It's Time to Learn about Google TPUs in 2026
Source: Dev.to
Gemini, Veo, and Nano Banana are impressive, but they are just software.
Let’s talk about the hardware that makes them possible
Prerequisites
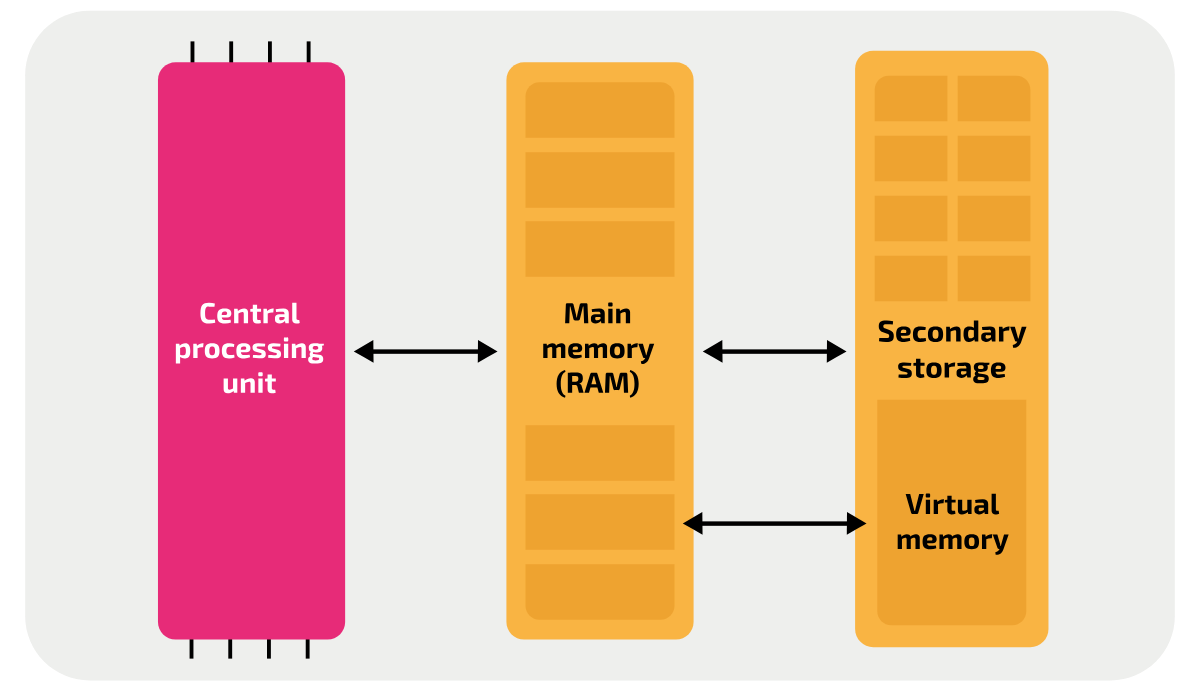
A computer only needs two things to function:
- Processor – The Brain
- RAM – The Workbench
When you open your cool AI IDE:
- The app data moves from the SSD to RAM.
- You do something.
- The Processor fetches instructions from RAM.
- It executes them and writes the result back to RAM.
- The Video Card (GPU) reads from RAM to show it on your screen.
A computer can work without a GPU (using a terminal), but it cannot work without a CPU & RAM.
PU – Processing Unit
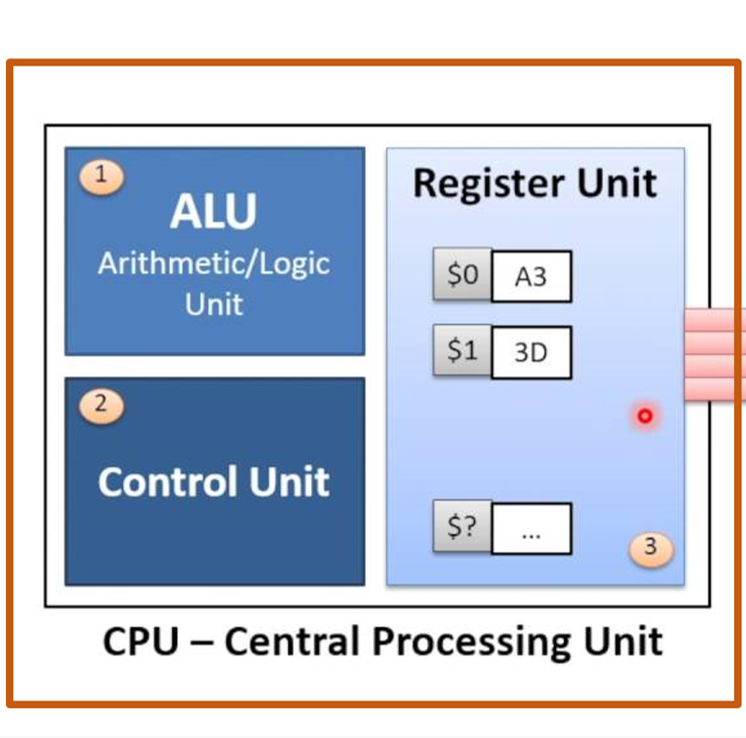
Processing Unit — an electronic circuit that manipulates data based on instructions. Physically, it is billions of transistors organized into logical gates (AND, OR, NOT).
Key Components
- ALU (Arithmetic Logic Unit) – The calculator. Performs math (addition, multiplication, …).
- Control Unit – The traffic cop. Directs data flow.
- Registers / Cache – Ultra‑fast internal memory (small, usually 10–200 KB) that keeps data close to the ALU.
The Three Types
| Type | Description | Architecture | Role | Motto |
|---|---|---|---|---|
| CPU (Central Processing Unit) | The Generalist | Few cores, very complex and smart | Serial processing – great for logic, operating systems, and sequential tasks | “I can do anything, but one thing at a time.” |
| GPU (Graphics Processing Unit) | The Parallelist | Thousands of small, simple cores | Parallel processing – designed for graphics and simple math on massive datasets simultaneously | “I can’t run an OS, but I can solve 10 000 easy math problems at once.” |
| ASIC (Application‑Specific Integrated Circuit) | The Specialist | Custom‑designed for a single task | Maximum efficiency for a specific algorithm | “I do one thing, but I do it faster and cheaper than anyone else.” |
History
In 2013, Jeff Dean and Jonathan Ross at Google recognized that CPUs and GPUs were structurally inefficient for the coming AI scale. A single metric made the problem clear: three minutes of daily Android Voice Search per user would force Google to double its data‑center capacity.
- While GPUs were faster than CPUs, they still carried architectural baggage that made them energy‑inefficient for AI.
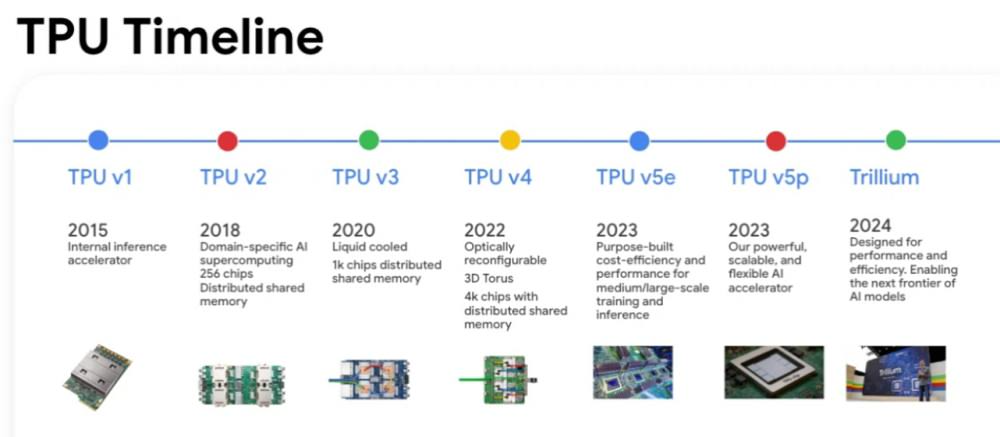
- Google therefore built its own custom silicon (ASIC). Fifteen months later, the TPU (Tensor Processing Unit) was born.
TPU vs GPU
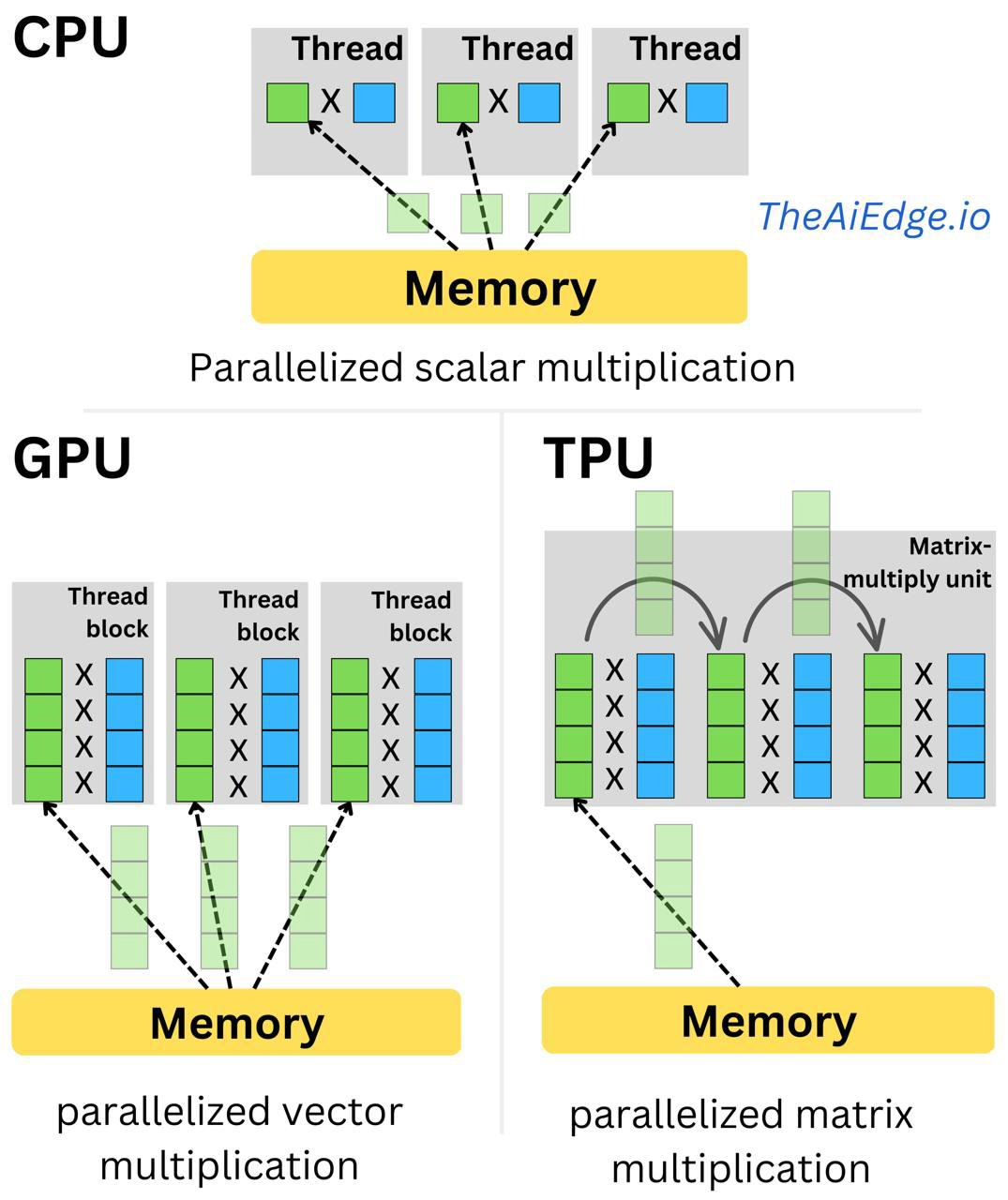
The main bottleneck in AI computing is memory access. Moving data is expensive and slow.
The Classical Approach (GPU/CPU)
- Read Number A from memory into a register.
- Read Number B from memory into a register.
- ALU multiplies A × B.
- Write the result back to memory.
The chip spends more time moving data than doing math.
The TPU Approach (Systolic Array)
- Data loads from memory once.
- It flows into the first row of ALUs.
- Each ALU performs the math and passes the result directly to its neighbor in the next cycle, without writing intermediate results back to memory.
- Data moves in a rhythmic wave (like a heart’s systole) through the entire array.
This yields extremely high throughput for matrix multiplication (the core of AI) with drastically lower power consumption.
Impact
If you want to build an AI startup today, you usually pay NVIDIA—you can buy their chips or rent them from almost any provider.
Google’s model is cloud‑based. You can’t buy a TPU to put in your … (text truncated in original source).
# Background
Google keeps its TPUs in its own data centers and rents access exclusively through [Google Cloud TPU](https://cloud.google.com/tpu).
This allows Google to control the entire stack and avoid the “NVIDIA Tax.”
- In 2024, **Apple** released a [technical paper](https://arxiv.org/pdf/2407.21075) revealing that *Apple Intelligence* was trained on TPUs, bypassing NVIDIA entirely.
- Top AI models like **Claude** (Anthropic), **Midjourney**, and **Character.ai** rely heavily on Google because they offer better performance‑per‑dollar for massive Transformer models.Background
Google keeps its TPUs in its own data centers and rents access exclusively through Google Cloud TPU.
This allows Google to control the entire stack and avoid the “NVIDIA Tax.”
- In 2024, Apple released a technical paper revealing that Apple Intelligence was trained on TPUs, bypassing NVIDIA entirely.
- Top AI models like Claude (Anthropic), Midjourney, and Character.ai rely heavily on Google because they offer better performance‑per‑dollar for massive Transformer models.
Future
Google’s success with Gemini, Nano Banana, and Veo speaks for itself. The industry has realized that general‑purpose hardware is not sustainable for AGI scale, so now everyone is trying to copy Google’s homework:
- Microsoft is building Maia.
- Amazon is building Trainium.
- Meta is building MTIA.
However, the TPU ecosystem does not guarantee a Google monopoly or the downfall of NVIDIA:
- Google is a competitor. For many tech giants, using Google Cloud means helping a rival perfect its own AI models.
- NVIDIA is universal and too deeply entrenched in the industry infrastructure to be replaced easily.
Apple
I wrote the previous part of the article right after the release of Gemini 3. Now Apple has partnered with Google for its AI, which confirms my arguments. Apple realized it could not close this gap in time, so it is letting Google handle AI operations while it focuses on selling hardware.
Many say this is a defeat for Apple, but I would argue it’s a win‑win situation:
- Apple integrates the current best AI into its devices, and Google generates revenue.
- The deal is valued at $1 billion, suggesting it may be a temporary solution or a bridge while Apple continues training its own models.
- Notably, Apple has not ended its partnership with OpenAI, but you never know…
Sources
- Apple‑Google AI partnership announcement: CNBC
- Joint statement from Google and Apple: Google Blog
- Apple‑OpenAI partnership: OpenAI
