운영하지 않는 Kafka, EasyQueue를 소개합니다
Source: NHN Cloud Tech Blog

운영하지 않는 Kafka, EasyQueue를 소개합니다
Kafka를 직접 띄워보신 적 있으신가요. 처음에는 “이거 그냥 docker compose up 하면 되는 거 아냐?”로 가볍게 시작합니다. 그러다 운영 환경으로 옮기는 순간 일이 달라지죠. 브로커는 몇 대로 띄울지, 디스크는 어떻게 잡을지, 복제본 수와 리텐션은 얼마로 잡을지, 백업·모니터링·알람은 또 어떻게 붙일지로 일주일이 사라집니다. 어느새 본업은 Kafka 운영이 되어 있습니다.
그렇다고 클라우드의 관리형 서비스로 도망치자니, 이번엔 다른 고민이 시작됩니다. 기존 Kafka 클라이언트 코드는 그대로 쓸 수 있는지, 토픽 설정은 직접 손댈 수 있는지, 컨슈머 Lag 같은 운영 지표는 어떻게 볼 것인지. “관리형”이라는 단어가 어디까지를 관리해 주는지가 늘 애매했습니다.
NHN Cloud의 EasyQueue는 이 두 고민의 가운데에서 출발했습니다. 클러스터 운영은 우리에게 맡기되, Kafka 본연의 유연함은 그대로 사용자에게 돌려주자는 것. 이번 글에서는 그 사이의 균형을 어떻게 잡았는지, 그리고 EasyQueue가 어떤 분들께 잘 맞는 서비스인지를 풀어보려고 합니다.
EasyQueue가 차지하는 자리
EasyQueue는 NHN Cloud가 운영하는 Apache Kafka 클러스터 위에 토픽을 만들어 바로 메시지를 주고받을 수 있게 해 주는 완전관리형 Apache Kafka 서비스입니다. 클러스터 설치·노드 추가·보안 패치·모니터링은 NHN Cloud가 맡고, 토픽 설계와 파티션 수, 컨슈머 그룹처럼 Kafka 본연의 유연함은 그대로 사용자가 제어할 수 있도록 설계되어 있어요. 현재 베타 단계로, 한국 판교·평촌 두 리전에서 사용할 수 있습니다. 한 줄로 줄이면 “Kafka는 그대로 쓰되, 운영은 하지 않는 Kafka” — 그게 EasyQueue의 자리입니다.
관리형과 Kafka 사이, 어디에 선을 그었나
EasyQueue를 만들면서 가장 먼저 정한 건 사용자가 직접 다룰 영역과, 저희가 떠맡을 영역 사이의 선이었습니다. 클러스터 띄우기, 노드 추가, 보안 패치, 메트릭 수집 — 이건 누가 봐도 “운영”의 영역이고, 사용자가 매번 신경 쓸 일이 아닙니다. 반면 토픽을 어떻게 설계할지, 파티션을 몇 개로 나눌지, 프로듀서와 컨슈머를 어떻게 구성할지는 서비스 로직에 직접 연결되는 부분이에요. 그래서 선을 분명하게 그었습니다. 클러스터 운영은 NHN Cloud가, 토픽 안쪽은 사용자가.
이 선을 정하고 나니 다음 결정이 자연스럽게 따라왔습니다. “그럼 클러스터는 어떻게 구성할 것인가?” 후보는 두 가지였어요. 사용자마다 전용 클러스터를 띄워 주는 방식과, 여러 사용자가 한 클러스터를 함께 쓰는 공용 클러스터 방식. EasyQueue는 후자를 골랐습니다. “쓰고 싶을 때 즉시 토픽을 만들고, 안 쓰면 비용도 거의 들지 않는” 경험을 가장 가깝게 만드는 길이었기 때문입니다. 물론 트레이드오프는 분명히 있어요. 공용 클러스터 모델은 한 토픽에 매우 큰 부하가 몰리는 대용량 워크로드에는 한계가 있을 수 있습니다.
같은 맥락에서 EasyQueue는 의식적으로 사용 제한을 두고 있습니다. 토픽과 파티션의 사용 가능한 수는 프로젝트마다 일정 범위로 제한되어 있습니다. 처음 들으면 아쉽게 느껴질 수 있는데, 공용 클러스터 모델에서는 가장 합리적인 선택이에요. 한 사용자가 토픽 수백 개를 한꺼번에 만들면 같은 클러스터를 쓰는 다른 사용자의 성능에 영향이 갑니다. 토픽 수 제한은 이걸 사전에 막는 가드레일인 셈입니다. 더 많은 토픽이 필요하다면 고객지원으로 문의 주시면 늘려드리고, 토픽당 파티션 수도 필요에 따라 확장할 수 있어요.
매일의 운영을 가볍게 만드는 것들
콘솔에서 클릭 몇 번, 토픽이 뜹니다
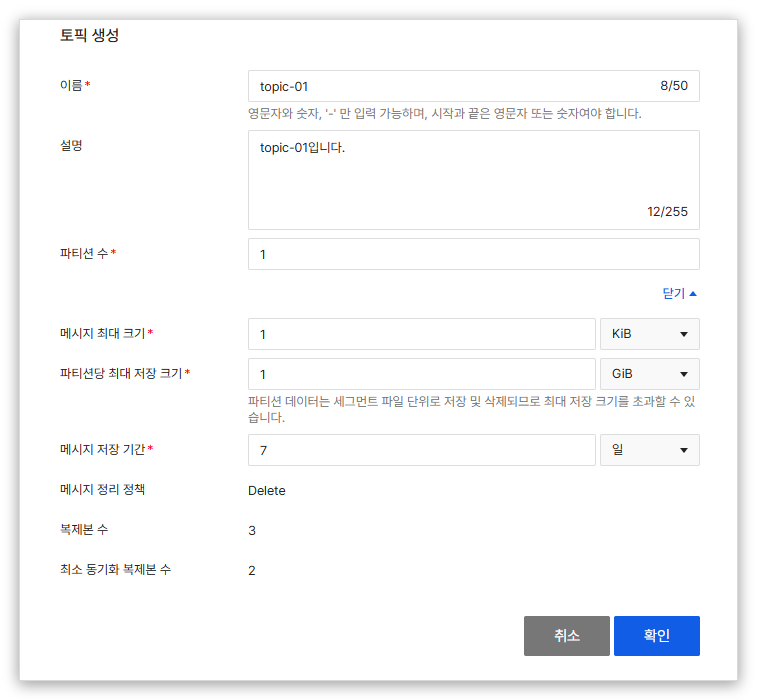
새 토픽을 만든다는 건 Kafka를 처음 다룰 때 가장 막막한 순간 중 하나입니다. CLI로 만들려면 어떤 명령을 호출해야 하는지, 클러스터 주소는 어디에 써야 하는지, 권한과 인증은 어디까지 풀어야 하는지를 거쳐야 비로소 토픽이 생기죠. EasyQueue는 이 과정을 콘솔의 화면 하나로 줄였어요. 이름, 파티션 수, 메시지 저장 기간(리텐션) 같은 항목만 정하면 사용할 수 있는 토픽이 만들어집니다. 운영 안정성에 직결되는 복제본 수(3)와 최소 동기화 복제본 수(2)는 기본값으로 미리 설정되어 있어, 토픽을 어떻게 안전하게 구성해야 할지 따로 고민하지 않아도 됩니다. 수정과 삭제도 같은 흐름이라, 토픽의 수명주기 전체가 콘솔 안에서 정리됩니다.
kafka-console-producer 없이도 테스트가 됩니다
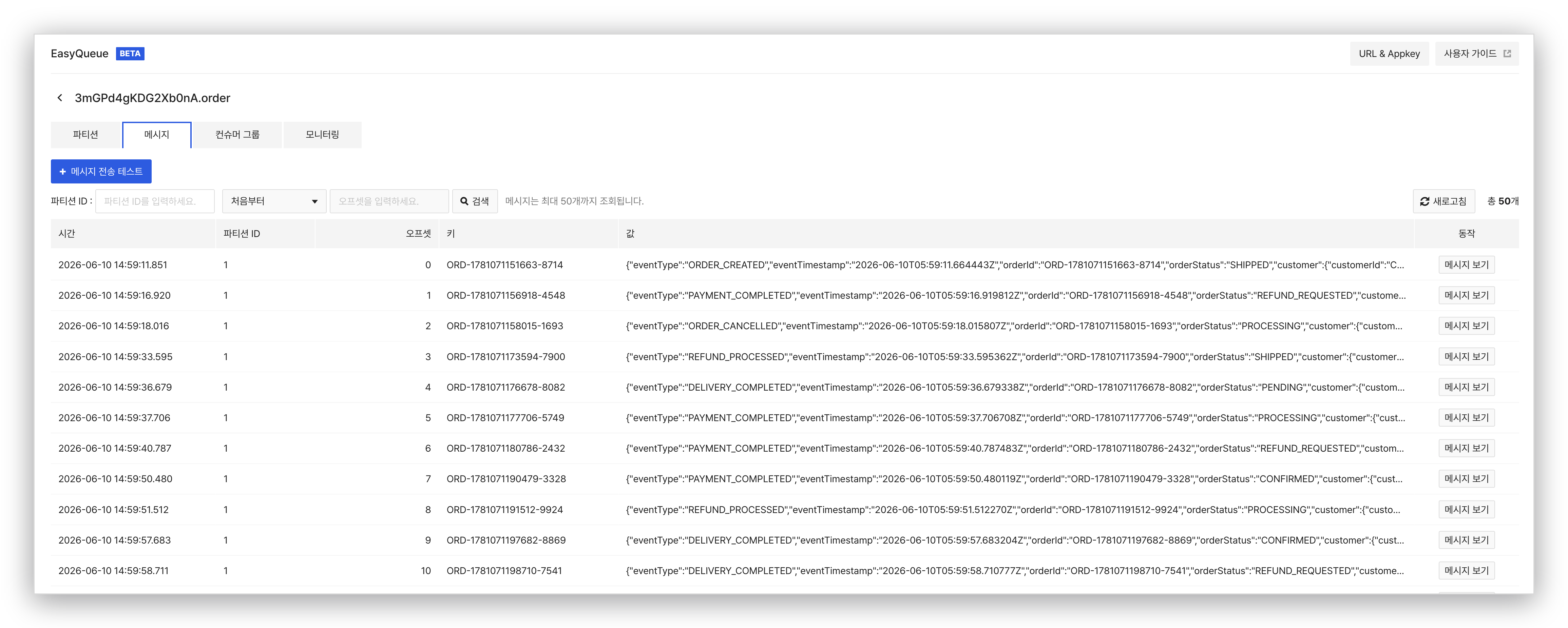
토픽을 만들고 나면 다들 비슷한 동작을 합니다. 메시지가 잘 들어가는지, 잘 빠지는지를 일단 한 번 찔러보고 싶죠. 보통은 kafka-console-producer로 한 줄 보내고, kafka-console-consumer로 받아 보는 흐름입니다. EasyQueue는 이 작업을 콘솔에서 바로 할 수 있게 해 두었습니다. 토픽 상세 화면의 메시지 전송 테스트 버튼으로 토픽에 임의의 메시지를 흘려보내고, 같은 화면의 메시지 조회에서 파티션과 오프셋 조건으로 쌓인 메시지를 들춰볼 수 있어요. 토픽이 정상적으로 동작하는지 확인하려고 따로 클라이언트 코드를 짤 필요가 없습니다. 실제 운영에서는 애플리케이션이 Kafka 클라이언트로 메시지를 발행하지만, 개발 초기의 통신 점검이나 장애 조사 시점에 콘솔에서 바로 확인할 수 있다는 점이 운영 부담을 줄여줍니다.
Lag을 별도 도구 없이 본다는 것
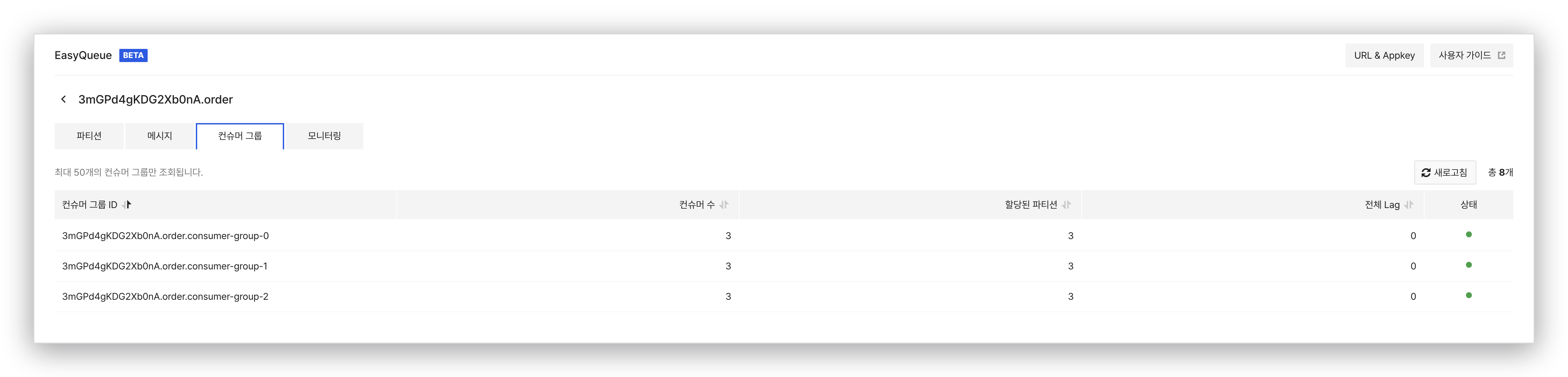
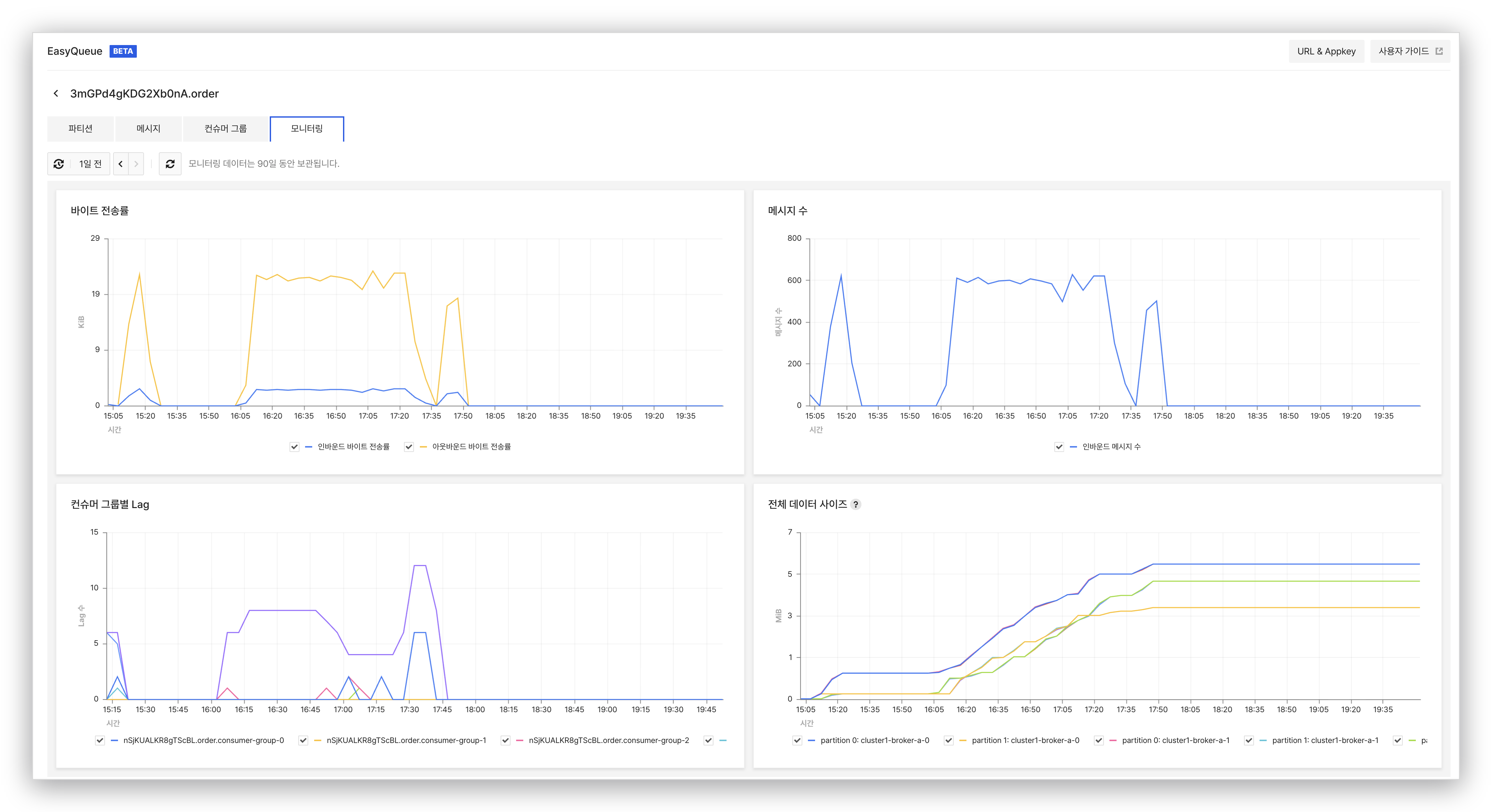
Kafka를 운영해 본 사람이라면 컨슈머 Lag이 얼마나 중요한 지표인지 잘 아실 거예요. 컨슈머가 처리 속도를 따라가지 못하면 Lag이 쌓이고, 임계치를 넘으면 알람이 울리고, 그제서야 문제가 잡힙니다. 보통은 Burrow나 Kafka Exporter 같은 도구를 별도로 띄워서 봐야 하는데, EasyQueue는 콘솔 안에서 Lag을 두 가지 시점으로 보여줍니다. 토픽 상세의 컨슈머 그룹 탭에서는 그룹별로 지금 Lag이 얼마나 쌓여 있는지를 한 줄로 확인할 수 있고, 모니터링 탭의 컨슈머 그룹별 Lag 차트에서는 시간에 따른 Lag 추이를 시계열로 볼 수 있어요. 어느 컨슈머 그룹이 지연되고 있는지, 그게 일시적인 스파이크인지 누적되는 추세인지를 별도의 사이드카나 대시보드 없이 판단할 수 있습니다.
모니터링 데이터는 90일 동안 보관되기 때문에, 사후 분석도 콘솔 안에서 가능합니다. “지난주 새벽에 Lag이 튀었던 그게 뭐였지?” 같은 질문에 별도 메트릭 저장소를 뒤지지 않고 답할 수 있어요.
기존 Kafka 코드, 표준 그대로 붙습니다
관리형 서비스를 도입할 때 가장 큰 걱정은 락인(lock-in)입니다. “지금은 편하지만, 나중에 다른 곳으로 옮기려면 코드를 다시 짜야 하는 거 아닌가?” 하는 걱정이죠. EasyQueue는 이 부분을 표준 Apache Kafka 프로토콜 호환으로 풀었습니다. 사용하시던 Java, Python, Go의 Kafka 클라이언트 라이브러리를 그대로 쓰고, 접속 정보와 표준 OAuth 인증 설정(SASL/OAUTHBEARER)만 추가하면 됩니다. Kafka 자체의 사용법 — 토픽, 파티션, 컨슈머 그룹, 트랜잭션 — 은 어디서나 동일하기 때문에, 기존 컨슈머·프로듀서 코드, 모니터링 설정, 운영 노하우가 그대로 자산이 됩니다. 구체적인 코드 예제는 뒤의 시작하기 단계에서 다뤄볼께요.
안에서는 이렇게 돌아갑니다
EasyQueue에서 메시지는 컨슈머가 읽어 가도 삭제되지 않습니다. 설정한 보관 기간 또는 용량 한도에 도달할 때까지 토픽에 그대로 유지되기 때문에 여러 컨슈머가 각자의 진행 상황(오프셋)을 기억하면서 같은 메시지를 독립적으로 가져갈 수 있고, 컨슈머를 재시작하거나 새로 추가해 처음부터 다시 읽는 것도 가능합니다.
전체 흐름은 세 단계로 정리됩니다.
[Producer A] [Producer B] [Producer C]
│ │ │
└────────────┼────────────┘ ① 발행 (publish)
▼
┌────────────── EasyQueue ──────────────┐
│ │
│ ┌─Topic ─┐ ┌─Topic ─┐ ┌─Topic ─┐ │
│ │ part 0 │ │ part 0 │ │ part 0 │ │
│ │ part 1 │ │ part 1 │ │ part 1 │ │
│ │ part 2 │ │ part 2 │ │ part 2 │ │ ② 저장 (store)
│ │ part 3 │ │ part 3 │ │ part 3 │ │ · 3중 복제
│ └────────┘ └────────┘ └────────┘ │
│ │
└───────────────────┬───────────────────┘
│
┌──────────────┼──────────────┐ ③ 구독 (subscribe)
▼ ▼ ▼
[Consumer A] [Consumer B] [Consumer C]① 프로듀서가 토픽으로 메시지를 보내고, ② EasyQueue 클러스터가 그 메시지를 토픽 내부의 파티션에 나눠 저장하고, ③ 컨슈머가 필요한 시점에 토픽에서 메시지를 읽어 갑니다. 발행·저장·구독으로 이어지는 흐름은 직접 운영하는 Kafka와 동일합니다.
운영 측면에서 짚어둘 부분이 두 가지 있어요. 첫 번째는 메시지 3중 복제입니다. Kafka를 직접 운영하면 복제본 수와 최소 동기화 복제본 수를 토픽마다 자유롭게 정할 수 있고, 메시지 유실보다 처리 성능이 중요할 때는 이 값을 낮춰 쓰기도 합니다. EasyQueue는 이 값을 복제본 수 3, 최소 동기화 복제본 수 2로 고정했어요. 자유도는 조금 줄지만 메시지가 유실되지 않는 쪽을 기본으로 보장하기 위해서입니다. 그래서 한 메시지는 항상 서로 다른 브로커 3대에 나뉘어 저장되고, 세 복제본 중 하나가 리더를 맡아 읽기·쓰기를 처리하다가 리더가 있는 브로커에 장애가 나면 남은 복제본 중 하나가 곧바로 리더 역할을 이어받아요. 덕분에 브로커 한 대가 멈춰도 메시지 손실 없이 정상 동작이 이어집니다.
두 번째는 리전 단위로 분리된 클러스터입니다. EasyQueue는 현재 판교와 평촌, 두 리전에 각각 독립된 클러스터를 운영합니다. 한 리전의 장애가 다른 리전으로 번지지 않도록 격리되어 있어, 운영 차원의 안정성은 인프라 레벨에서 이미 확보된 상태로 시작합니다.
그래서, 어떻게 시작하나
EasyQueue를 클라이언트로 연결하려면 세 가지 정보가 필요합니다. 인증 키 한 쌍, Appkey, 그리고 토픽이 살고 있는 Bootstrap Servers 주소. 콘솔에서 메뉴를 세 번 들렀다 오면 끝나는 일이에요.
1단계. User Access Key 발급하기
EasyQueue는 SASL/OAUTHBEARER, 즉 OAuth 2.0 Bearer 토큰을 인증에 씁니다. 토큰 발급에 쓸 인증 키를 먼저 만들어야 해요. NHN Cloud 콘솔의 마이 페이지 > API 보안 설정에서 토큰 타입이 JWT인 User Access Key를 생성하면, User Access Key 와 Secret Access Key 한 쌍을 받게 됩니다. 이 두 값이 Kafka 클라이언트의 인증 자격증명으로 들어가요.
2단계. Appkey와 Bootstrap Servers 확인하기
인증 키를 받았으면, 이번엔 EasyQueue 콘솔로 돌아옵니다. 우측 상단의 URL & Appkey 메뉴에서 Appkey를 확인하세요. Appkey는 아래 Kafka 클라이언트로 연결하기 단계에서 토픽·컨슈머 그룹 이름의 접두어로 쓰입니다. 그다음 메시지를 주고받을 토픽을 만든 뒤 토픽 상세의 클라이언트 접속 정보에서 Bootstrap Servers 주소를 확인합니다. Bootstrap Servers는 {region}-{cluster}-bootstrap-easyqueue.nhncloudservice.com:30000 형태로 보입니다. 포트는 일반 Kafka 기본 포트(9092)가 아니라 30000번대라는 점만 짚어두세요.
3단계. Kafka 클라이언트로 연결하기
여기서부터는 평소 쓰시던 Kafka 클라이언트 라이브러리를 그대로 쓰면 됩니다. 인증 방식이 PLAIN이나 SCRAM이 아니라 OAUTHBEARER라는 차이는 있지만, 이것도 표준 Apache Kafka 메커니즘이에요. 한 가지 명명 규칙만 기억하면 됩니다. 토픽 이름과 컨슈머 그룹 ID는 모두 {APP_KEY}. 접두어로 시작합니다. 권한 분리를 위한 규칙이라 어기면 권한 오류가 납니다. 아래 설정값은 EasyQueue의 SASL/OAUTHBEARER 방식을 기준으로 작성했습니다. 코드의 “에는 OAuth 토큰을 발급하는 NHN Cloud 인증 서버 주소인 https://oauth.api.nhncloudservice.com/oauth2/token/create를 넣습니다.
Java로 메시지를 보내는 가장 단순한 예제는 다음과 같습니다.
Properties props = new Properties();
props.put("bootstrap.servers", "");
props.put("key.serializer", StringSerializer.class.getName());
props.put("value.serializer", StringSerializer.class.getName());
// SASL/OAUTHBEARER 인증 설정
props.put("security.protocol", "SASL_SSL");
props.put("sasl.mechanism", "OAUTHBEARER");
props.put("sasl.login.callback.handler.class",
"org.apache.kafka.common.security.oauthbearer.OAuthBearerLoginCallbackHandler");
props.put("sasl.oauthbearer.token.endpoint.url", "");
props.put("sasl.jaas.config",
"org.apache.kafka.common.security.oauthbearer.OAuthBearerLoginModule required " +
"clientId=\"\" " +
"clientSecret=\"\" " +
"scope=\"appKey:\";");
String topic = ".my-topic";
try (KafkaProducer producer = new KafkaProducer(props)) {
producer.send(new ProducerRecord(topic, "hello"));
}Python(confluent-kafka 기준)이라면 비슷한 구조로 다음처럼 짧아집니다.
from confluent_kafka import Producer
config = {
"bootstrap.servers": "",
"security.protocol": "SASL_SSL",
"sasl.mechanisms": "OAUTHBEARER",
"sasl.oauthbearer.method": "oidc",
"sasl.oauthbearer.token.endpoint.url": "",
"sasl.oauthbearer.client.id": "",
"sasl.oauthbearer.client.secret": "",
"sasl.oauthbearer.scope": "appKey:",
}
producer = Producer(config)
producer.produce(".my-topic", value=b"hello")
producer.flush()컨슈머도 같은 인증 설정에 group.id만 .my-group 형태로 추가하면 끝입니다. OAuth 토큰은 클라이언트 라이브러리가 알아서 발급·갱신하기 때문에, 한 번 설정해 두면 평소처럼 메시지를 주고받게 됩니다. 다만 토큰 유효 시간이 지나면 만료되니, 장시간 실행되는 프로듀서/컨슈머라면 토큰 자동 갱신이 동작하도록 설정해 두는 것이 안전합니다. 자세한 언어별 예제와 트랜잭션 사용법은 Kafka 클라이언트 가이드를 참고해 주세요.
토픽이 정상적으로 동작하는지는 앞서 소개한 콘솔의 메시지 전송 테스트 로 한 번 더 확인해 볼 수 있어요. 개발 환경 통합부터 운영 도입까지의 거리가 짧다는 점이 EasyQueue를 도입할 때 가장 빨리 체감할 수 있는 차이입니다.
요금과 마무리
쓴 만큼만 내는 종량제
EasyQueue는 쓴 만큼만 비용이 나가는 종량제로 운영됩니다. 별도의 인스턴스 비용 없이, 사용한 자원에 따라 네 가지 항목이 시간 단위로 누적됩니다.
| 과금 구분 | 과금 기준 | 요금 |
|---|---|---|
| 파티션 수 | 1개당 사용 시간 누적 | 30원/시간 |
| 저장 데이터 용량 | 1GB당 사용 시간 누적 | 1.93원/시간 |
| 메시지 쓰기량 | 1GB당 | 140원 |
| 메시지 읽기량 | 1GB당 | 70원 |
(2026년 6월 기준, VAT 별도. 한국(판교)·한국(평촌) 동일)
두 가지만 짚어둘게요. 저장 데이터 용량은 복제본 수가 3이라 사용자가 저장한 실제 크기보다 최대 3배로 측정됩니다. EasyQueue가 운영 안정성을 위해 한 메시지를 브로커 3대에 동시 저장하기 때문이에요. 앞서 살펴본 3중 복제의 비용 측 영향이 이 부분입니다. 두 번째는 토픽별로 메시지 보존 기간, 파티션 최대 크기, 파티션 개수를 직접 조정할 수 있다는 점입니다. 저장 비용은 결국 토픽 설정에 따라 결정되기 때문에, 트래픽 패턴이 잡히면 보존 기간을 줄이거나 파티션 크기를 조정해서 비용을 통제할 수 있어요. 가장 최신 요금은 공식 요금 안내 페이지에서 확인하실 수 있습니다.
지금의 EasyQueue, 그리고 지금 시작하기
EasyQueue는 2026년 6월 기준 베타 단계입니다. 한국 두 리전에서 운영 중이고, 토픽·파티션 수를 일정 범위로 제한하는 것처럼 공용 클러스터 모델 위에서 의식적으로 두고 있는 가드레일도 있습니다. 사용 규모가 커지거나 더 큰 한도가 필요해 도입을 검토하는 단계라면, 고객지원으로 문의해 주시는 것이 가장 빠른 길입니다.
EasyQueue가 만들고 싶었던 건 거창한 것이 아닙니다. Kafka의 유연함은 그대로 두되, Kafka 운영의 무게는 덜어내는 것. 그래서 Kafka가 필요할 때, 인프라 구축이 아니라 비즈니스 로직으로 바로 시간을 쓸 수 있게 하는 것. 그게 우리가 잡고 싶었던 자리입니다.
콘솔에서 토픽 하나 만들어 보시는 데는 1분도 걸리지 않습니다. 한 번 띄워 보시고, 사용하시던 Kafka 코드를 그대로 붙여 보세요.
