From ChatGPT to Gemini: How We Built a GDPR-Compliant CV Parser for Odoo
Source: Dev.to


Background
A few years ago, a business owner in France contacted us to help digitalise their workflow. The company specialises in recruiting people for Work‑Study Programs (known in France as Alternance).
Alternance is a system where a student splits time between school and a job. It’s attractive because the student:
- Receives a degree for free
- Gains real work experience
- Earns a salary based on the French minimum wage (SMIC)
The agency acts as an expert middle‑man, handling a process that can be overwhelming for a single party. Their workflow looks like this:
- Finding Candidates – sourcing students or job seekers interested in work‑study programmes.
- Screening – interviewing applicants to ensure they meet official government criteria (age, educational background, etc.).
- Matching with Employers – locating companies that need apprentices and sending them the best profiles.
- Handling Paperwork – managing the complex administrative steps and ensuring contracts are signed once a company decides to hire.
In short, they bridge the gap between apprentices and employers, making the journey smoother for everyone.
The Bottleneck: Manual Data Entry
Before contacting us, the team used notebooks and spreadsheets. We built a complete recruitment pipeline for them based on the Odoo Community Recruitment module and extended it with custom modules to match their specific workflow.
The new system let the company track everything in one place:
- Database of applicants and companies
- Recruitment stages
- Appointments
- Automated Mail/SMS notifications
- Calendar integration
- Digital contract signatures
The solution was a success, but one major pain point remained: Data entry. Recruiters still had to find profiles and manually enter them into the pipeline before they could start working. The business owner was frustrated—recruiters were spending hours on manual entry instead of hunting for talent.
We decided to automate this using AI.
Designing the Automation Workflow
Our first idea was to build an API so third parties could send data directly to Odoo, but the sources weren’t ready for that. Instead, we agreed to receive all applicant CVs via email (simple messages with a PDF attachment). Once the dedicated mailbox was set up, we designed the following workflow:
- Read Emails – log in to the email provider and fetch unread messages.
- Extract Attachment – download the attached CV (usually a PDF).
- OCR Processing – perform Optical Character Recognition to extract raw text.
- AI Parsing – use an LLM to transform the raw text into a structured JSON format.
- Odoo Integration – use Odoo XML‑RPC to create a record in the recruitment module and attach the original PDF for reference.
- Assignment – automatically assign the lead to an available recruiter.

Iteration 1 – Tesseract + ChatGPT
The first solution was a microservice that combined Tesseract for OCR with the ChatGPT API for the LLM logic.

It worked fine for a couple of months and the client was happy, but technical issues soon appeared:
- Tesseract struggled with certain CV layouts, especially scanned documents.
- It consumed too much RAM on our VPS, preventing the high‑accuracy performance we needed.
Iteration 2 – LlamaParse for Better OCR
To address Tesseract’s weaknesses, we replaced it with the cloud service LlamaParse.

- LlamaParse handles a wider variety of PDF layouts and reduces memory usage.
- Accuracy improved dramatically, cutting the number of manual corrections needed.
Iteration 3 – Gemini Pro Vision (Current Solution)
The latest version swaps the ChatGPT API for Google Gemini Pro Vision. Gemini’s multimodal capabilities let us send the PDF directly to the model, which then extracts both the raw text and the structured JSON in a single request.
Key advantages
| Feature | Gemini Pro Vision | Previous Stack |
|---|---|---|
| Multimodal input (PDF) | ✅ | ❌ (PDF → OCR → text) |
| Single‑step extraction (text + JSON) | ✅ | ❌ (two separate calls) |
| Cost per 1 k tokens | $0.00035 | $0.0015 (ChatGPT) |
| Latency (average) | ~1.2 s | ~2.8 s |
| Accuracy on complex layouts | High | Moderate |
The new microservice flow:
- Read Emails – same as before.
- Download PDF – fetch the attachment.
- Gemini Pro Vision Call – send the PDF; receive raw text and a JSON payload.
- Odoo XML‑RPC – create the recruitment record and attach the original PDF.
- Assign Lead – automatically allocate to a recruiter.

Results & Takeaways
| Metric | Before Automation | After Gemini Integration |
|---|---|---|
| Manual data‑entry time per CV | ~4 min | < 30 s |
| Recruiter‑focused time | 30 % of day | 5 % of day |
| Accuracy (manual corrections) | 12 % of CVs needed fixes | < 2 % |
| Monthly cost (OCR + LLM) | $120 (Tesseract + ChatGPT) | $28 (Gemini) |
| System RAM usage | 1.2 GB (Tesseract) | 300 MB (Gemini) |
Key lessons
- Choose the right tool for the job – a modern multimodal LLM can replace a whole OCR + LLM pipeline.
- Cost matters – Gemini’s cheaper per‑token pricing made the solution sustainable for a small agency.
- Keep the architecture simple – fewer moving parts mean fewer points of failure and easier maintenance.
- GDPR compliance – all processing happens on secure servers, PDFs are stored only as long as needed, and personal data is never sent to third‑party services beyond Gemini (which is GDPR‑compliant).
Final Thoughts
By iterating from a DIY OCR + ChatGPT stack to a single‑call Gemini Pro Vision solution, we turned a painful manual process into an almost‑instant, cost‑effective pipeline. Recruiters can now focus on what they do best—matching talent with opportunities—while the system handles the heavy lifting of data extraction and entry.
If you’re dealing with similar CV‑parsing challenges, consider a multimodal LLM like Gemini. It can dramatically simplify your architecture, cut costs, and improve accuracy—all while staying GDPR‑friendly.
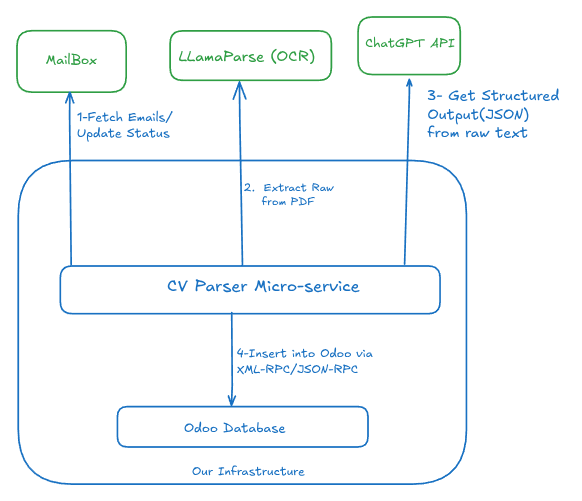
For context, **LlamaParse** is a specialized tool created by [LlamaIndex](https://www.llamaindex.ai/). It is designed specifically to *read* and parse complex documents (like PDFs) so AI models can understand them better.
Switching to LlamaParse was a great decision. It allowed us to process any CV format—scanned or digital—and obtain excellent results from the LLM. We ran this setup for a few months until we hit a new problem. This time, it wasn’t technical; it was financial. **ChatGPT was becoming too expensive.**
---
## Iteration 3: The DeepSeek Experiment
My employer started noticing that we were burning too much money on the ChatGPT API. At the same time, **[DeepSeek](https://api-docs.deepseek.com/)** was the new arrival in town, taking the internet by storm.
We evaluated DeepSeek for a while. It was actually very good. We migrated from ChatGPT to DeepSeek, and the results were immediate: the budget that lasted one week on ChatGPT now lasted a whole month on DeepSeek, with even better results.
[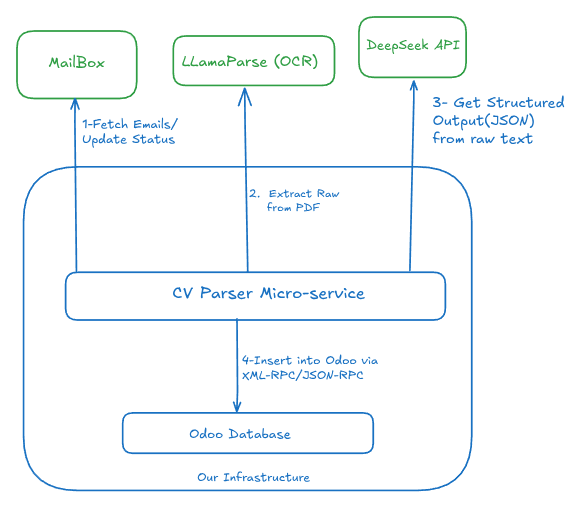](https://dev-to-uploads.s3.amazonaws.com/uploads/articles/mdbjkeq0ctqflppa8mcn.png)
Unfortunately, we used DeepSeek for only two months before hitting a legal wall: **[GDPR Compliance](https://gdpr-info.eu/)**.
DeepSeek was not compliant with European data‑protection laws (GDPR/RGPD). Since we were processing the personal data of French citizens, we simply could not continue using it.
---
## The Winning Setup: Google Gemini
We conducted a new migration, this time to **[Google Gemini](https://ai.google.dev/gemini-api/docs)**, looking for a balance of affordability, efficiency, and compliance.
The result was better than expected. Gemini is so capable that we were able to **drop LlamaParse entirely**. We now use Gemini for both the Vision/OCR part and the data extraction. The process is very simple: we send the prompt along with the PDF attachment directly to Gemini.
[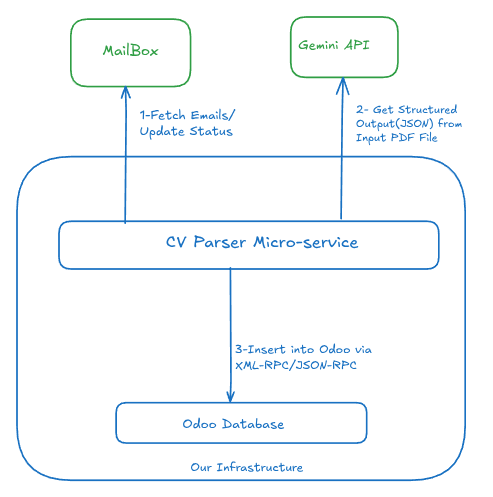](https://dev-to-uploads.s3.amazonaws.com/uploads/articles/ruhnz3ex4jeisre07rkn.png)
We haven’t touched the code for this microservice in over six months because it just works. Everything runs smoothly, and we are fully compliant with GDPR.
---
## Conclusion
This journey taught us that software development is about iteration. We started with a basic open‑source OCR, moved to specialized parsing tools, optimized for cost, and finally settled on a solution that offered the best mix of performance and compliance.
Today, the client’s recruiters no longer waste time on data entry. They focus on what they do best: finding the right job for the right student.