How I Designed a Zero-Waste, Event-Driven Analytics Pipeline Using DynamoDB TTL and AWS Lambda
Source: Dev.to
Problem Statement
It is time to get the data Barx is generating and bring it to the barbers. My first option was to create a cron job that runs every Monday at 3 am UTC. When my Lambda triggers, I search for all barbershops in DynamoDB and start the analytics calculation for each one.
Issues with the cron‑based approach
- Scanning the entire DynamoDB table is resource‑intensive and can be costly.
- A single Lambda function handles a heavy workload, which may impact performance and scalability.
- Every Monday, the process attempts to retrieve all barbershops, regardless of their activity status.
- Analytics calculations are performed for all barbershops, including those without any activity in the previous week, leading to unnecessary resource consumption.
The goal is to spend resources only on barbershops that had activity in the last week and recalculate their analysis for the last 7, 30, 60, and 90 days.
Architecture Proposal
Thinking on that, I built this architecture:
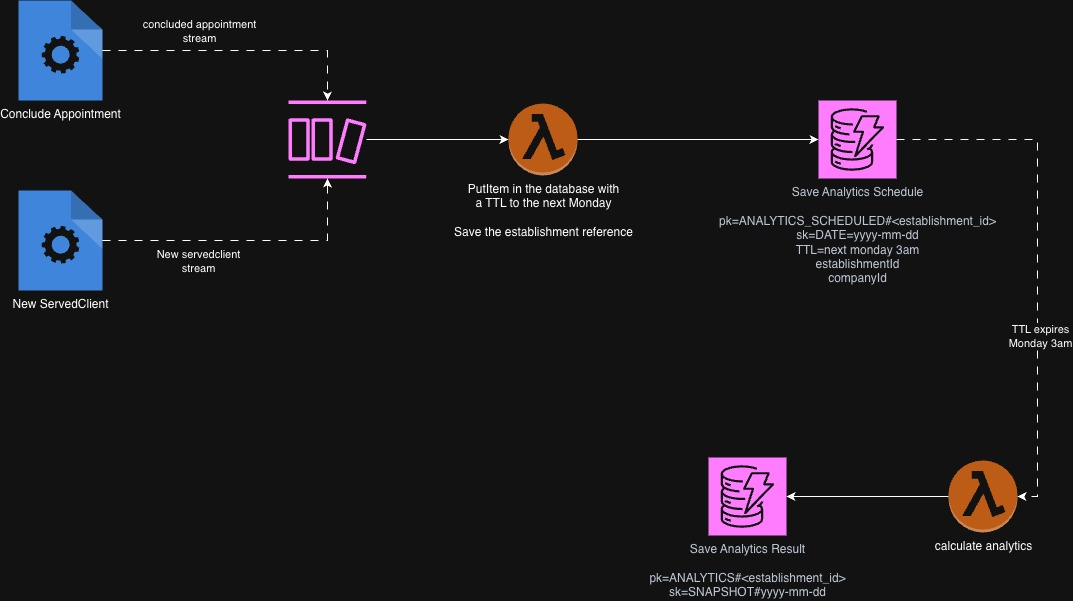
It looks simple, but it lets me schedule a job only for those barbershops that had some activity. I create a record in DynamoDB that expires next Monday at 3 am UTC. When the record is deleted by the TTL rule, it triggers another Lambda that passes the data of that barbershop to a dedicated Lambda for its analytic calculation.
This approach ensures resources are spent only on users who are producing data, not on idle users.
Benefits
- Analytics calculations are performed only for barbershops with recent activity, optimizing resource usage.
- Scheduled records in DynamoDB are automatically cleaned up via TTL, reducing manual maintenance.
- The architecture scales efficiently, supporting any number of users without additional complexity.
Concerns
- If many records expire at the same time, a large number of Lambdas may be triggered simultaneously, leading to a spike in concurrent executions. (This can be mitigated by configuring DynamoDB Stream batch size and parallelization factor.)
- There may be a delay between the scheduled expiration time and the actual triggering of the Lambda, depending on the load on the DynamoDB Streams service. (This is acceptable for my use case since analytics don’t need to be real‑time.)
I’m sharing this idea to get feedback from the community. If you have suggestions for improvement or alternative approaches, please let me know in the comments!