Flexora: Flexible Low-Rank Adaptation for Large Language Models
Published: (January 13, 2026 at 05:22 PM EST)
3 min read
Source: Dev.to
Source: Dev.to
Vấn đề hiện tại
- Bối cảnh: Việc tinh chỉnh (fine‑tuning) các mô hình ngôn ngữ lớn (LLM) tốn rất nhiều tài nguyên. Phương pháp LoRA (Low‑Rank Adaptation) ra đời để giải quyết vấn đề này bằng cách đóng băng mô hình gốc và chỉ huấn luyện một lượng nhỏ tham số phụ.
- Hạn chế của LoRA: Mặc dù hiệu quả, LoRA thường gặp vấn đề overfitting (mô hình học vẹt, kết quả tốt trên tập huấn luyện nhưng kém trên thực tế). Các phương pháp khắc phục hiện tại thường phải chỉnh tay thủ công hoặc thiếu linh hoạt giữa các tác vụ khác nhau.
Giải pháp: Flexora
Các tác giả đề xuất Flexora, một phương pháp mới giúp tự động chọn ra các lớp (layer) quan trọng nhất trong mô hình để tinh chỉnh, thay vì tinh chỉnh toàn bộ hoặc chọn ngẫu nhiên.
Cơ chế hoạt động (3 giai đoạn)
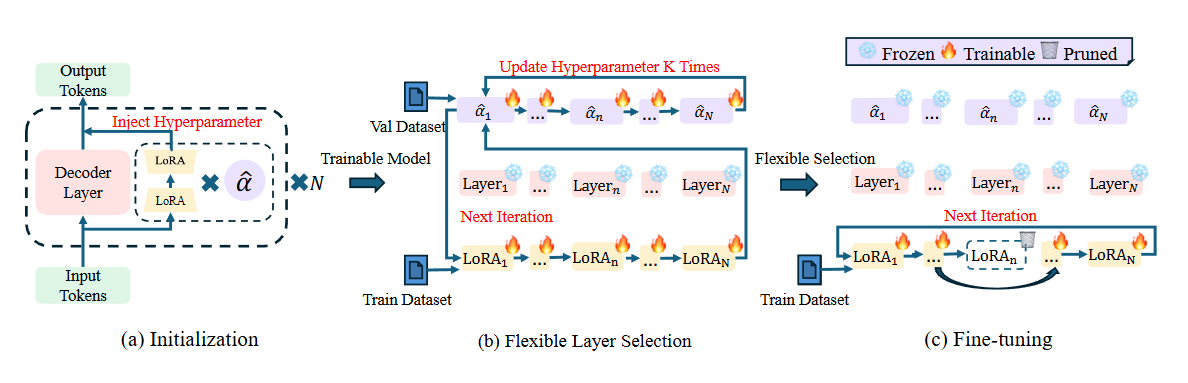
Flexora coi việc chọn lớp là một bài toán tối ưu hóa siêu tham số (Hyperparameter Optimization – HPO). Quy trình gồm 3 bước:
- Giai đoạn khởi tạo – Gắn thêm một tham số trọng số (gọi là vô hướng $\alpha$) vào các module LoRA của từng lớp trong mô hình.
- Giai đoạn chọn lớp linh hoạt (Flexible Selection)
- Sử dụng một tập dữ liệu kiểm thử nhỏ (validation set) để huấn luyện các trọng số $\alpha$ này bằng kỹ thuật Unrolled Differentiation.
- Hệ thống sẽ tự động học xem lớp nào đóng góp nhiều nhất cho kết quả đầu ra.
- Các lớp có điểm số cao sẽ được giữ lại, lớp điểm thấp bị loại bỏ.
- Giai đoạn tinh chỉnh (Fine‑tuning) – Chỉ huấn luyện các lớp quan trọng đã được chọn ở bước 2; các lớp khác bị đóng băng. Điều này giúp tiết kiệm tài nguyên và tập trung vào những phần quan trọng nhất.
Kết quả và hiệu quả
- Hiệu suất cao hơn: Flexora đánh bại LoRA gốc và các phương pháp khác trên nhiều bài kiểm tra (Hellaswag, PIQA, RACE, v.v.).
- Giảm overfitting: Bằng cách loại bỏ các tham số thừa, mô hình tổng quát hóa tốt hơn (học hiểu thay vì học vẹt).
- Tiết kiệm tham số: Flexora thường chỉ cần dùng khoảng 50 % số lượng tham số so với LoRA nhưng lại cho kết quả tốt hơn.
- Khả năng mở rộng: Phương pháp này hoạt động tốt trên nhiều mô hình khác nhau (Llama, Mistral, ChatGLM, v.v.).
Nghiên cứu chỉ ra rằng
- Không phải lớp nào trong LLM cũng quan trọng như nhau đối với một tác vụ cụ thể.
- Flexora thường có xu hướng chọn các lớp đầu tiên (input) và lớp cuối cùng (output) để tinh chỉnh, vì đây là nơi chứa nhiều thông tin quan trọng nhất liên quan đến dữ liệu đầu vào và kết quả đầu ra.
Tóm lại: Flexora là phiên bản nâng cấp thông minh của LoRA, biết tự động “chọn lọc tinh hoa” (chọn đúng lớp cần học) để giúp mô hình thông minh hơn, nhẹ hơn và tránh học vẹt.