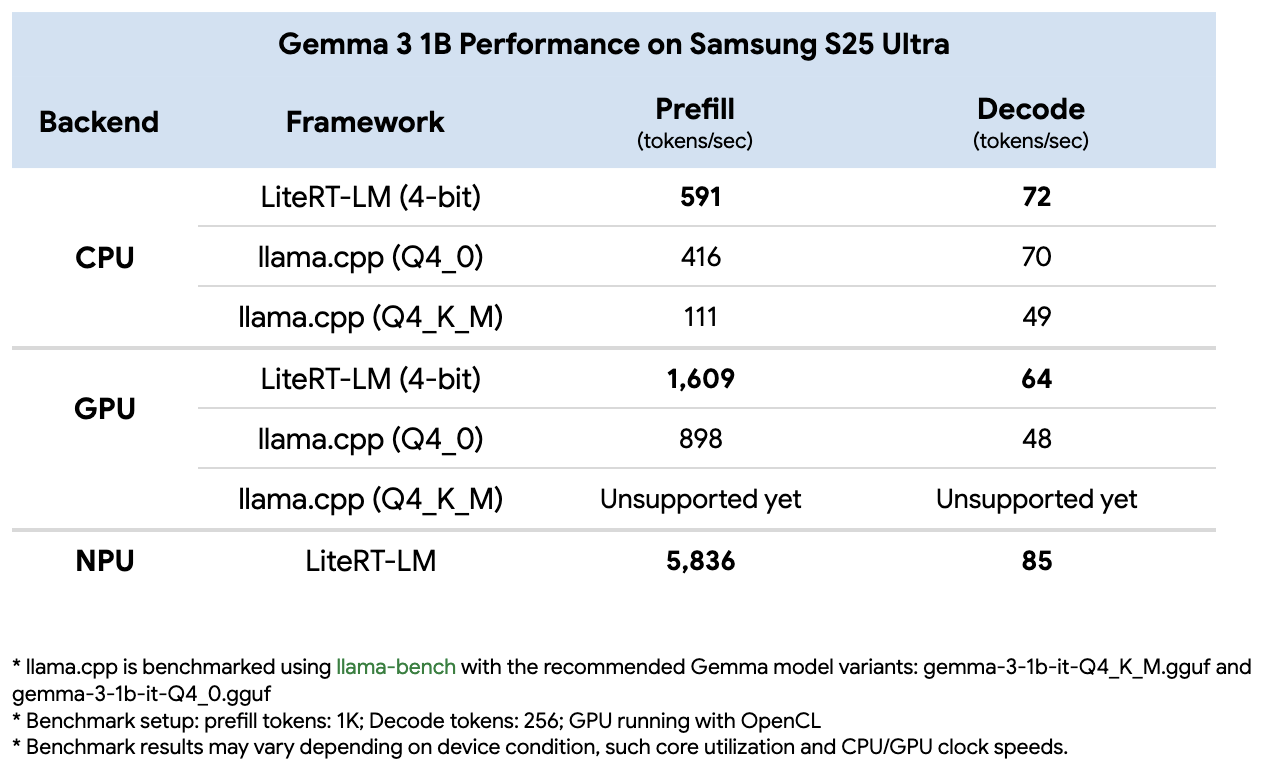
For a deep dive into the engineering behind these results, read the article on LiteRT’s optimizations under‑the‑hood.
LiteRT ships a growing collection of pre‑converted open‑weight models, including:
- Gemma family – Gemma 3 (270 M, 1 B), Gemma 3n, EmbeddingGemma, FunctionGemma
- Qwen, Phi, FastVLM, and more
These models are available on the LiteRT Hugging Face Community and can be explored via the Google AI Edge Gallery app on Android and iOS.
For more details, see the LiteRT GenAI documentation.
Broad ML framework support

LiteRT enables seamless model conversion from the industry’s most popular frameworks:
- PyTorch – Use the LiteRT Torch library to convert PyTorch models directly to
.tflite. - TensorFlow & JAX – Continue to enjoy best‑in‑class support for TensorFlow and conversion of JAX models via the
jax2tfbridge.
By consolidating these paths, LiteRT accelerates research‑to‑production regardless of your preferred development environment. Get started with the LiteRT Torch Colab or explore the technical details in this deep dive.
Reliability and compatibility you can trust
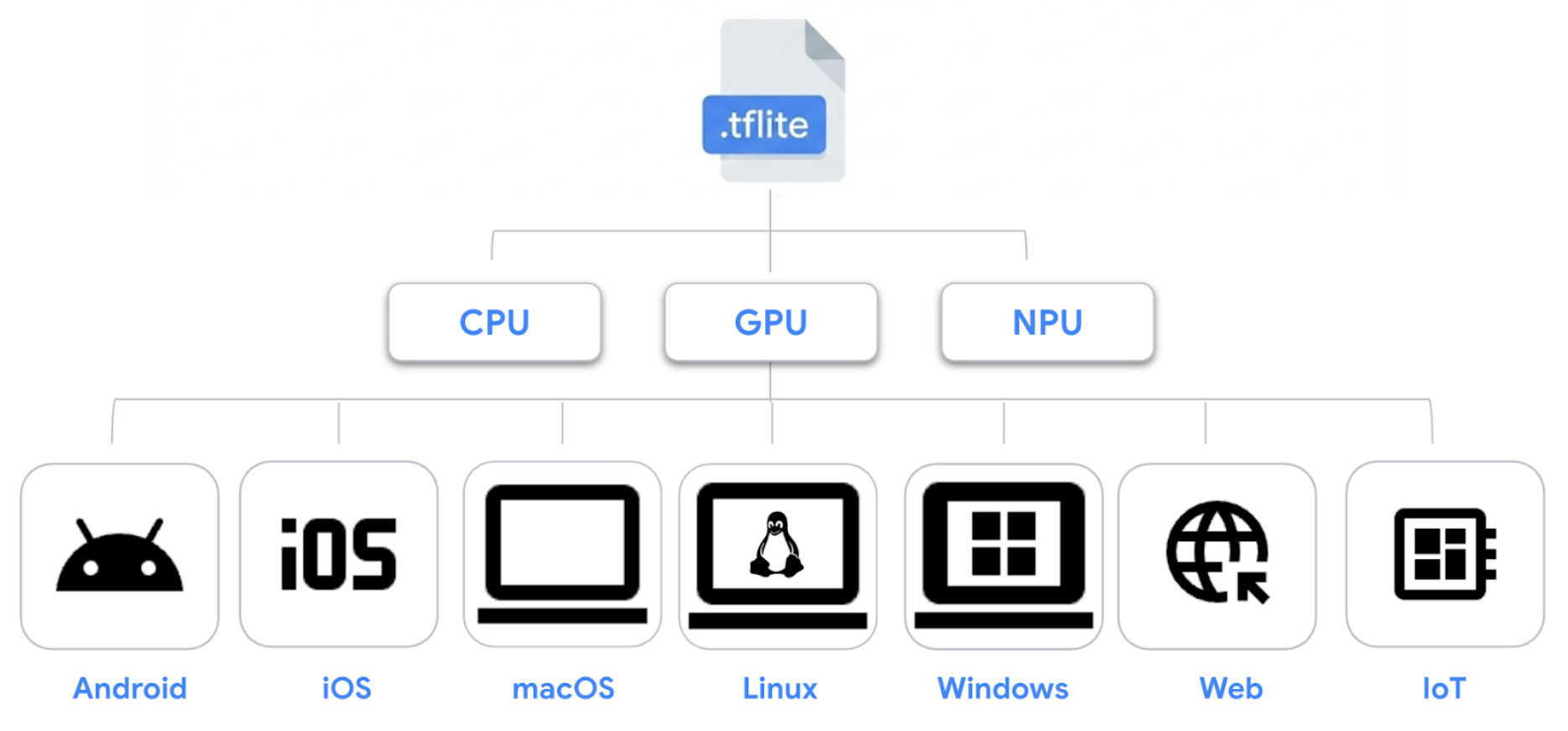
LiteRT builds on the proven .tflite model format, ensuring existing models remain portable and compatible across Android, iOS, macOS, Linux, Windows, Web, and IoT.
Two execution paths are supported:
- Interpreter API – Guarantees rock‑solid stability for existing production models.
- CompiledModel API – Modern interface that unlocks full GPU and NPU acceleration for next‑generation AI workloads. See why to choose the CompiledModel API in the documentation.
What’s next
Ready to build the future of on‑device AI? Get started with these resources:
- Explore the LiteRT Documentation for comprehensive guides.
- Visit the LiteRT GitHub and the LiteRT Samples repo for code examples.
- Browse the LiteRT Hugging Face Community for ready‑to‑use open models, and try the Google AI Edge Gallery app on Android or iOS.
Provide feedback or request features by opening an issue on our GitHub channel. We can’t wait to see what you build with LiteRT!
Acknowledgements
Thank you to the team members and collaborators whose contributions made this release possible: Advait Jain, Andrew Zhang, Andrei Kulik, Akshat Sharma, Arian Arfaian, Byungchul Kim, Changming Sun, Chunlei Niu, Chun‑nien Chan, Cormac Brick, David Massoud, Dillon Sharlet, Fengwu Yao, Gerardo Carranza, Jingjiang Li, Jing Jin, Grant Jensen, Jae Yoo, Juhyun Lee, Jun Jiang, Kris Tonthat, Lin Chen, Lu Wang, Luke Boyer, Marissa Ikonomidis, Matt Kreileder, Matthias Grundmann, Majid Dadashi, Marko Ristić, Matthew Soulanille, Na Li, Ping Yu, Quentin Khan, Raman Sarokin, Ram Iyengar, Rishika Sinha, Sachin Kotwani, Shuangfeng Li, Steven Toribio, Suleman Shahid, Teng‑Hui Zhu, Terry (Woncheol) Heo, Vitalii Dziuba, Volodymyr Kysenko, Weiyi Wang, Yu‑Hui Chen, Pradeep Kuppala, and the gTech team.